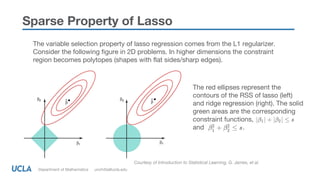
The document discusses the importance of interpretability in machine learning (ML) and sparse linear models, defining interpretability as the degree to which a human can explain a model's decisions. It presents various levels of interpretability and methods like lasso regression that promote sparsity and enhance model explainability, particularly in complex datasets. Additionally, it highlights regulatory and ethical considerations surrounding model transparency and the necessity for explainable automated decisions.










![[Emnlp] what is glo ve part i - towards data science](https://cdn.slidesharecdn.com/ss_thumbnails/emnlpwhatisgloveparti-towardsdatascience-200228052054-thumbnail.jpg?width=640&height=640&fit=bounds)














































