Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
RyuichiKanoh
PPTX, PDF
2,027 views
ICLR2020読み会 (neural-tangents)
https://exawizards.connpass.com/event/176947/
Science
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Downloaded 50 times
1
/ 27
2
/ 27
3
/ 27
4
/ 27
5
/ 27
6
/ 27
7
/ 27
8
/ 27
9
/ 27
10
/ 27
11
/ 27
12
/ 27
13
/ 27
14
/ 27
15
/ 27
16
/ 27
17
/ 27
18
/ 27
19
/ 27
20
/ 27
21
/ 27
22
/ 27
23
/ 27
24
/ 27
25
/ 27
26
/ 27
27
/ 27
More Related Content
PDF
HiPPO/S4解説
by
Morpho, Inc.
PDF
【DL輪読会】Vision-Centric BEV Perception: A Survey
by
Deep Learning JP
PDF
[DL輪読会]A Simple Unified Framework for Detecting Out-of-Distribution Samples a...
by
Deep Learning JP
PPTX
Triplet Loss 徹底解説
by
tancoro
PDF
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
PPTX
G社のNMT論文を読んでみた
by
Toshiaki Nakazawa
PDF
Visualizing Data Using t-SNE
by
Tomoki Hayashi
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
HiPPO/S4解説
by
Morpho, Inc.
【DL輪読会】Vision-Centric BEV Perception: A Survey
by
Deep Learning JP
[DL輪読会]A Simple Unified Framework for Detecting Out-of-Distribution Samples a...
by
Deep Learning JP
Triplet Loss 徹底解説
by
tancoro
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
G社のNMT論文を読んでみた
by
Toshiaki Nakazawa
Visualizing Data Using t-SNE
by
Tomoki Hayashi
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
What's hot
PDF
MLP-Mixer: An all-MLP Architecture for Vision
by
Kazuyuki Miyazawa
PDF
3D CNNによる人物行動認識の動向
by
Kensho Hara
PDF
MLP-Mixer: An all-MLP Architecture for Vision
by
harmonylab
PDF
はじめてのパターン認識 第8章 サポートベクトルマシン
by
Motoya Wakiyama
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PPTX
Noisy Labels と戦う深層学習
by
Plot Hong
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
PPTX
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
PPTX
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
PDF
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
KEY
FDRの使い方 (Kashiwa.R #3)
by
Haruka Ozaki
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
PDF
ベイジアンディープニューラルネット
by
Yuta Kashino
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
PDF
[DL輪読会]Disentangling by Factorising
by
Deep Learning JP
MLP-Mixer: An all-MLP Architecture for Vision
by
Kazuyuki Miyazawa
3D CNNによる人物行動認識の動向
by
Kensho Hara
MLP-Mixer: An all-MLP Architecture for Vision
by
harmonylab
はじめてのパターン認識 第8章 サポートベクトルマシン
by
Motoya Wakiyama
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
Noisy Labels と戦う深層学習
by
Plot Hong
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
FDRの使い方 (Kashiwa.R #3)
by
Haruka Ozaki
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
ベイジアンディープニューラルネット
by
Yuta Kashino
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
[DL輪読会]Disentangling by Factorising
by
Deep Learning JP
Similar to ICLR2020読み会 (neural-tangents)
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
by
marsee101
PPTX
強化学習初心者が強化学習でニューラルネットワークの設計を自動化してみたい
by
Takuma Wakamori
PPTX
深層学習とTensorFlow入門
by
tak9029
PPTX
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
PDF
[DL輪読会]Measuring abstract reasoning in neural networks
by
Deep Learning JP
PDF
Neural Network と Universality について
by
Kato Yuzuru
PPTX
AI入門「第4回:ディープラーニングの中身を覗いて、育ちを観察する」
by
fukuoka.ex
PDF
「TensorFlow Tutorialの数学的背景」 クイックツアー(パート1)
by
Etsuji Nakai
PPTX
Coursera "Neural Networks"
by
hayashizaki takaaki
PDF
RNN-based Translation Models (Japanese)
by
NAIST Machine Translation Study Group
PDF
Scikit-learn and TensorFlow Chap-14 RNN (v1.1)
by
孝好 飯塚
PDF
あめとむちで知能を作る!? ーニューラルネットを使ったEnd to-End強化学習と「思考」の創発に向けたカオスNN強化学習ー
by
Katsunari Shibata
PDF
AIがAIを生み出す?
by
Daiki Tsuchiya
PDF
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio...
by
Takahiro Kubo
PPTX
【macOSにも対応】AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」
by
fukuoka.ex
PPTX
AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」【旧版】※新版あります
by
fukuoka.ex
PDF
Neural network presentation for LT
by
Ryosuke Suzuki
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
深層学習の数理
by
Taiji Suzuki
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
by
marsee101
強化学習初心者が強化学習でニューラルネットワークの設計を自動化してみたい
by
Takuma Wakamori
深層学習とTensorFlow入門
by
tak9029
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
[DL輪読会]Measuring abstract reasoning in neural networks
by
Deep Learning JP
Neural Network と Universality について
by
Kato Yuzuru
AI入門「第4回:ディープラーニングの中身を覗いて、育ちを観察する」
by
fukuoka.ex
「TensorFlow Tutorialの数学的背景」 クイックツアー(パート1)
by
Etsuji Nakai
Coursera "Neural Networks"
by
hayashizaki takaaki
RNN-based Translation Models (Japanese)
by
NAIST Machine Translation Study Group
Scikit-learn and TensorFlow Chap-14 RNN (v1.1)
by
孝好 飯塚
あめとむちで知能を作る!? ーニューラルネットを使ったEnd to-End強化学習と「思考」の創発に向けたカオスNN強化学習ー
by
Katsunari Shibata
AIがAIを生み出す?
by
Daiki Tsuchiya
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio...
by
Takahiro Kubo
【macOSにも対応】AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」
by
fukuoka.ex
AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」【旧版】※新版あります
by
fukuoka.ex
Neural network presentation for LT
by
Ryosuke Suzuki
Deep Learningの基礎と応用
by
Seiya Tokui
ICLR2020読み会 (neural-tangents)
1.
Neural Tangents: Fast and
Easy Infinite Neural Networks in Python Ryuichi Kanoh (Mobility Technologies*DeNAより出向) Twitter ICLR2020オンライン読み会 無限の幅を持つニューラルネットワークを実装する話
2.
Introduction 2
3.
Over-parameterization 近年のニューラルネットワークは、(パラメータ数)>>(学習データ数) • CIFAR10: 5万枚の訓練画像 •
ResNet152: 約6000万個のパラメータ • 正則化やData Augmentationなしでも、ある程度うまくいく 疑問 (パラメータ数) >> (学習データ数)の学習が、なぜうまくいくのか? 3
4.
経験的に得られている事実 局所解にはまらずに学習は大域収束する パラメータ数が増え続けても汎化する 論文リンク (ICLR2020) 4
5.
(興味を持ってもらうための) 関連実験紹介 [1] 学習データを増やすほど性能が劣化するレンジが存在 • 二重降下の山の位置がデータ数に依存することに起因 •
あなたもこの罠にはまっているかも? 論文リンク (ICLR2020) 5
6.
(興味を持ってもらうための) 関連実験紹介 [2] アンサンブルに適切なパラメータ数は、二重効果の山を少し超えたところ • シンプルな定式化ではこの効果は現れず、よくわかっていない
論文リンク (ICML2020) 論文リンク 増やしすぎると劣化 6
7.
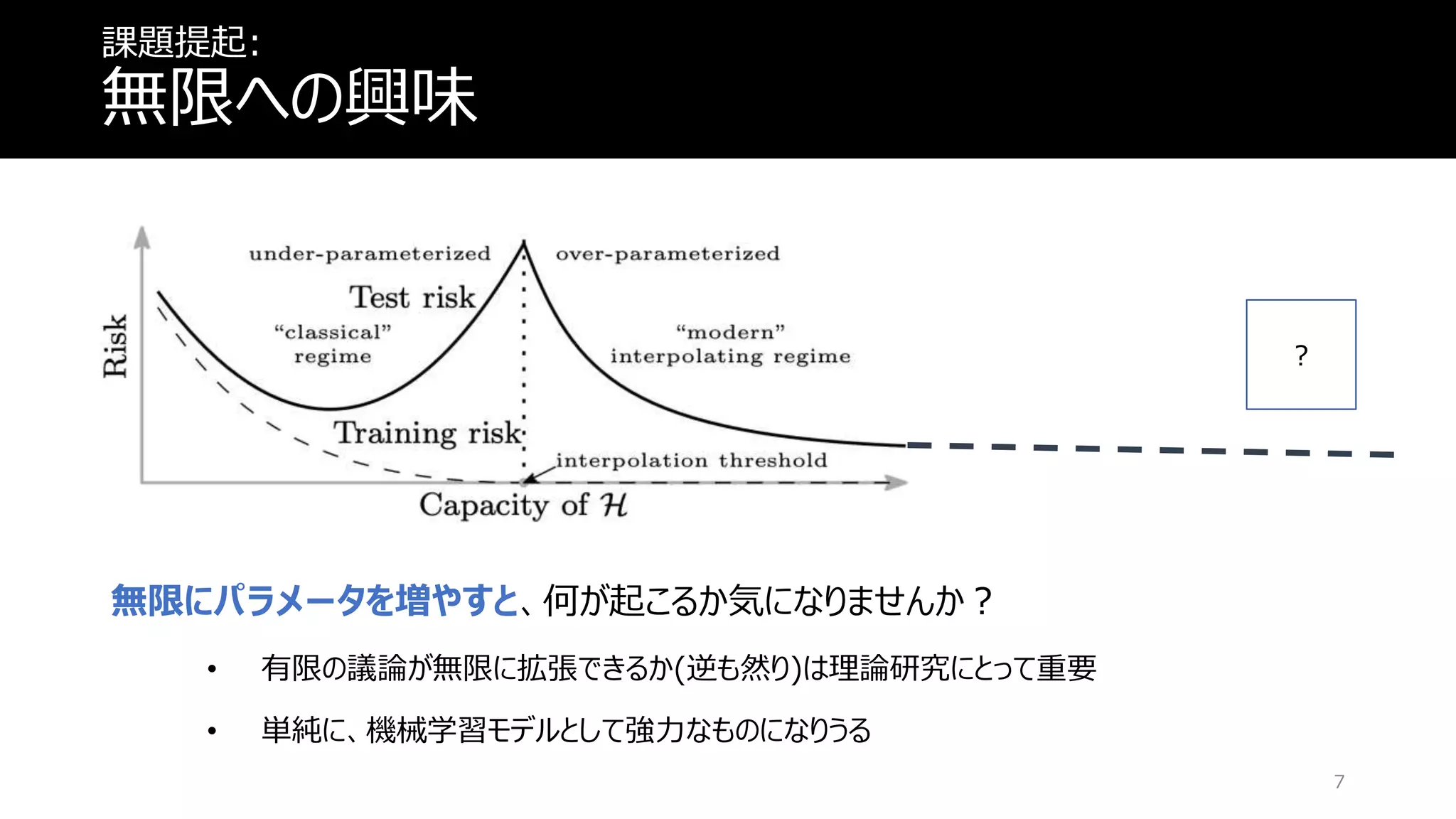
課題提起: 無限への興味 無限にパラメータを増やすと、何が起こるか気になりませんか? • 有限の議論が無限に拡張できるか(逆も然り)は理論研究にとって重要 • 単純に、機械学習モデルとして強力なものになりうる ? 7
8.
無限幅ネットワークに対するアプローチ Neural Tangent Kernel
[定式化] パラメータ(w)空間での学習の定式化 *勾配法 (w: パラメータ, η: 学習率, L: 誤差関数) 式変形 η→0 *誤差関数は二乗誤差とする 関数(y)空間での学習の定式化 Neural Tangent Kernel (NTK) 8
9.
無限幅ネットワークに対するアプローチ Neural Tangent Kernel
[不変性] 隠れ層の幅が広いと、ひとつひとつの重みの変化が微小でも推論結果は大きく変化する • 実験的/理論的に、幅が広いと重みと は変化しなくなることが示されてきた 論文リンク (NeurIPS 2019) (証明が気になる方はこちら) 幅と共にNTKの変化が小さく 9
10.
無限幅ネットワークに対するアプローチ Neural Tangent Kernel
[解の獲得] が時間依存しないとすると、上式は単純な微分方程式となり、解を解析的に得られる NTK 幅が無限の場合は時間依存しない 10
11.
NTKの活用にあたっての障壁 の計算方法は、モデルの構成ごとに変わる • 例えば、L層の(全結合層+活性化)のモデルは、以下のように定式化できる • これらをパラメータで微分し、積をとることでNTKは計算できる f:
pre-activation g: post-activation W: NNの重み σ: 活性化関数 cσ: 規格化定数 dh: h層目の幅 11
12.
NTKの活用にあたっての障壁 の計算方法は、モデルの構成ごとに変わる • 例えば、L層の(全結合層+活性化)のモデルは、以下のように定式化できる • これらをパラメータで微分し、積をとることでNTKは計算できる f:
pre-activation g: post-activation W: NNの重み σ: 活性化関数 cσ: 規格化定数 dh: h層目の幅 • 畳み込み層が入ったら? • Pooling層が入ったら? • グラフニューラルネットワークは? • 活性化関数が変わったら? • Skip Connectionを導入したら? • … • 初見での計算は厳しいのでキャッチアップが必要 • 具体的な計算が気になる方はこちら • Dense (NeurIPS 2018) • CNN, Pooling (NeurIPS 2019) • GNN (NeurIPS 2019) • などなど 12
13.
NTKの活用にあたっての障壁 の計算方法は、モデルの構成ごとに変わる • 例えば、L層の(全結合層+活性化)のモデルは、以下のように定式化できる • これらをパラメータで微分し、積をとることでNTKは計算できる f:
pre-activation g: post-activation W: NNの重み σ: 活性化関数 cσ: 規格化定数 dh: h層目の幅 • 畳み込み層が入ったら? • Pooling層が入ったら? • グラフニューラルネットワークは? • 活性化関数が変わったら? • Skip Connectionを導入したら? • … • 初見での計算は厳しいのでキャッチアップが必要 • 具体的な計算が気になる方はこちら • Dense (NeurIPS 2018) • CNN, Pooling (NeurIPS 2019) • GNN (NeurIPS 2019) • などなど 13 参入障壁が高い! 計算ミスや実装ミスが怖い… 使われる数学も難しい…
14.
ここまでのまとめ 無限の幅を持つモデルを調べることは面白そう • 有限の議論が無限まで拡張できるかどうか(逆も然り)は、理論的に事柄を示す際に重要な観点 • 単純に、機械学習モデルとして強力なものになりうる NTKなど、無限幅のモデルを扱う理論も整備されてきている •
それらを用いれば、理論解析と数値実験を交えながら議論が展開できそう • 中心極限定理や大数の法則が使えるので、かえって有限幅より議論しやすいこともある モデルを変えるたびに複雑な定式化を行ってNTKを実装するのは大変 • 先行研究がいくつも存在しているが、実装が各論文でバラバラで読み解くのや横展開が大変 • CUDA, numpy, pytorch… • NTKの計算は重いので、hardware-friendlyな形での実装を考える必要もある 14
15.
How to implement infinite
neural network 15
16.
neural-tangents neural-tangents (ICLR2020)というライブラリを使用すると簡単。 (pipで入る) •
JAXというGoogleのライブラリをラップしている • JAXは、numpyに自動微分とJITがくっついたようなもの。GPUやTPUでも動く • numpy-likeな記法で、低レベルな部分も自分で実装しやすいのが特徴らしい 16
17.
実装例 (NTKの獲得) JAXの中のstaxというモジュールをラップする形で使用されることが多い • モデルさえ定義すれば、モデル構造ごとに変わる面倒な設計は、全部ライブラリが内包してくれる 17 無限の幅を持つネットワークのカーネル関数 (Denseで定義している512というパラメータはこの関数に影響しない) 対応するNTKが格納された配列
18.
実装例 (NTKを使用した推論) カーネル関数とデータを渡せば、推論結果を得ることができる 18
19.
ドキュメント類 初見でも、きちんと情報やハンズオンが整備されているので、使いやすい ドキュメント • https://neural-tangents.readthedocs.io/en/latest/# Gitリポジトリ • https://github.com/google/neural-tangents Colab
Notebook • https://colab.research.google.com/github/google/neural- tangents/blob/master/notebooks/neural_tangents_cookbook.ipynb 19
20.
Experiments 20
21.
有限の幅を持つモデルとの比較 Wide-ResNetなど幅の広いモデルの挙動は、かなり近い振る舞いが模擬できている • tが大きくなるとズレ始めることにも注意 21 論文リンク (NeurIPS
2019)
22.
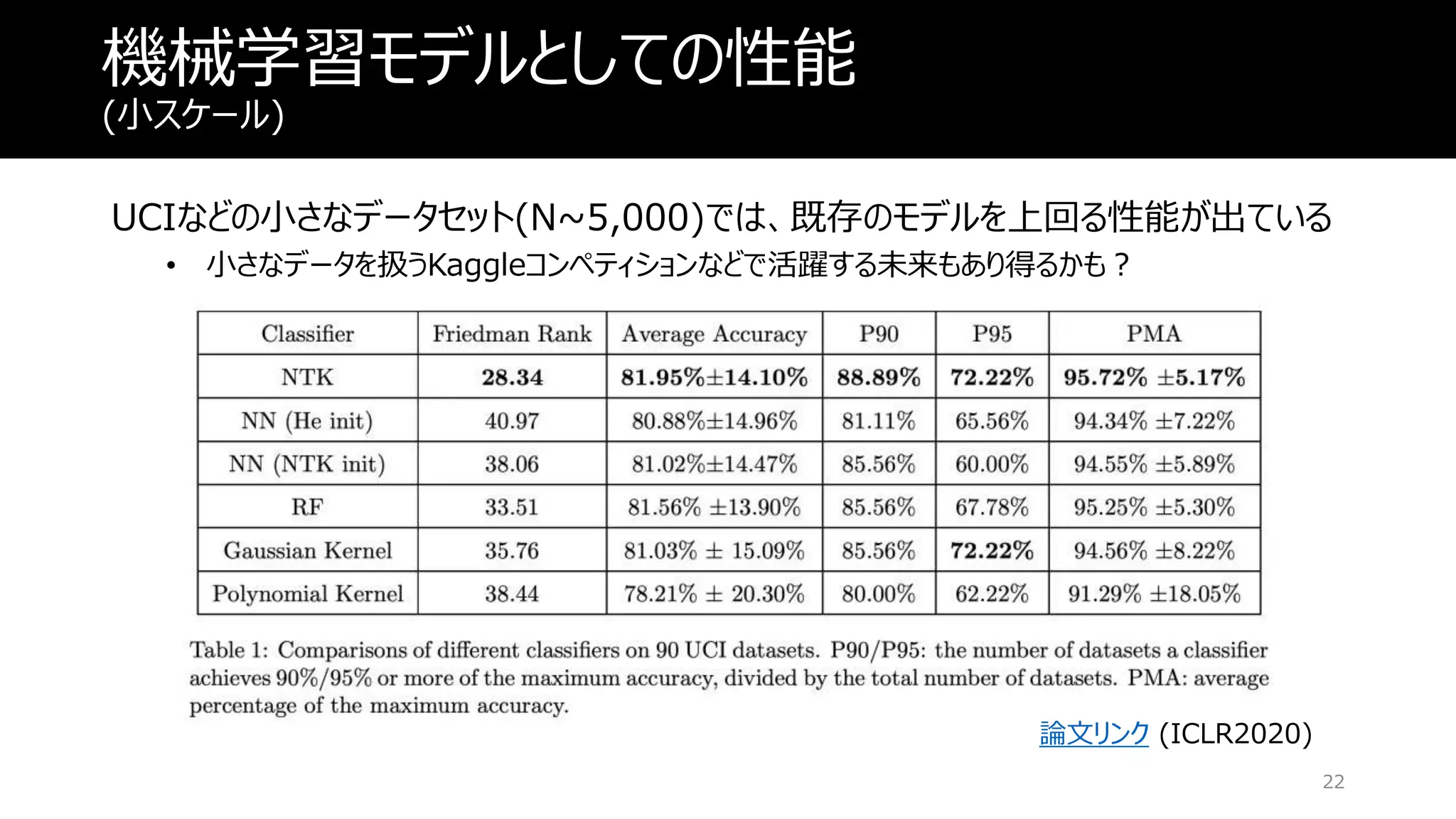
機械学習モデルとしての性能 (小スケール) UCIなどの小さなデータセット(N~5,000)では、既存のモデルを上回る性能が出ている • 小さなデータを扱うKaggleコンペティションなどで活躍する未来もあり得るかも? 22 論文リンク (ICLR2020)
23.
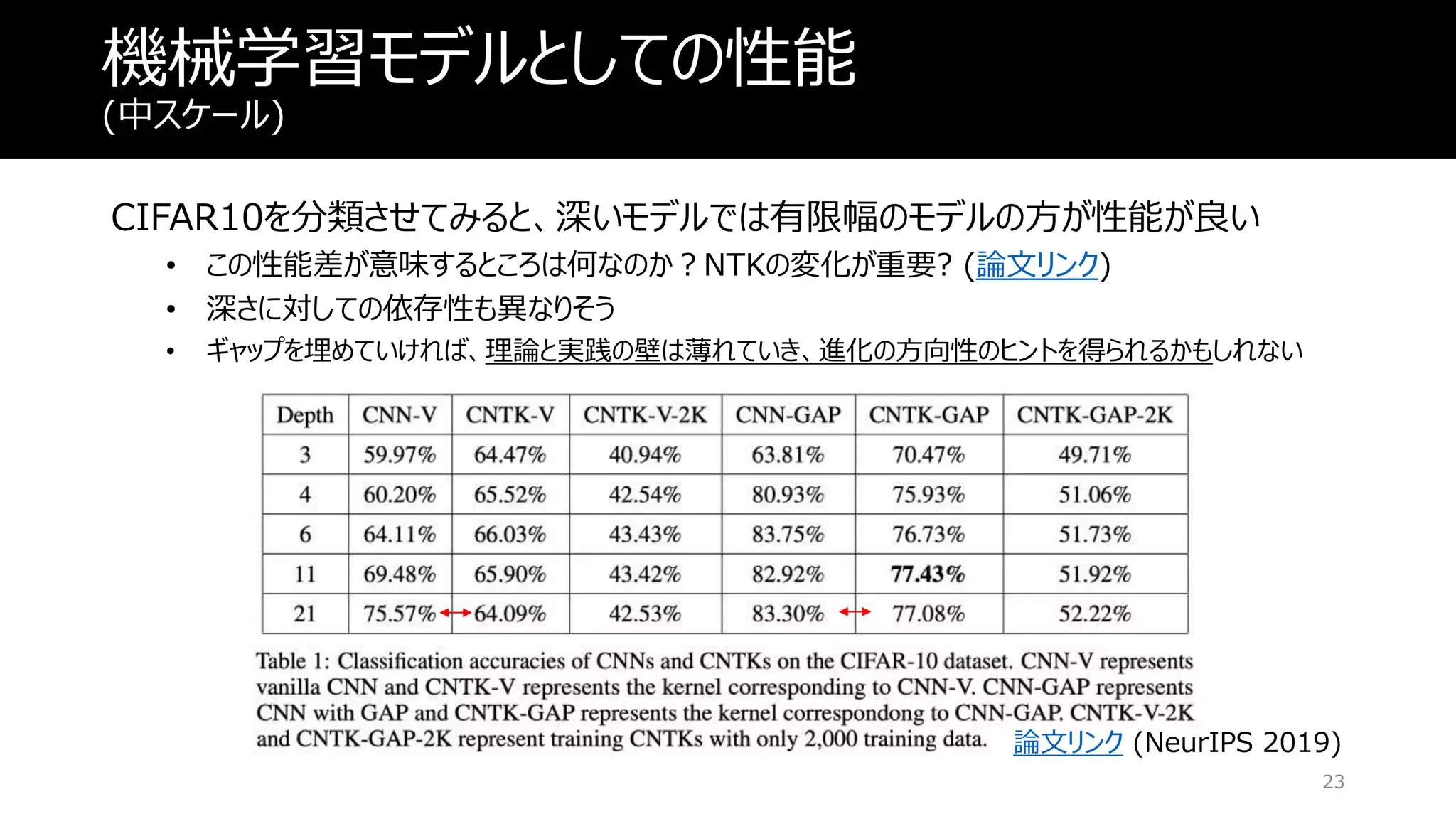
機械学習モデルとしての性能 (中スケール) CIFAR10を分類させてみると、深いモデルでは有限幅のモデルの方が性能が良い • この性能差が意味するところは何なのか?NTKの変化が重要? (論文リンク) •
深さに対しての依存性も異なりそう • ギャップを埋めていければ、理論と実践の壁は薄れていき、進化の方向性のヒントを得られるかもしれない 23 論文リンク (NeurIPS 2019)
24.
処理時間 24 ICLR2020プレゼン資料より引用 ImageNet規模の大スケールの対象は厳しい • 計算の高速化を考えることにも、大いに価値がある
25.
並列処理性能 ほぼ並列処理数に対して線形に処理時間が減っていっていく 25
26.
Summary 26
27.
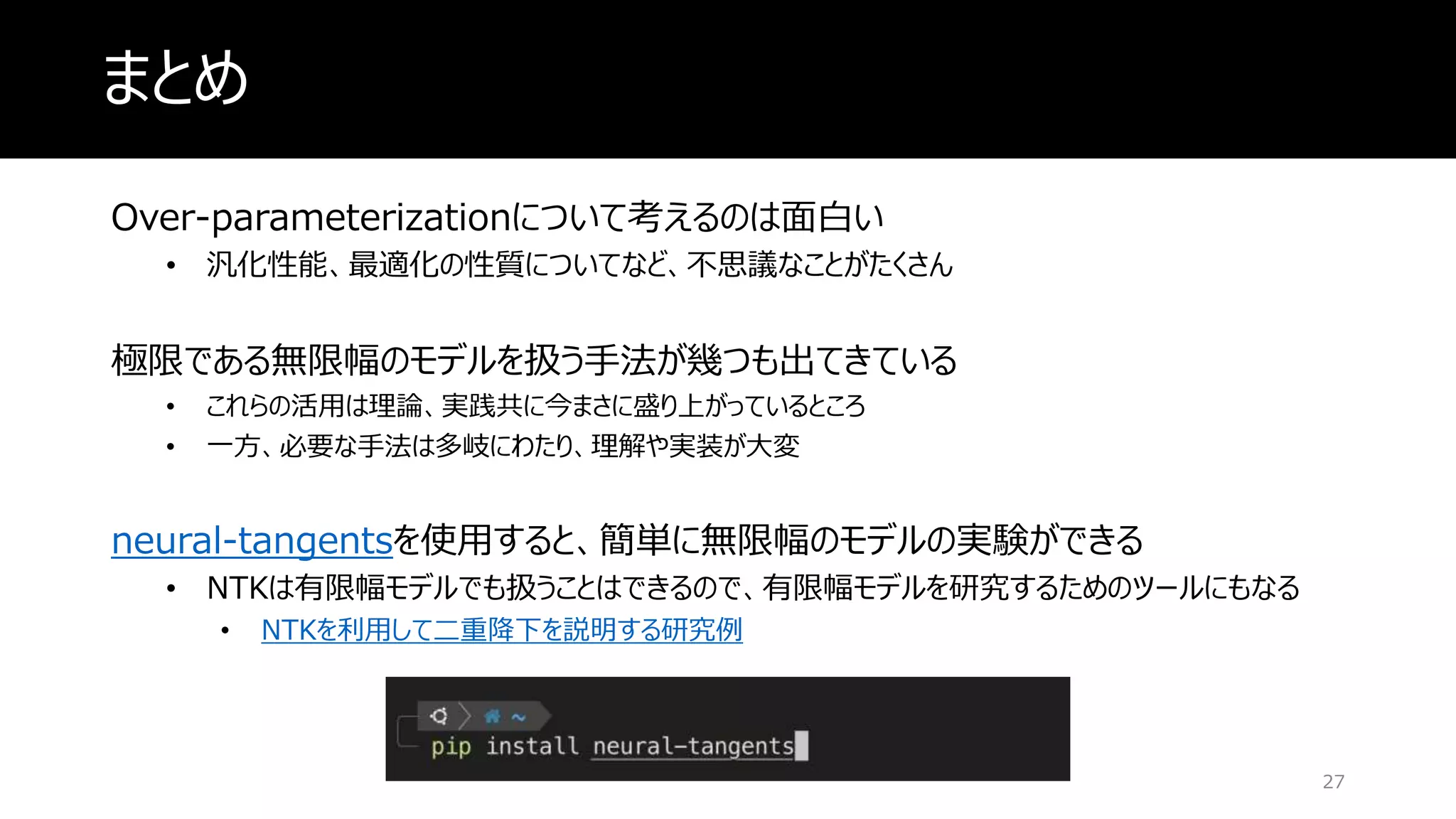
まとめ Over-parameterizationについて考えるのは面白い • 汎化性能、最適化の性質についてなど、不思議なことがたくさん 極限である無限幅のモデルを扱う手法が幾つも出てきている • これらの活用は理論、実践共に今まさに盛り上がっているところ •
一方、必要な手法は多岐にわたり、理解や実装が大変 neural-tangentsを使用すると、簡単に無限幅のモデルの実験ができる • NTKは有限幅モデルでも扱うことはできるので、有限幅モデルを研究するためのツールにもなる • NTKを利用して二重降下を説明する研究例 27
Download




![(興味を持ってもらうための)
関連実験紹介 [1]
学習データを増やすほど性能が劣化するレンジが存在
• 二重降下の山の位置がデータ数に依存することに起因
• あなたもこの罠にはまっているかも?
論文リンク (ICLR2020)
5](https://image.slidesharecdn.com/iclr-200613165224/75/ICLR2020-neural-tangents-5-2048.jpg)
![(興味を持ってもらうための)
関連実験紹介 [2]
アンサンブルに適切なパラメータ数は、二重効果の山を少し超えたところ
• シンプルな定式化ではこの効果は現れず、よくわかっていない 論文リンク (ICML2020)
論文リンク
増やしすぎると劣化
6](https://image.slidesharecdn.com/iclr-200613165224/75/ICLR2020-neural-tangents-6-2048.jpg)
![無限幅ネットワークに対するアプローチ
Neural Tangent Kernel [定式化]
パラメータ(w)空間での学習の定式化
*勾配法 (w: パラメータ, η: 学習率, L: 誤差関数)
式変形
η→0
*誤差関数は二乗誤差とする
関数(y)空間での学習の定式化
Neural Tangent Kernel (NTK)
8](https://image.slidesharecdn.com/iclr-200613165224/75/ICLR2020-neural-tangents-8-2048.jpg)
![無限幅ネットワークに対するアプローチ
Neural Tangent Kernel [不変性]
隠れ層の幅が広いと、ひとつひとつの重みの変化が微小でも推論結果は大きく変化する
• 実験的/理論的に、幅が広いと重みと は変化しなくなることが示されてきた
論文リンク (NeurIPS 2019)
(証明が気になる方はこちら)
幅と共にNTKの変化が小さく
9](https://image.slidesharecdn.com/iclr-200613165224/75/ICLR2020-neural-tangents-9-2048.jpg)
![無限幅ネットワークに対するアプローチ
Neural Tangent Kernel [解の獲得]
が時間依存しないとすると、上式は単純な微分方程式となり、解を解析的に得られる
NTK
幅が無限の場合は時間依存しない
10](https://image.slidesharecdn.com/iclr-200613165224/75/ICLR2020-neural-tangents-10-2048.jpg)















![[DL輪読会]A Simple Unified Framework for Detecting Out-of-Distribution Samples a...](https://cdn.slidesharecdn.com/ss_thumbnails/20181005misono2-181009052706-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Measuring abstract reasoning in neural networks](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi0727-180727002112-thumbnail.jpg?width=640&height=640&fit=bounds)












