구글의 랭킹- 페이지랭크
링크
In-Link(자신에게 향하는 링크)가 많을 수록 점수가 높다.
Out-Link(외부로 향하는 링크)가 많을 수록 점수가 낮다.
앵커텍스트
<a href=”.....”> 앵커텍스트 </a>
단어 정보
문장내의 단어 위치
단어 순서
페이지랭크의 한계
1998년에 탄생된 오래된 아이디어
3
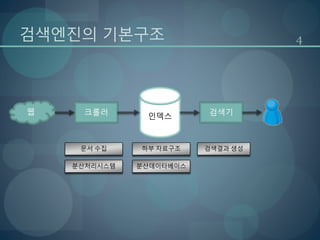
검색엔진의 기본구조(색인)
URL HTML
...박혜웅은 천재다
URL HTML
... 박혜웅은 바보다
웹
Repository
doc ID HTML
1 박혜웅은 천재다
2 박혜웅은 바보다
Forward Index
doc ID word ID ...
1 101, 102
2 101, 103
Inverted Index
word ID doc ID
101 1
101 2
102 1
103 2
Lexicon
word ID word
101 박혜웅
102 천재
103 바보
5
6.
검색엔진의 기본구조(검색)
Lexicon
word IDword
101 박혜웅
102 천재
103 바보
Inverted Index
word ID doc ID
101 1
101 2
102 1
103 2
Repository
doc ID HTML
1 박혜웅은 천재다
2 박혜웅은 바보다
천재
keyword
박혜웅은 천재다
result
6
7.
초기 구글 시스템– 문서수집
http://blog.bagesoft.com/3.html
URLlist
URL docID
http://blog.bagesoft.com/1.html 1
http://blog.bagesoft.com/2.html 2
http://blog.bagesoft.com/3.html ?
Repository
docID URL html etc
1 http://blog.bagesoft.com/3.html 압축된 HTML 다운날짜, HTML크기등
URL 서버
크롤러 docID가 없는 경우 생성
DocID 생성, HTML 압축
7
8.
초기 구글 시스템– 색인(구조해석)
DocIndex
docID URL title etc
1 http://blog.bagesoft.com/1.html ... ...
URLlist
URL docID
HTML에 포함된새 URL을 저장
Repository
docID URL text 기타 정보
1 http://blog.bagesoft.com/1.html 압축된 HTML 다운날짜, HTML크기등
<html>
<title>......</title>
<body>.....</body>
</html>
HTML 압축해제
문서 정보 요약
8
9.
초기 구글 시스템– 색인(단어처리)
<body>
<h1>박혜웅은 천재</h1>
<a href=“2.html”>박혜웅</a>이라는 ...
<a href=“3.html”>사람</a>....
</body>
Lexicon
word wordID
박혜웅 101
천재 102
은 103
이라는 104
사람 105
박혜웅은 천재
박혜웅이라는...
사람...
101 103 102
101 104...
105...
Forward Index
docID wordID pos size etc
1 101 0 3 ...
1 103 1 3 ...
1 102 2 2 ...
1 101 3 2 ...
1 104 4 2 ...
1 105 5 2 ...
새 단어 추가
9
초기 구글 시스템– 검색(인덱스서버)
Lexicon
word wordID
박혜웅 101
천재 102
은 103
이라는 104
사람 105
천재
1, 3
Inverted Index
wordID docID pos size etc
101 1 0 3 ...
101 1 3 2 ...
102 1 2 2 ...
103 2 1 3 ...
104 2 4 2 ...
102 3 5 2 ...
102
wordID로 변
환
docID 목록 생성
docID list
keyword
12
13.
초기 구글 시스템– 검색(문서서버)
웹 서버
문서 서버
Repository
docID URL HTML 다운로드날짜 HTML 크기
1 http://blog.bagesoft.com/1.html ... ... ...
3 http://blog.bagesoft.com/3.html ... ... ...
DocIndex
docID URL doc info
1 http://blog.bagesoft.com/1.html ...
3 http://blog.bagesoft.com/3.html ...
Links
docID docID points
9 1 0.2
9 3 0.1
1, 3 docID list
랭킹 계산
부가 정보
URL, HTML, ...
문서요약
13
14.
Barrels
초기 구글 시스템- 색인
DocIndex
Lexicon
단어처리
링크처리
구조해석
랭킹
Repository
URLlist
Links
URL 서버
크롤러크롤러크롤러
웹
URL1
URL1
Web Page2
DocID, URL, HTML2
URL 추가3
docID, URL, doc info3
DocID, Text4
wordID4
word4
link5
docID, docID5
docID, docID6
docID5
points6
Forward
Index
Inverted
Index
anchor text5
docID, wordID
, word info
4
Indexing
Lexicon
word wordID
Repository
docID URL HTML
DocIndex
docID URL doc info
URLlist
URL docID
Forward Index
docID wordID word info
Inverted Index
wordID docID word info
Links
docID docID points
DocID, URL, HTML3
14
15.
Barrels
초기 구글 시스템- 검색
인덱스 서버
DocIndex
Lexicon
Repository
Links
Inverted
Index
문서 서버
docID list2
word1
word ID2
웹 서버
Lexicon
word wordID
Repository
docID URL HTML
DocIndex
docID URL doc info
Inverted Index
wordID docID word info
docID list2
docID list3
4 docID top list
docID5
doc info4
Links
docID docID points
word ID1
result page7
docID list3
doc summaries6
HTML
summary
5
points3
word1
1 keyword
15
16.
검색과정의 분산
구글 DNS
LoadBalancer
Index Cluster
Web
Server
Web
Server
Web
Server
Index
Server
Index
Server
Load Balancer
Index
Server
Index
Server
Load Balancer
Doc
Server
Doc
Server
Load Balancer
Document Cluster
Doc
Server
Doc
Server
Load Balancer
shard shard shard shard
사용자와 가까운 로드밸런서의 IP1
keyword2
3 keyword
5 docID list 7 doc data
Spelling Check
Server
Advertising
Server
4 keyword
6 docID
Index
data #1
Index
data #1
Index
data #2
Index
data #2
Doc
data #1
Doc
data #1
Doc
data #2
Doc
data #2





















![[Google] 구글 앱스 활용법](https://cdn.slidesharecdn.com/ss_thumbnails/google-161021141028-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[4차]구글 알고리즘 분석(151106)](https://cdn.slidesharecdn.com/ss_thumbnails/4-151106-160217170051-thumbnail.jpg?width=640&height=640&fit=bounds)













