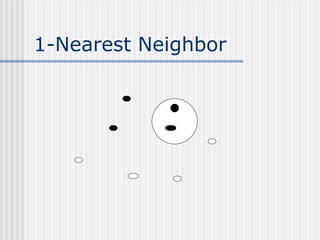
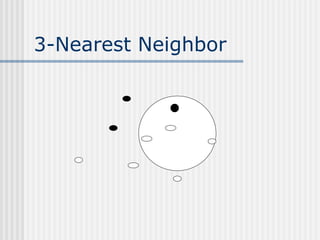
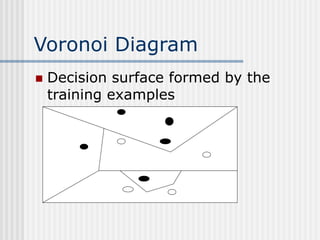
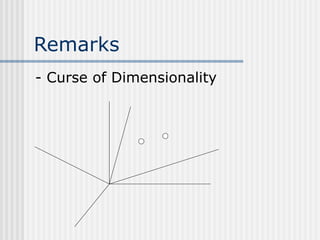
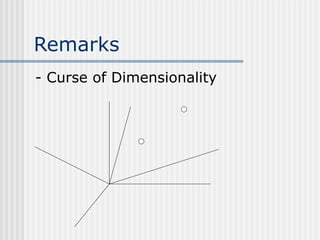
The document discusses k-nearest neighbor learning as an instance-based, or lazy, learning method where classification is delayed until a new instance is encountered. It highlights various aspects such as distance measurement, feature representation, and weighted regression, along with the advantages and drawbacks of this method, including its effectiveness in noisy data and the challenges posed by the curse of dimensionality. Additionally, it mentions the use of efficient memory indexing techniques like kd-trees to manage stored training examples.














































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











