Download as PDF, PPTX





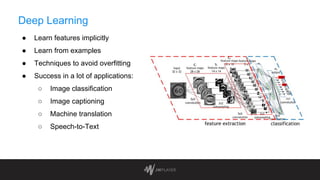
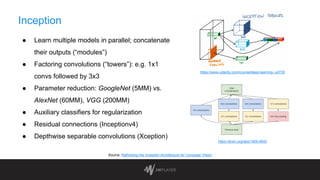




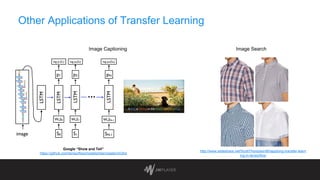




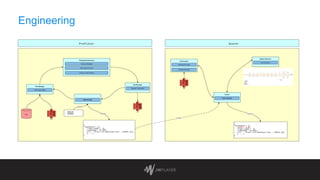
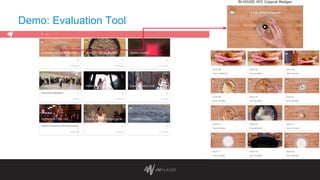
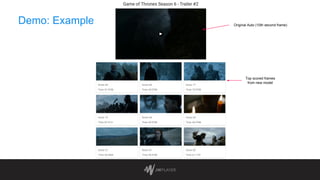



The document discusses intelligent thumbnail selection strategies used by JW Player, focusing on the importance of thumbnails in video engagement. It outlines the differences between manual and automated thumbnail creation, the role of deep learning techniques for feature extraction, and the use of transfer learning for improving thumbnail selection. Key findings include that manual thumbnails generally outperform automated ones, and recommendations are provided for refining automated selection methods.


































