





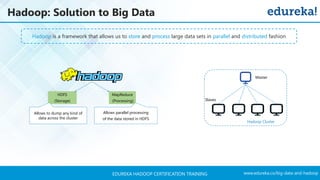

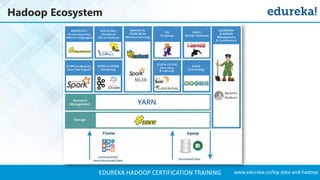

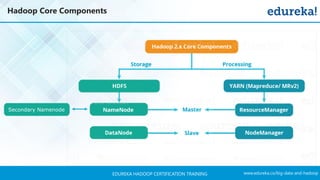

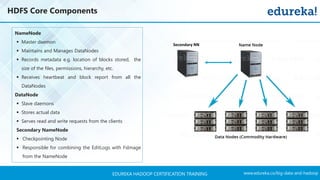

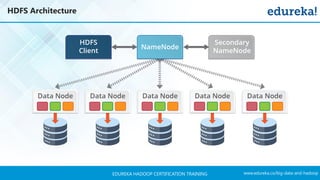



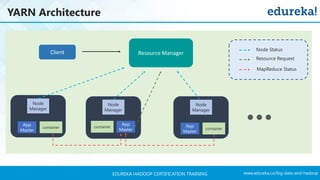

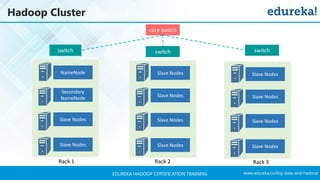



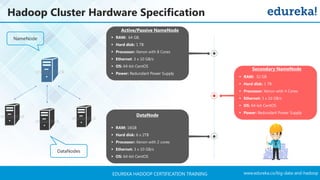

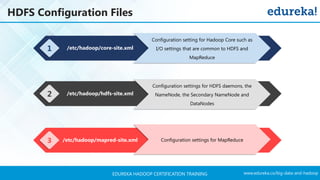
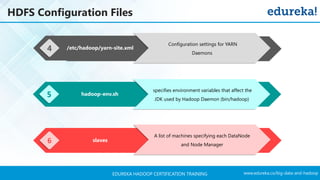







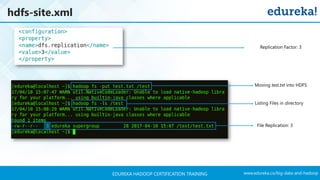



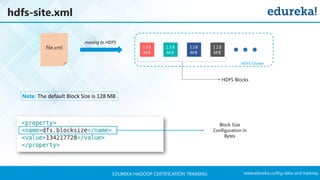



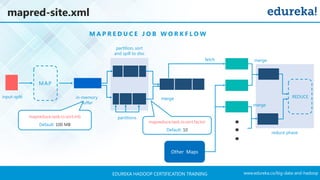
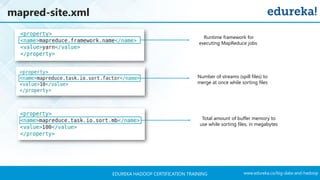



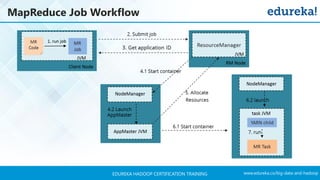
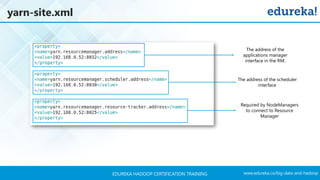
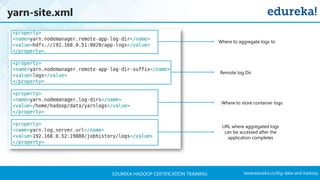
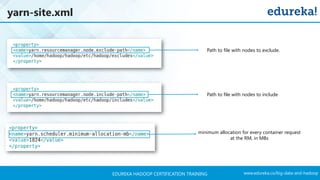
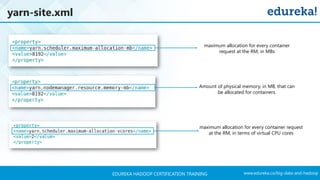

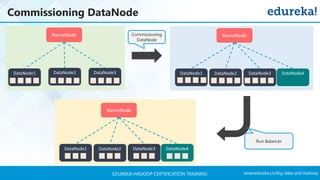
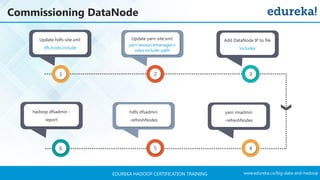

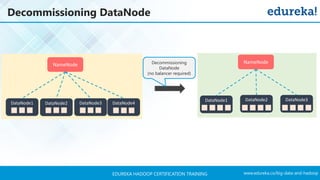
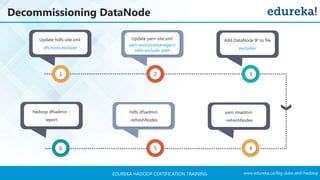

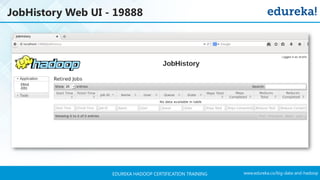

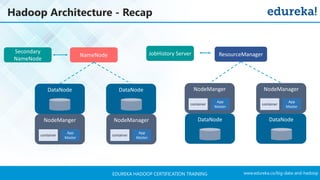




The document outlines a Hadoop certification training program offered by Edureka, covering essential topics such as the definition of big data, the Hadoop ecosystem, core components like HDFS and YARN, and multi-node installations. It also details configuration files, commissioning and decommissioning of datanodes, and job responsibilities of a Hadoop administrator, emphasizing the skills needed for effective implementation and support of Hadoop environments. Overall, it serves as a comprehensive guide for learning and understanding Hadoop's architecture and functionalities.






















































































