Downloaded 11 times
![Inferring Versioned
Schemas from NoSQL
Databases and its
Applications
ER’15
Stockholm, October 2015
[{ ”id”: ”90234 af”, ”value”: { ”author”: ”Diego Sevilla Ruiz”,
”e-mail”: ”dsevilla@um.es”,
”institution”: ”U. of Murcia”}},
{ ”id”: ”a243bb5”, ”value”: { ”author”: ”Severino Feliciano Morales”,
”e-mail”: ”severino.feliciano@um.es”,
”institution”: ”U. of Murcia”}},
{ ”id”: ”096705d”, ”value”: { ”author”: ”Jesús García Molina”,
”e-mail”: ”jmolina@um.es”,
”institution”: ”U. of Murcia”}}]](https://image.slidesharecdn.com/pr-151023172749-lva1-app6891/85/Inferring-Versioned-Schemas-from-NoSQL-Databases-and-its-Applications-1-320.jpg)
![Inferring Versioned
Schemas from NoSQL
Databases and its
Applications
ER’15
Stockholm, October 2015
[{ ”id”: ”90234 af”, ”value”: { ”author”: ”Diego Sevilla Ruiz”,
”e-mail”: ”dsevilla@um.es”,
”institution”: ”U. of Murcia”}},
{ ”id”: ”a243bb5”, ”value”: { ”author”: ”Severino Feliciano Morales”,
”e-mail”: ”severino.feliciano@um.es”,
”institution”: ”U. of Murcia”}},
{ ”id”: ”096705d”, ”value”: { ”author”: ”Jesús García Molina”,
”e-mail”: ”jmolina@um.es”,
”institution”: ”U. of Murcia”}}]](https://image.slidesharecdn.com/pr-151023172749-lva1-app6891/75/Inferring-Versioned-Schemas-from-NoSQL-Databases-and-its-Applications-1-2048.jpg)




![{
”rows”:[
{
”content”:{
”chapters”:33,
”pages”:527
},
”authors”:[
{
”company”:{
”country”:”USA”,
”name”:”IBM”
},
”name”:”Grady Booch”,
”_id”:”210”
},
{
”company”:{
”country”:”USA”,
”name”:”IBM”
},
”name”:”James Rumbaugh”,
”_id”:”310”
},
{
”country”:”USA”,
”company”:”Ivar Jacobson Consulting”,
”name”:”Ivar Jacobson”,
”_id”:”410”
}],
”type”:”book”,
”year”:2013,
”publisher_id”:”345679”,
”title”:”The Unified Modeling Language”,
”_id”:”1”
},
{
”discipline”:”software engineering”,
”issn”:[
”0098 -5589”,
”1939 -3520”
],
”name”:”IEEE Trans. on Software Engineering”,
”type”:”journal”,
”_id”:”11”
},
{
”name”:”Automated Software Engineering”,
”issn”:[
”0928 -8910”,
”1573 -7535”
],
”discipline”:”software engineering”,
”type”:”journal”,
”_id”:”12”,
”number”:10515
},
{
”city”:”Barcelona”,
”name”:”Omega”,
”type”:”publisher”,
”_id”:”123451”
},
{
”type”:”publisher”,
”city”:”Newton”,
”name”:”O’Reilly Media”,
”_id”:”928672”
},
{
”type”:”book”,
”author”:{
”_id”:”101”,
”name”:”Bradley Holt”,
”company”:{
”country”:”USA”,
”name”:”IBM Cloudant”,
}
},
”title”:”Writing and Querying MapReduce Views in
CouchDB”,
”publisher_id”:”928672”,
”_id”:”2”
},
{
”name”:”Addison -Wesley”,
”type”:”publisher”,
”_id”:”345679”
},
{
”type”:”publisher”,
”journals”:[
”11”,
”12”
],
”name”:”IEEE Publications”,
”_id”:”907863”
}]}](https://image.slidesharecdn.com/pr-151023172749-lva1-app6891/85/Inferring-Versioned-Schemas-from-NoSQL-Databases-and-its-Applications-6-320.jpg)

![Schema & Entity Versions Description
Entity Publisher {
Version 1 {
name: String
city: String
}
Version 2 {
name: String
}
Version 3 {
name: String
journal[+]: [Ref]->[Journal] (opposite=False)
}
}
Entity Journal {
Version 1 {
issn: Tuple [String, String]
name: String
discipline: String
}
Version 2 {
issn: Tuple [String, String]
name: String
discipline: String
number: int
}
}
Entity Book {
Version 1 {
title: String
year: int
publisher[1]: [Ref]->[Publisher] (opossite=False)
content[1]: [Aggregate]Content1
author[+]: [Aggregate]Author1
}
Version 2 {
title: String
publisher[1]: [Ref]->[Publisher] (opossite=False)
author[1]: [Aggregate]Author1
}
}
Entity Author {
Version 1 {
name: String
company[1]: [Aggregate]Company
}
Version 2 {
country: String
company: String
name: String
}
}
Entity Company {
Version 1 {
name: String
country: String
}
}
Entity Content {
Version 1 {
chapters: int
pages: int
}
}
(a) (b)
[1..1] company
[1..1] publisher[1..1] content[1..*] authors
[1..*] journals](https://image.slidesharecdn.com/pr-151023172749-lva1-app6891/85/Inferring-Versioned-Schemas-from-NoSQL-Databases-and-its-Applications-8-320.jpg)



![function isOfExactTypeBook_2(obj) {
if (! (”type” in obj)) {
return false;
}
if (obj[type] !== ”Book”) {
return false;
}
if (! (”title” in obj)) {
return false;
}
if (! (”author” in obj)) {
return false;
}
if (”publisher” in obj) {
return false;
}
if (”content” in obj) {
return false;
}
if (”year” in obj) {
return false;
}
return true;
}
Generated using a Model-
to-Text transformation
from an instance of the
previous Type Discrimina-
tion Metamodel](https://image.slidesharecdn.com/pr-151023172749-lva1-app6891/85/Inferring-Versioned-Schemas-from-NoSQL-Databases-and-its-Applications-16-320.jpg)

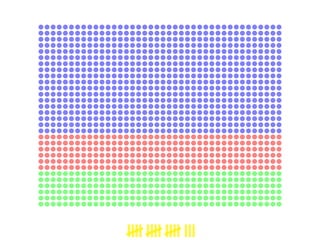
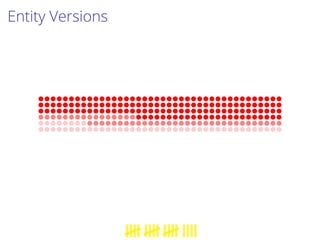
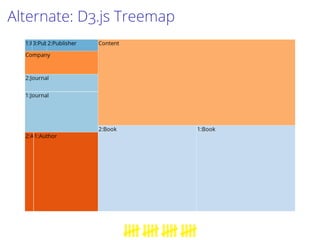
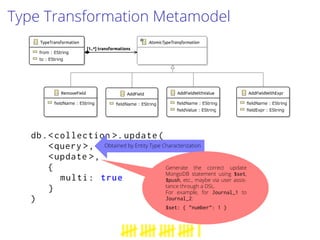



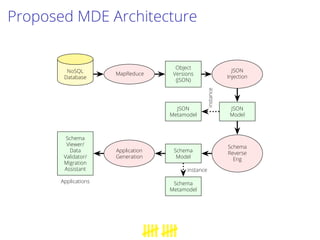
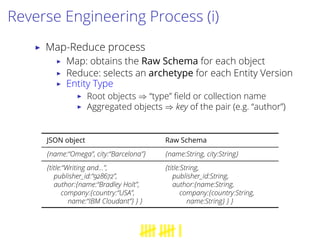
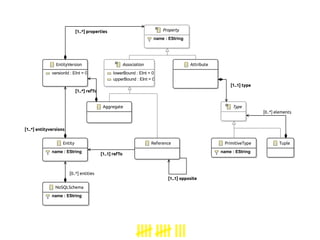
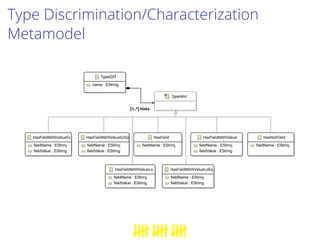
This document proposes a process to infer schemas from NoSQL databases by analyzing object versions. It involves using map-reduce to extract raw schemas from objects and group them by entity and version. Relationships like references and aggregations are also modeled. This schema model can then be used to automatically generate applications like data validation, visualization, and migration tools. Future work includes building a toolset for NoSQL data engineering tasks and enhancing the inferred schema with additional type information.






















































































