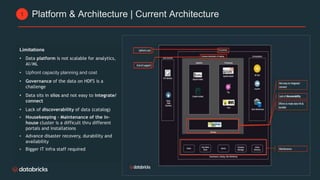
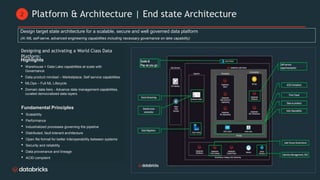
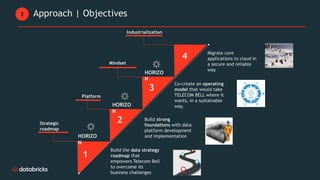
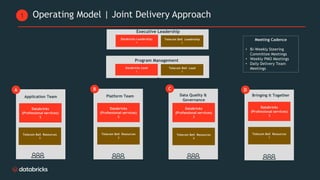
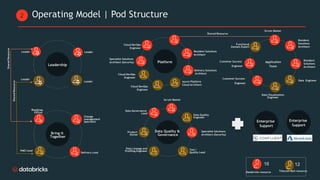
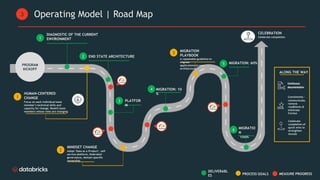
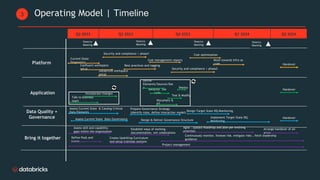
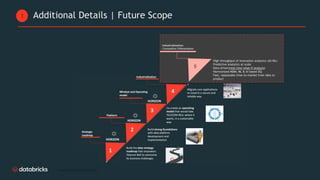
Telecom Bell is migrating their core applications to the cloud to improve network quality of service and enable personalized customer engagement using customer data. They are facing challenges with their on-premise data platform's lack of scalability, data silos, and governance issues. Databricks will help design a new cloud-based data platform architecture using their platform and Confluent for event streaming. The joint delivery approach between Telecom Bell and Databricks teams will include establishing data governance, migrating applications in phases, change management support, and reaching the desired timeline of May 2024.














































![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DSC Europe 24] Josip Saban - Buidling cloud data platforms in enterprises](https://cdn.slidesharecdn.com/ss_thumbnails/josipsaban-buidlingclouddataplatformsinenterprises-250217194546-5568421d-thumbnail.jpg?width=640&height=640&fit=bounds)





























