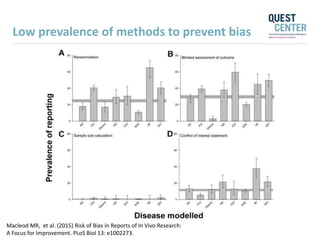
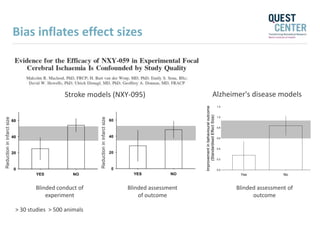
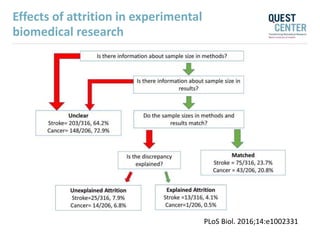
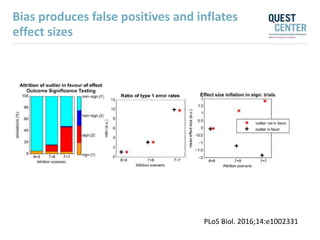
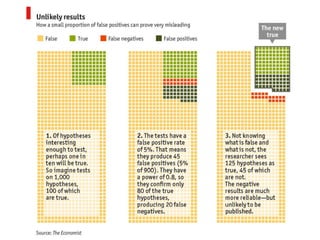
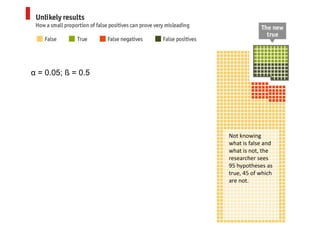
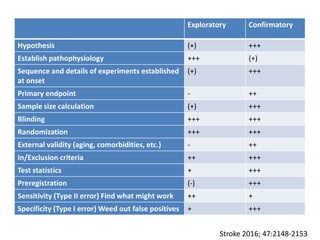
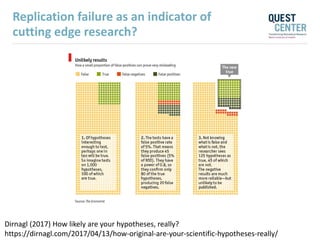
The document discusses issues with reproducibility and replication in biomedical research. It notes decades of failed translational stroke research due to biases, low statistical power, and other issues. It argues that both exploration and confirmation are needed, but they are often conflated. Exploration aims to generate new theories while confirmation aims to demonstrate treatment effects. The document provides suggestions to reduce biases, increase power, practice open science through preregistration and data sharing, and consider effect sizes over sole reliance on p-values. Failure to replicate may be due to cuting-edge research pushing boundaries rather than a false positive original result. Both replication and non-replication can provide valuable scientific insights when properly interpreted.