








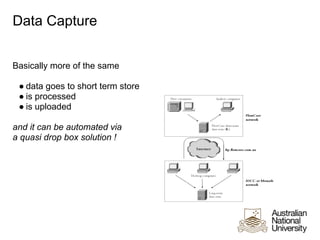







The ANU Data Commons project aims to build a research data management solution and data repository at ANU. It will allow researchers to store, find, share, search, and reuse their research data. The repository will use standard technologies like Fedora Commons and enable self-deposit of data and metadata. It seeks to address the increasing need to make research data available to support publications, as required by funders like the US NSF. When complete, it will help researchers securely deposit existing and new data to ensure preservation and reuse.
















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)

