Download as PDF, PPTX

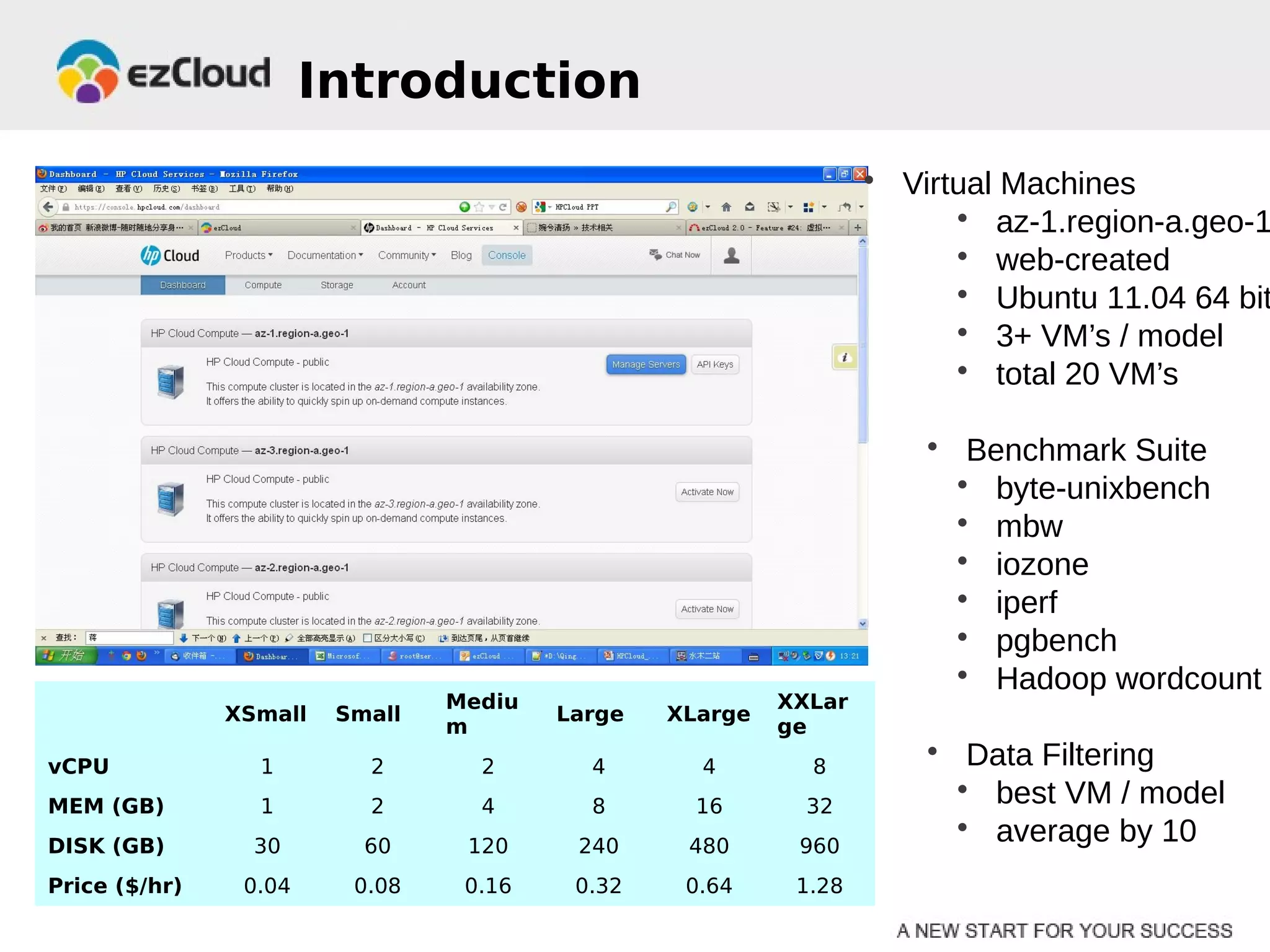
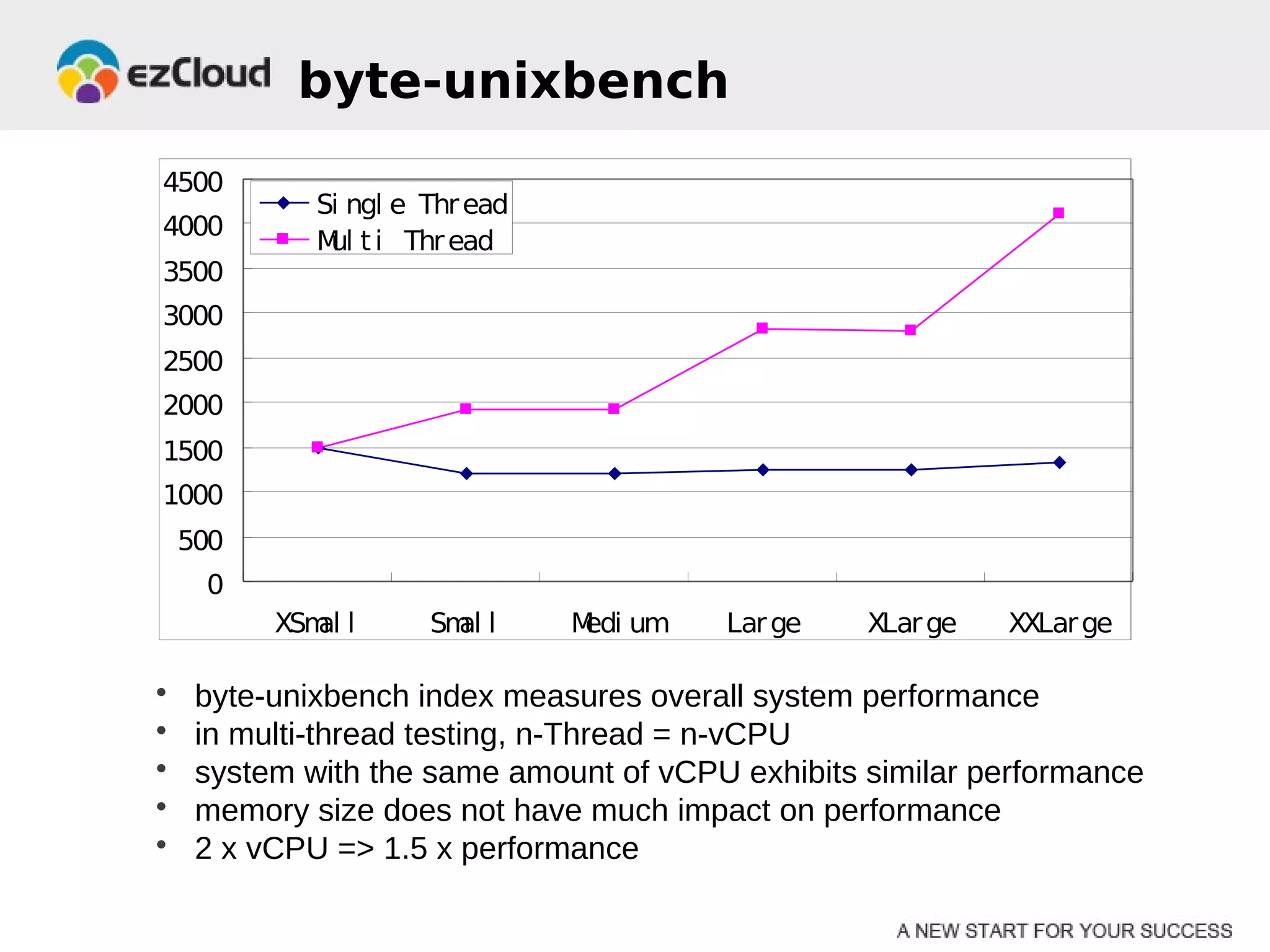
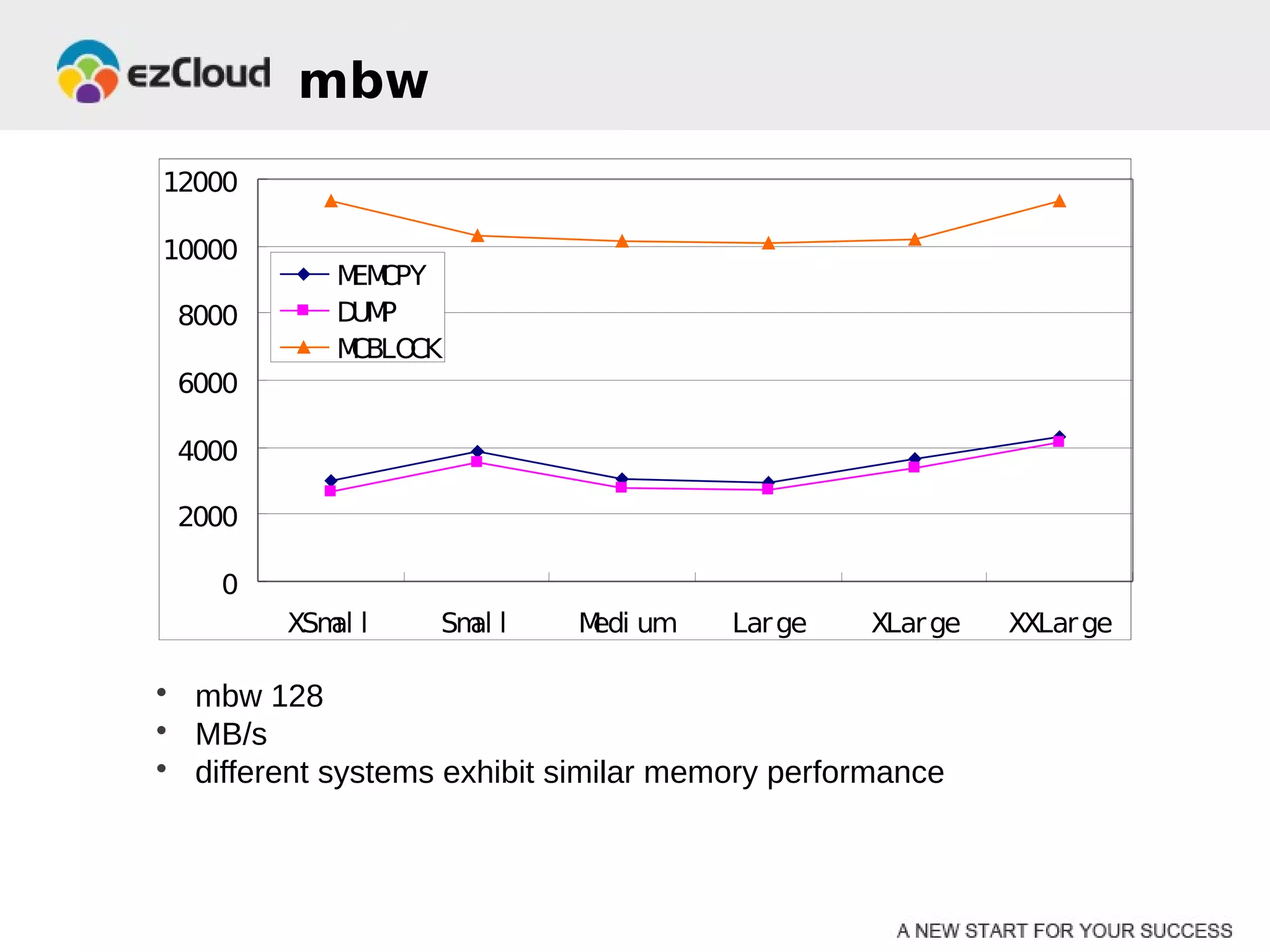
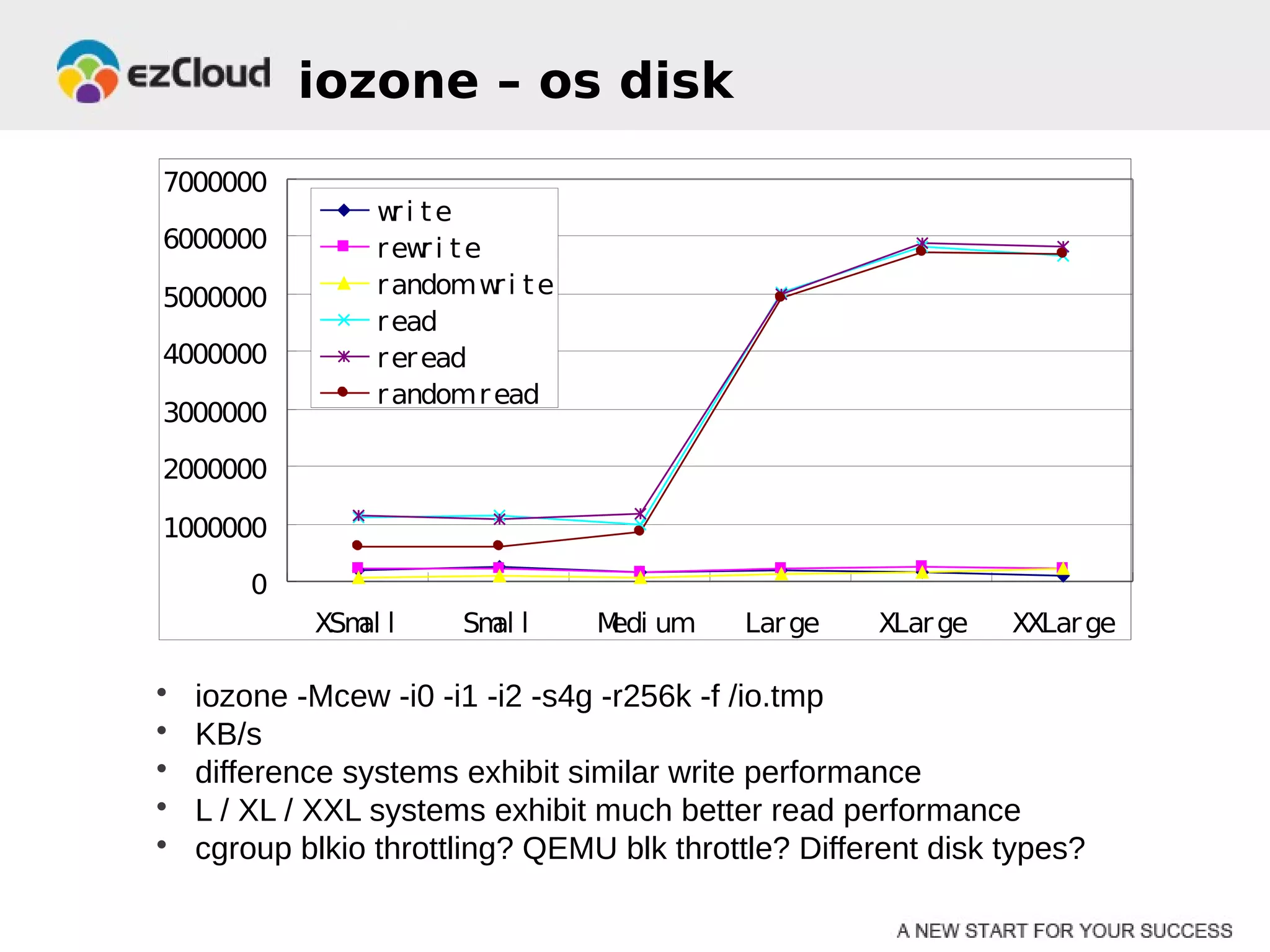
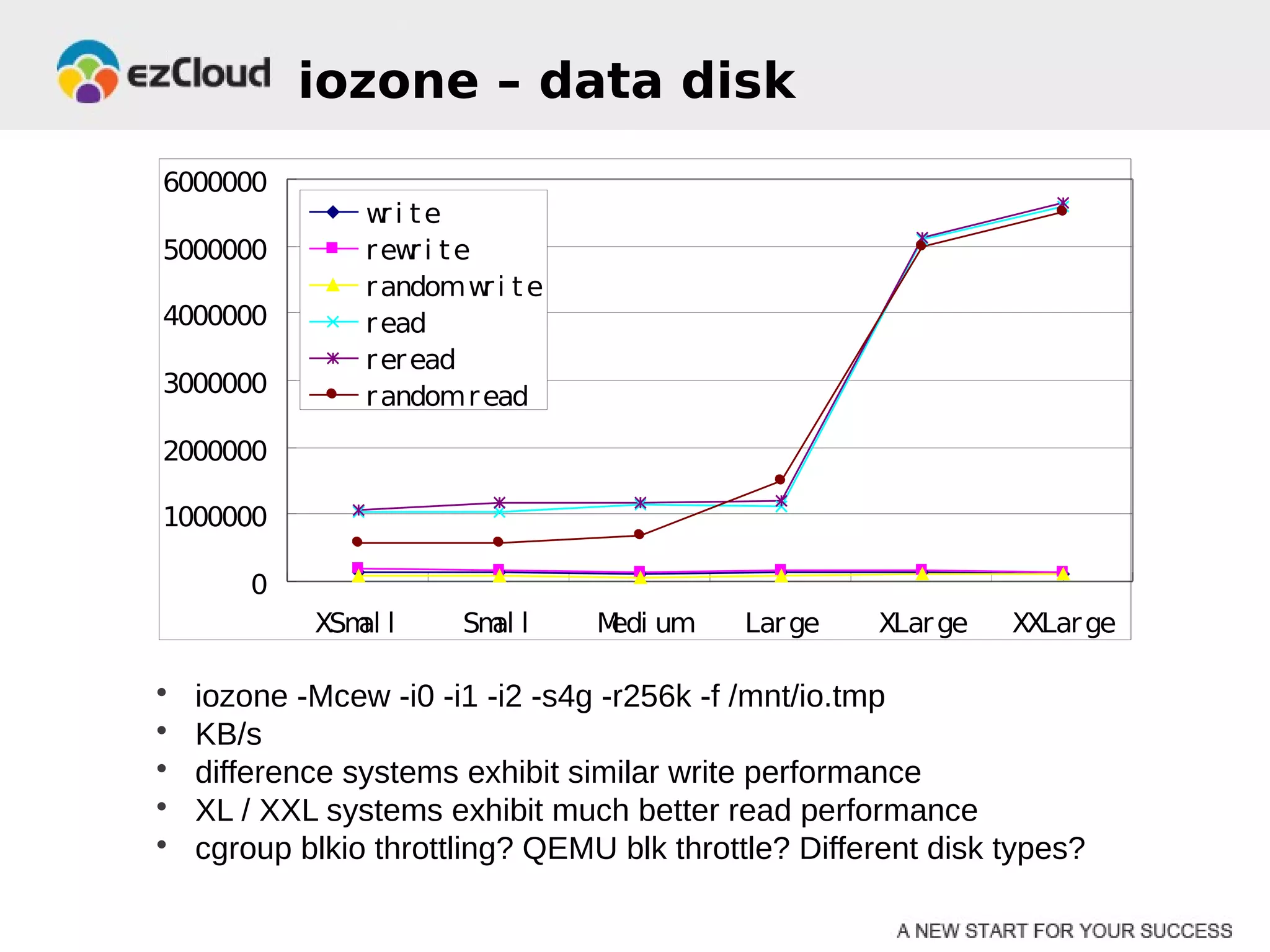

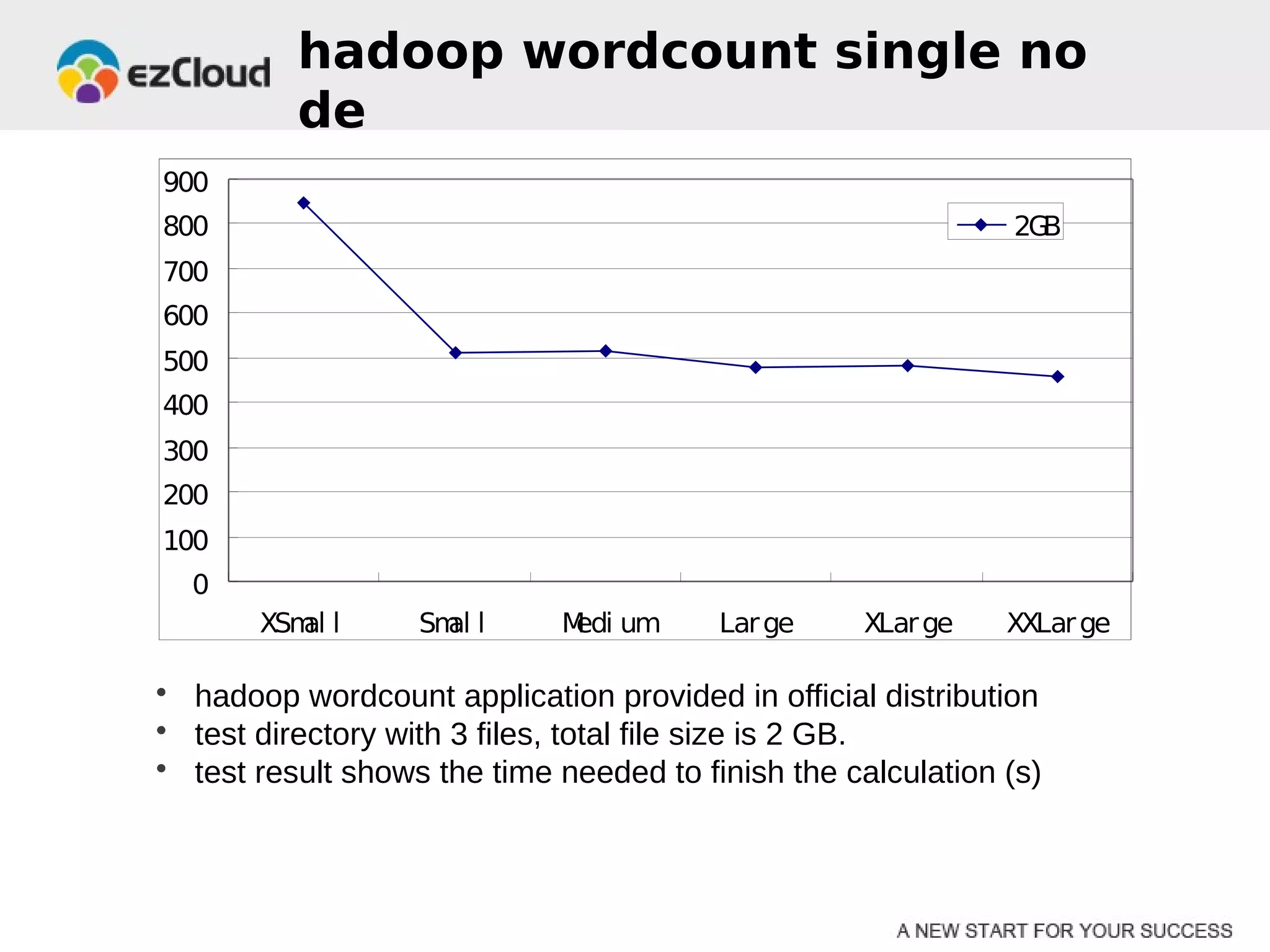
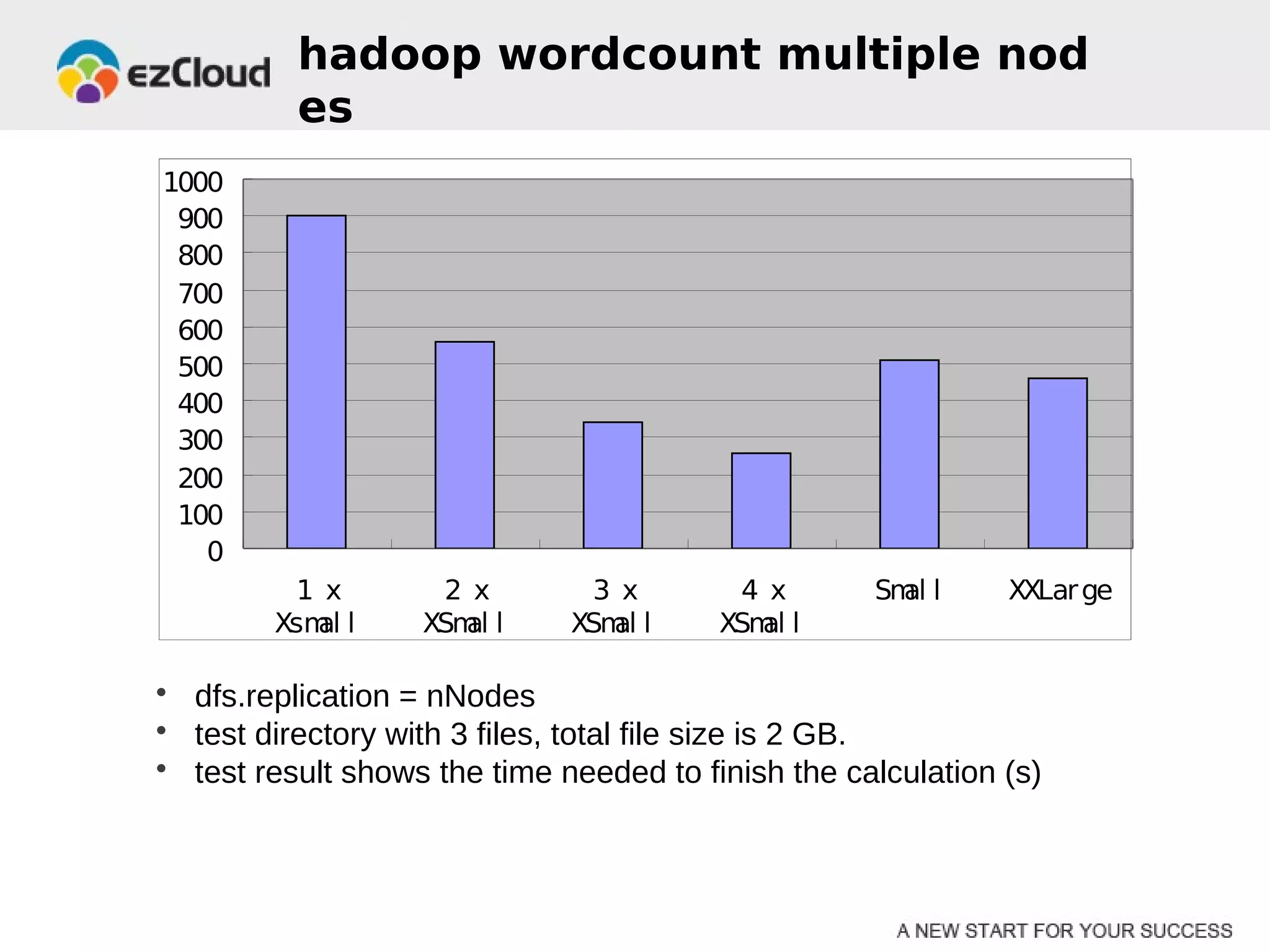
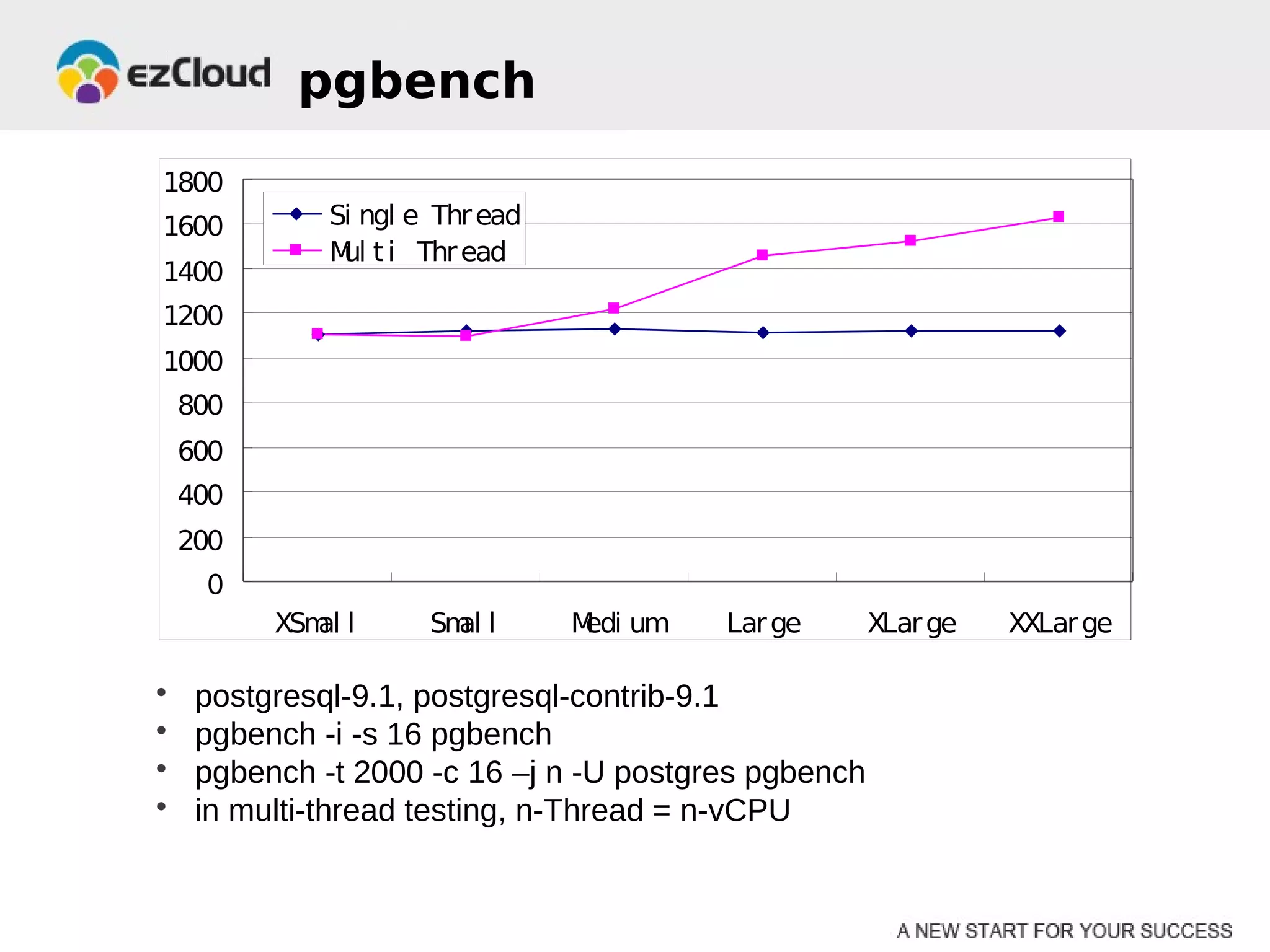
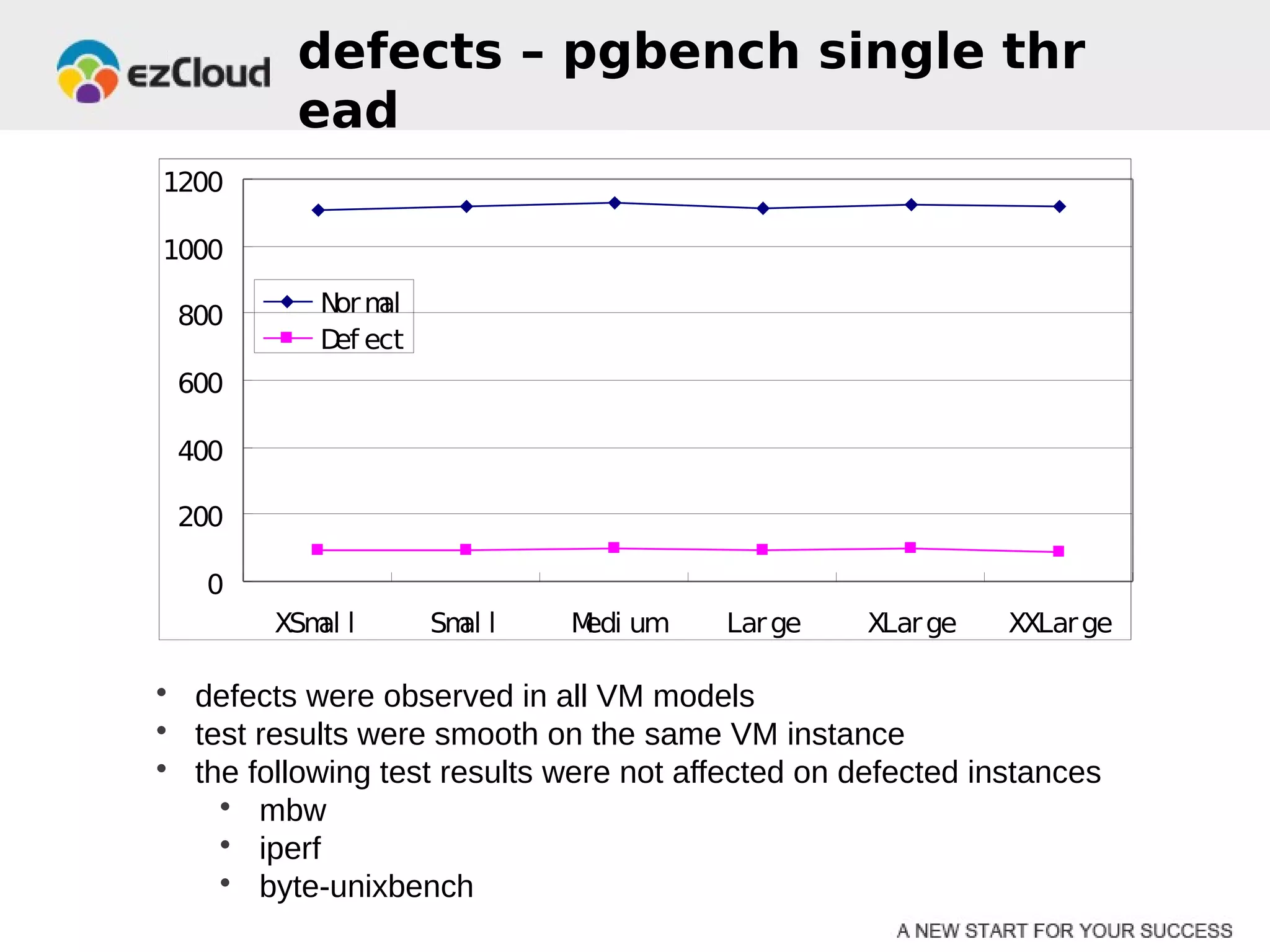
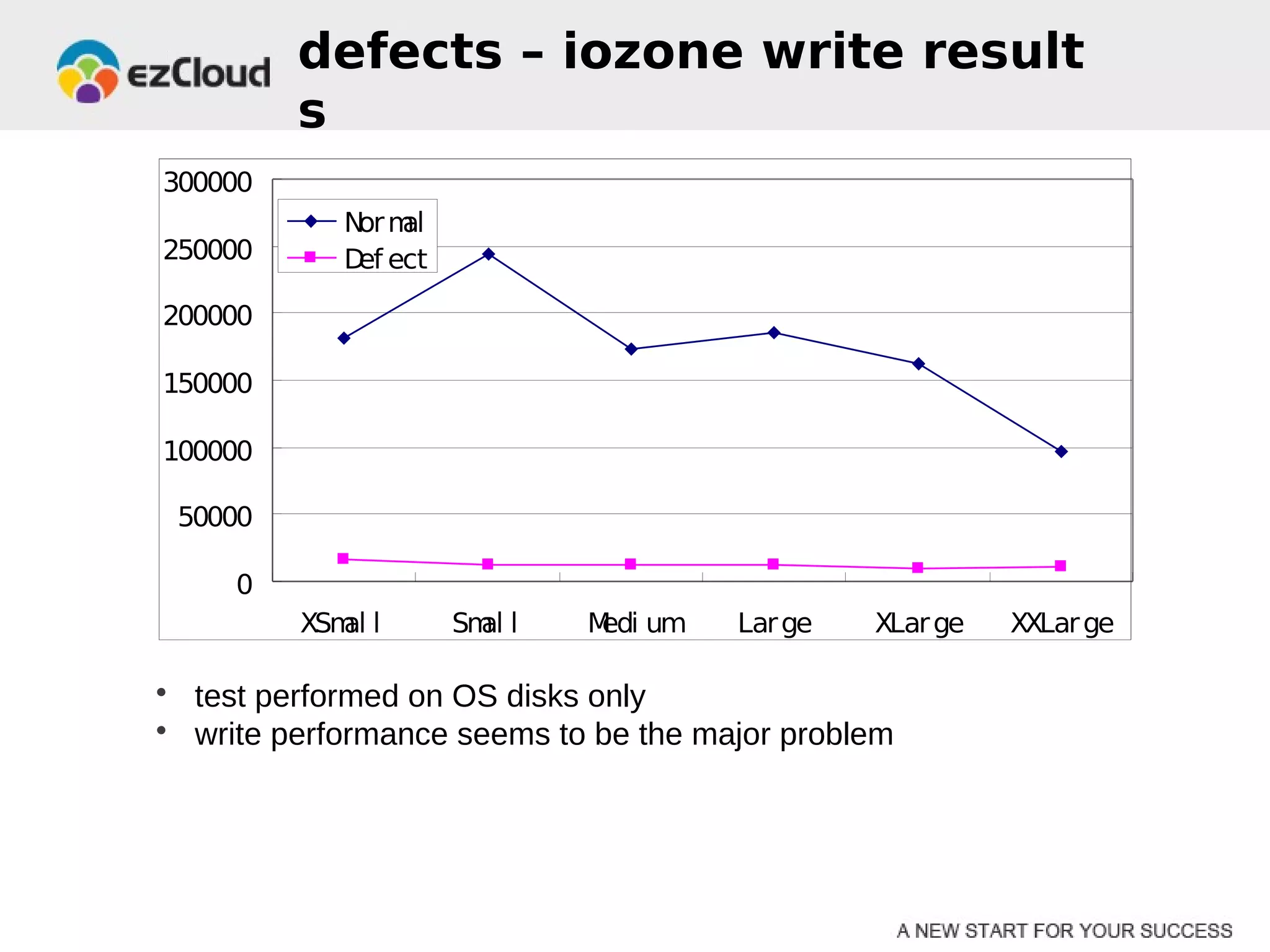
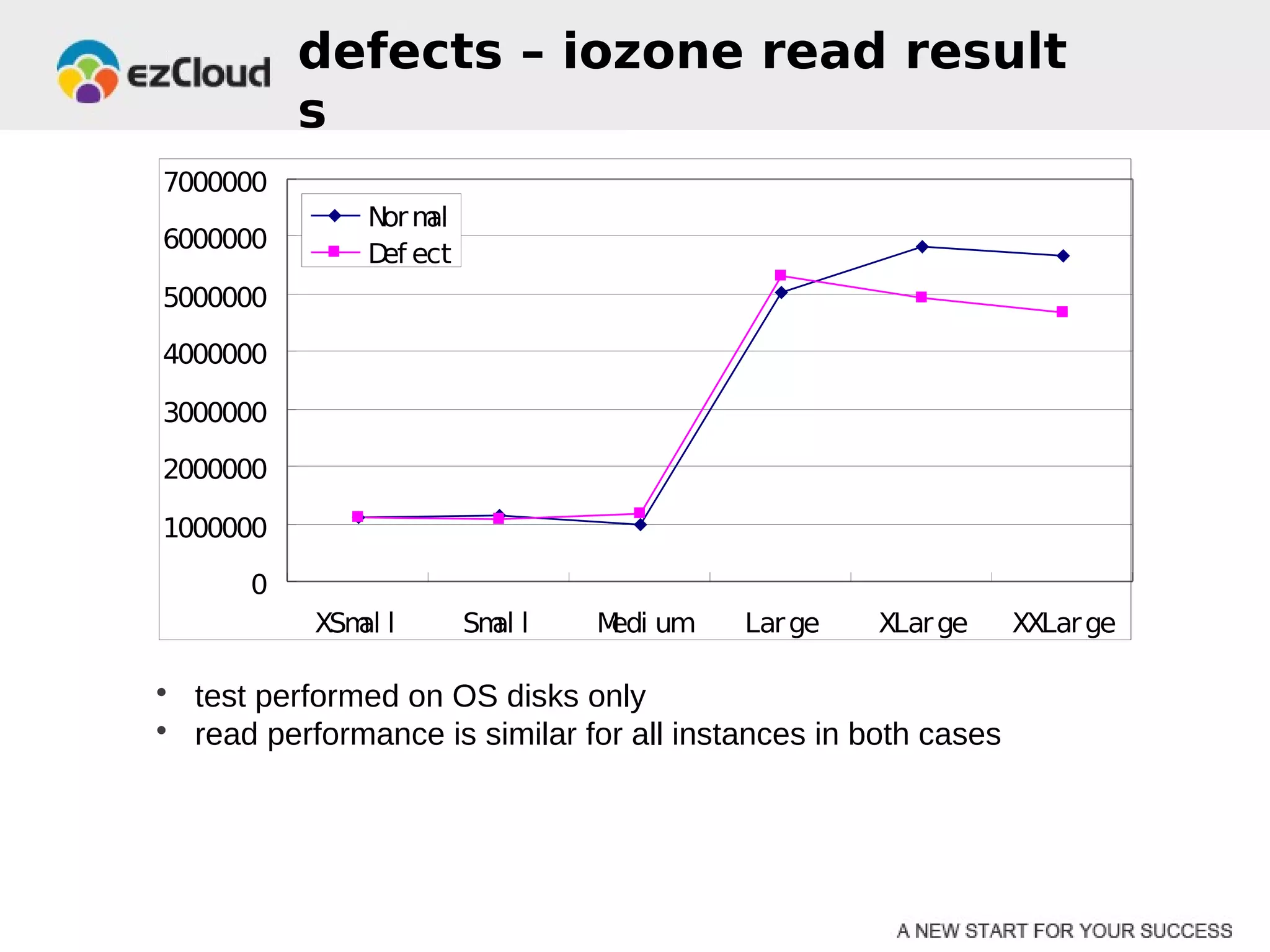



HP Cloud Services conducted performance testing on various VM configurations provided by OpenStack. Benchmark tests were run including byte-unixbench, mbw, iozone, iperf, pgbench and Hadoop wordcount. The results showed the larger VM configurations generally had better performance, but some defects were discovered in 7 out of 20 test VMs, indicating the defect rate was too high for production use. While defects were not directly related to OpenStack, the conclusions were that OpenStack still lacks functionality for production and building a full IaaS service is more complex than the software alone.




























![[Harvard CS264] 08a - Cloud Computing, Amazon EC2, MIT StarCluster (Justin Ri...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264-intro-to-cloud-computing-110322172806-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















































