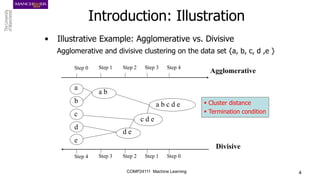
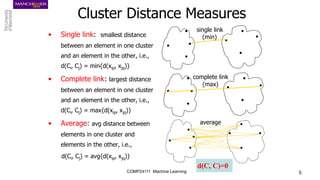
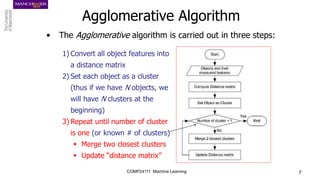
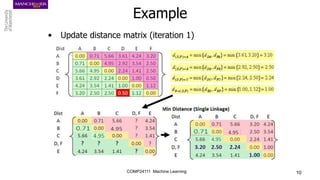
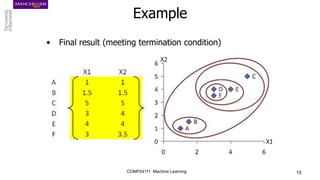
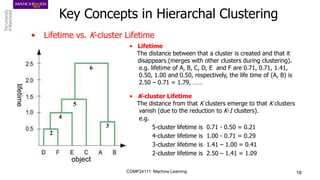
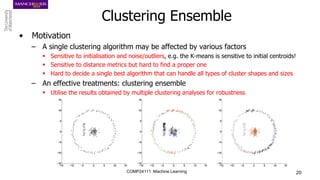
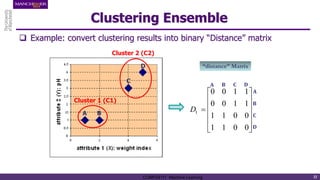
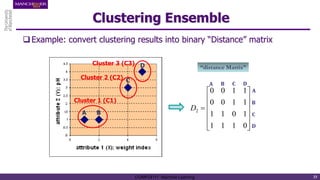
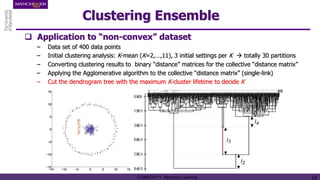
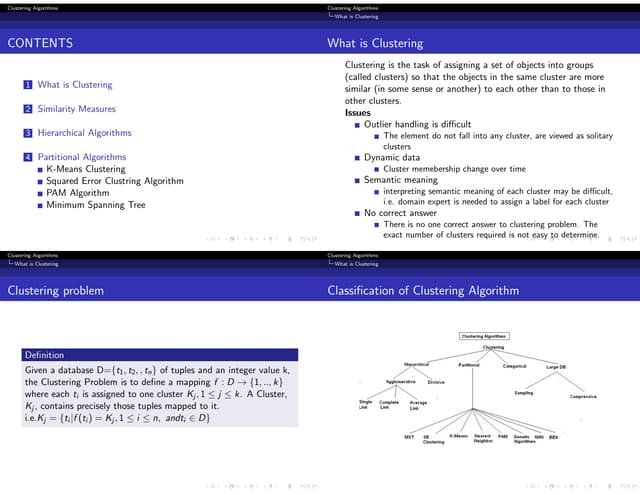
The document discusses hierarchical and ensemble clustering, detailing the agglomerative and divisive strategies used in clustering analysis. It covers key concepts such as distance measures, the agglomerative algorithm steps, and the lifetime of clusters, while also addressing the limitations of agglomerative methods and the benefits of clustering ensembles. Additionally, it highlights a clustering ensemble approach via evidence accumulation to improve robustness and performance in data analysis.
![Hierarchical and Ensemble
Clustering
Ke Chen
Reading: [7.8-7.10, EA], [25.5, KPM], [Fred & Jain, 2005]
COMP24111 Machine Learning](https://image.slidesharecdn.com/hierarchical2-240704141337-6579c02c/85/Hierarchical-2-l-ppt-for-data-and-analytics-1-320.jpg)
![Hierarchical and Ensemble
Clustering
Ke Chen
Reading: [7.8-7.10, EA], [25.5, KPM], [Fred & Jain, 2005]
COMP24111 Machine Learning](https://image.slidesharecdn.com/hierarchical2-240704141337-6579c02c/75/Hierarchical-2-l-ppt-for-data-and-analytics-1-2048.jpg)