More Related Content

PDF

PPTX

PDF
Webアプリを並行開発する際のマイグレーション戦略 
PPTX

PDF

PDF

PDF

PDF
TensorFlow XLAは、 中で何をやっているのか? What's hot

PPTX
BuildKitによる高速でセキュアなイメージビルド 
PPTX

PDF

PDF
Docker 9 tips~意外と知られていない日常で役立つ便利技 
PPTX
トランザクションをSerializableにする4つの方法 
PDF
なぜあなたのプロジェクトのDevSecOpsは形骸化するのか(CloudNative Security Conference 2022) 
PDF
ネットワーク ゲームにおけるTCPとUDPの使い分け 
PDF

PPTX
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F... 
PDF

PPTX

PDF
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料) ![[社内勉強会]ELBとALBと数万スパイク負荷テスト](https://cdn.slidesharecdn.com/ss_thumbnails/elbalb-160822022623-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[社内勉強会]ELBとALBと数万スパイク負荷テスト 
PDF

ODP
Goのサーバサイド実装におけるレイヤ設計とレイヤ内実装について考える 
PPTX
GitLab から GitLab に移行したときの思い出 
PDF
ネットワークOS野郎 ~ インフラ野郎Night 20160414 
PDF
![[D31] PostgreSQLでスケールアウト構成を構築しよう by Yugo Nagata](https://cdn.slidesharecdn.com/ss_thumbnails/d31postgresnagata-131128230735-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[D31] PostgreSQLでスケールアウト構成を構築しよう by Yugo Nagata 
PDF
Similar to システムパフォーマンス勉強会#1

PPTX

PPTX

PDF

PPTX

PPTX

PDF

PDF
perfを使ったPostgreSQLの解析(前編) 
PDF
C22 Oracle Database を監視しようぜ! by 山下正/内山義夫 
PDF
perfを使ったpostgre sqlの解析(後編) 
PDF
シンプルでシステマチックな Oracle Database, Exadata 性能分析 
PDF

PPTX

PDF
「Oracle Database + Java + Linux」�環境における性能問題の調査手法 �~ミッションクリティカルシステムの現場から~ Part.1 
PDF

PDF

PDF
A24 SQL Server におけるパフォーマンスチューニング手法 - 注目すべきポイントを簡単に by 多田典史 
PPT
�Linux/DB Tuning (DevSumi2010, Japanese) 
PDF
プロとしてのOracleアーキテクチャ入門 ~番外編~ @ Developers Summit 2009 
PDF
【18-B-2】データ分析で始めるサービス改善最初の一歩 
PDF
More from shingo suzuki

PPTX

PPTX

PDF

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

ODP
システムパフォーマンス勉強会#1
- 1.
- 2.
- 3.
今回の内容
詳解システム・パフォーマンス 1 章2 章
システムパフォーマンス分析に使う基礎的な概念の話
• 2章 メソドロジ
• 用語
• モデル
• コンセプト
• 視点
• メソドロジ
• モデリング
• キャパシティプランニング
• 統計
• モニタリング
• ビジュアライゼーション
- 4.
■ 用語
• IOPS
•1秒当たりの I/O オペレーション
• スループット
• 仕事が実行されるスピード
• 特に通信ではデータ転送速度を表す
• 応答時間
• オペレーションが完了するまでの時間
• ボトルネック
• システムのパフォーマンスに限界を与えているリソース
• キャッシュ
• (物理キャッシュ) 限定された量のデータを重複して格納したりバッファリングしたりす
ることができる高速記憶領域
• その他
• レイテンシ、使用率、飽和ついてはのちほど
- 5.
- 6.
- 7.
- 8.
- 9.
レイテンシ(遅延)
• オペレーションが実行されるまでの待ち時間
• 時間による指標
•さまざまな計算ができる
• レイテンシが分かればスピードアップの上限がどれだけになるか予測できる
• ことなる指標もレイテンシか時間に変換できれば比較可能
• ネットワークI/O と ディスク I/O のどちらを使った方がパフォーマンスが出るか?
• 計測場所は様々→計測の対象で表現される
• 例:
• TCP 接続遅延
• TCPデータ転送遅延
• 動的トレーシングによって任意の場所で計測できるようになった
要求 完了
応答時間
レイテンシ オペレーション
にかかった時間
- 10.
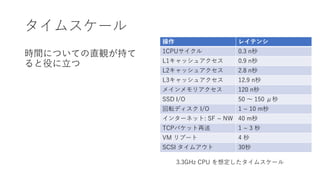
タイムスケール
操作 レイテンシ
1CPUサイクル 0.3n秒
L1キャッシュアクセス 0.9 n秒
L2キャッシュアクセス 2.8 n秒
L3キャッシュアクセス 12.9 n秒
メインメモリアクセス 120 n秒
SSD I/O 50 ~ 150 μ秒
回転ディスク I/O 1 ~ 10 m秒
インターネット: SF ~ NW 40 m秒
TCPパケット再送 1 ~ 3 秒
VM リブート 4 秒
SCSI タイムアウト 30秒
時間についての直観が持て
ると役に立つ
3.3GHz CPU を想定したタイムスケール
- 11.
トレードオフ
• パフォーマンスについてのトレードオフ
• 2つを選ぶ必要がある
•納期と低コストを選びがち
• 後からパフォーマンス向上が不可能になることも
• チューニングでもトレードオフがある
• CPUとメモリ
• キャッシュを有効利用してCPUの利用を減らす
• データ圧縮にCPUを使いメモリの利用を抑える
• ファイルシステムレコードサイズによるトレードオフ
• アプリケーション I/O サイズに近づけるとキャッシュを有効利用できる
• バックアップなどストリーミングのパフォーマンスが減少
パフォーマンス
納期 低コスト
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
パフォーマンス指標
パフォーマンス指標 = 統計情報
•数値やグラフなどの形で得られる
• 一般的な指標
• IOPS
• スループット
• 内容はコンテキスト依存
• 使用率
• レイテンシ
• オーバーヘッド
• 指標を収集し、格納するためにどこかでCPUサイクルを使ってしまう
• 観察者効果
• 問題点
• ベンダが提供する指標が間違っている、誤ったものになる場合がある
- 19.
- 20.
- 21.
- 22.
- 23.
キャッシュ管理アルゴリズム
• MRU (MostRecently Used)
• キャッシュ保持ポリシー
• もっとも最近に使ったオブジェクトを残す
• LRU (Least Recently Used)
• キャッシュ削除ポリシー
• もっとも最近に使ったオブジェクトから削除する
- 24.
パフォーマンス分析の視点
• リソース分析
• ボトムアップな視点の分析
•システムリソースの分析から始める
• 作業:
• パフォーマンス問題の調査
• キャパシティプランニング
• 指標
• IOPS,スループット,使用率,飽和
• ワークロード分析
• トップダウンな視点の分析
• アプリケーションの解析から始める
• 作業:
• ワークロードの特性を把握する
• アプリケーションの応答時間を調べる
• エラーを探す
• 指標
• スループット,レイテンシ
アプリケーション
システムライブラリ
システムコール
カーネル
デバイス
ワークロード
- 25.
■メソドロジ
• 街灯のアンチメソッド
• ランダム変更アンチメソッド
•誰かほかの人を非難するアンチメソッド
• その場限りのチェックリストメソッド
• 問題の記述
• 診断サイクル
• ツールメソッド
• USEメソッド
• ワークロードの特性の把握
• ドリルダウン分析
• レイテンシ分析
• メソッドR
• イベントトレーシング
• ベースライン統計
• パフォーマンスモニタリング
• 静的パフォーマンスチューニング
• キャッシュチューニング
• マイクロベンチマーキング
• キャパシティプランニング
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
ハードウェアのリソースリスト例
サーバハードウェアを想定
• CPU
• コア,ハードウェアスレッド
• メインメモリ
• DRAM
• ネットワークインターフェイス
• イーサネットポート
• ストレージデバイス
• ディスク
• コントローラ
• ストレージ, ネットワーク
• インターコネクト
• CPU, メモリ, I/O
リストに含めない方がよいもの
• ハードウェアキャッシュ
• 例: CPUキャッシュ
• 使用率が高いほうがパフォーマ
ンスがあがるため
- 35.
ソフトウェアのリソースリスト例
• ミューテックスロック
• 使用率→ロックされていた時間
• 飽和 →ロックを待ってキューイングされていたスレッド
• スレッドプール
• 使用率 →スレッドが要求を処理してビジー状態だった時間
• 飽和 →スレッドプールからのサービス待ちになっていた要求の数
• プロセス/スレッドの容量(特にプロセス/スレッド数の上限があるとき)
• 使用率 →プロセス/スレッド数
• 飽和 →割り当てを待っているとき
• エラー →割り当てが失敗したとき (cannot fork など)
• ファイル記述子の容量
• プロセス/スレッドの容量と同様
- 36.
USEの解釈方法
• 使用率
• 使用率100% → ボトルネックを起こしている兆候
• 使用率 60% 以下 →
• 短期間の 100 %資料率が隠れているか可能性
• 一部のリソース(HDDなど) ではすでに遅れが発生している可能性
• 飽和
• 少しでも飽和があれば問題が起きている可能性がある
• エラー
• エラーカウンタが 0 以外なら精査すべき
• 特にパフォーマンスが低いときにエラーが増える場合は要注意
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
Kendallの記法
A/S/m
• A -到着過程
• S – サービス時間分布
• m – サービスセンター数
• M/M/1
• 到着 → マルコフ過程
• サービス時間 → マルコフ過程
• サービスセンタ数 → 1
• M/G/1
• 到着 → マルコフ過程
• サービス時間 → 一般分布
• サービスセンタ数 → 1
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
平均
• 算術平均
• 値の総和を値の個数で割ったもの
•幾何平均
• すべての値をかけた席の n 乗根
• ネットワークのパフォーマンス分析に使う場合がある
• ネットワークスタックの各レイヤのパフォーマンス向上は「相乗効果」で上がる
• 調和平均
• 値の個数を値の逆数の総和で割ったもの
• 速度の平均などに適している場合がる
• 時間平均
• 時系列的にとった同じ指標に使用する
• CPU使用率など
• 減衰平均
• uptime などのロードアベレージに使われる
- 55.
- 56.
- 57.
- 58.
- 59.