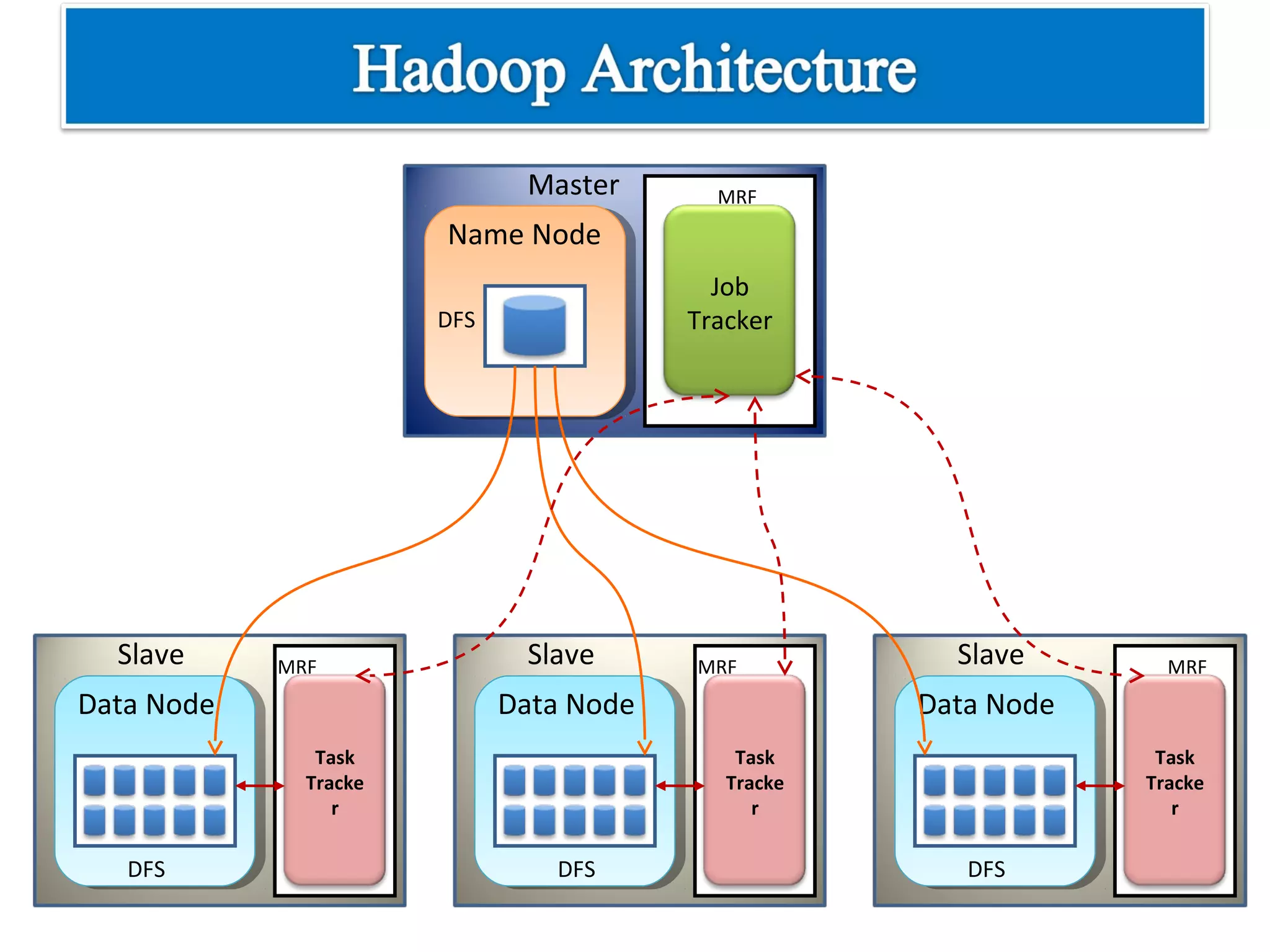
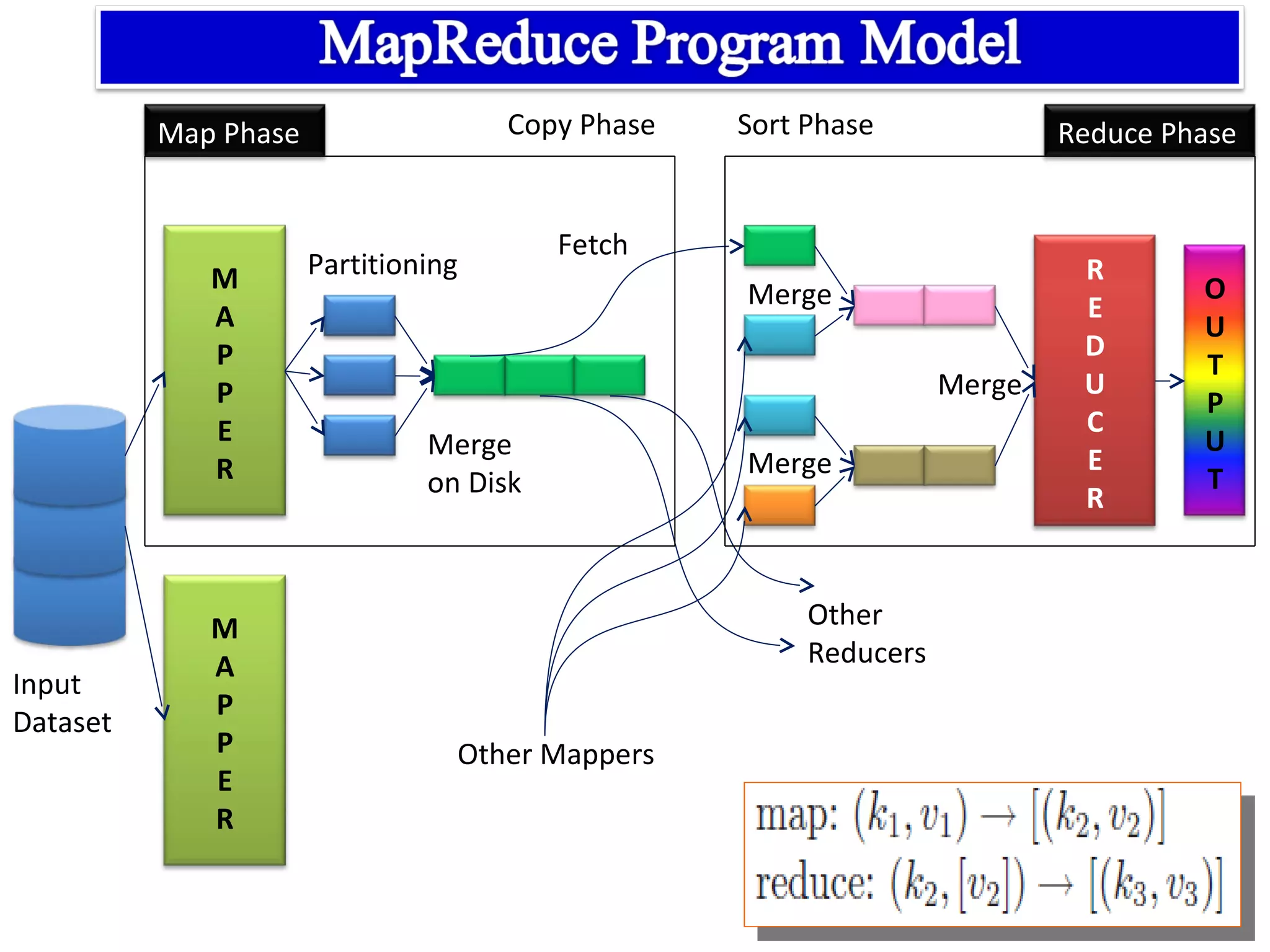
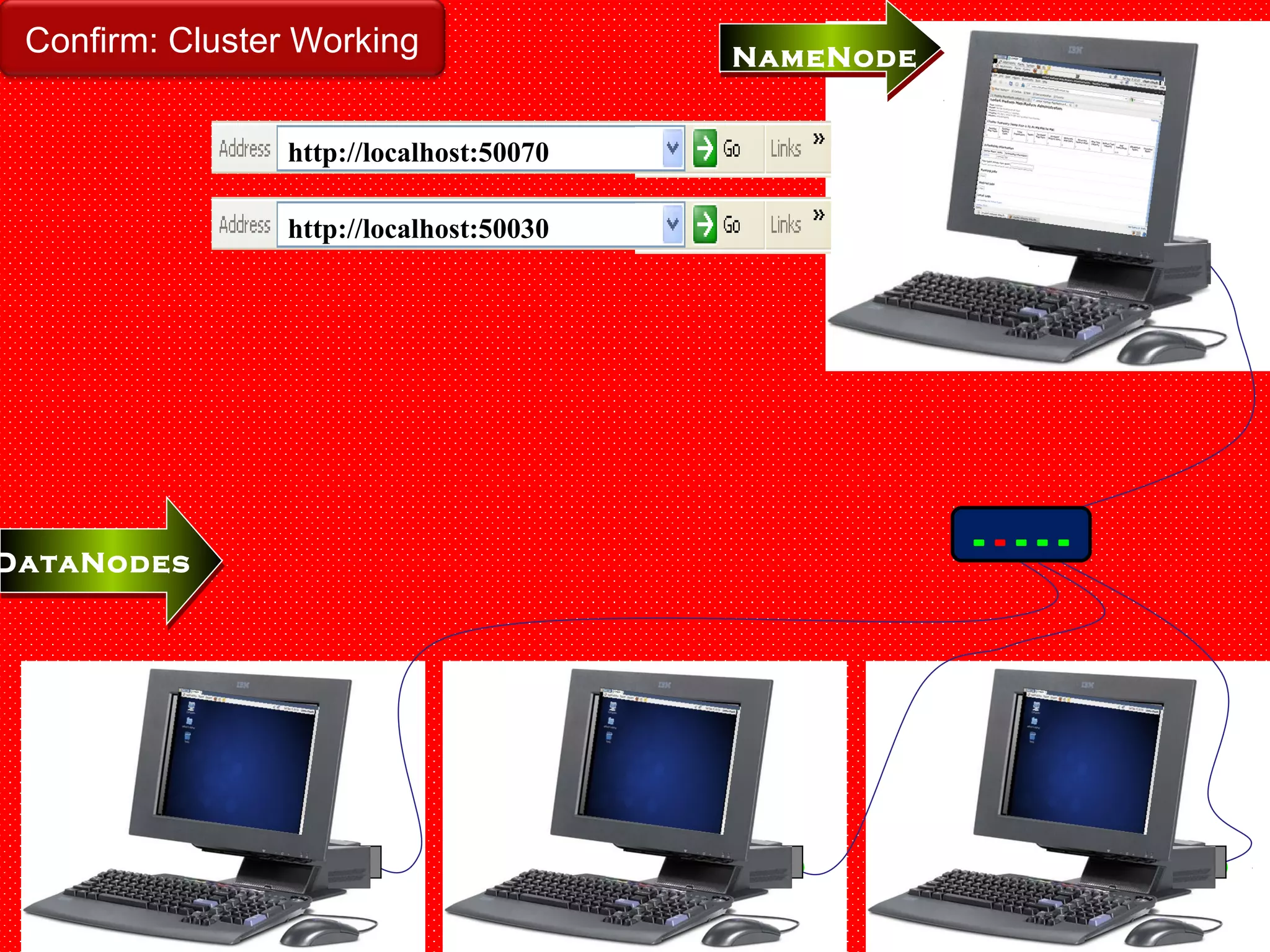
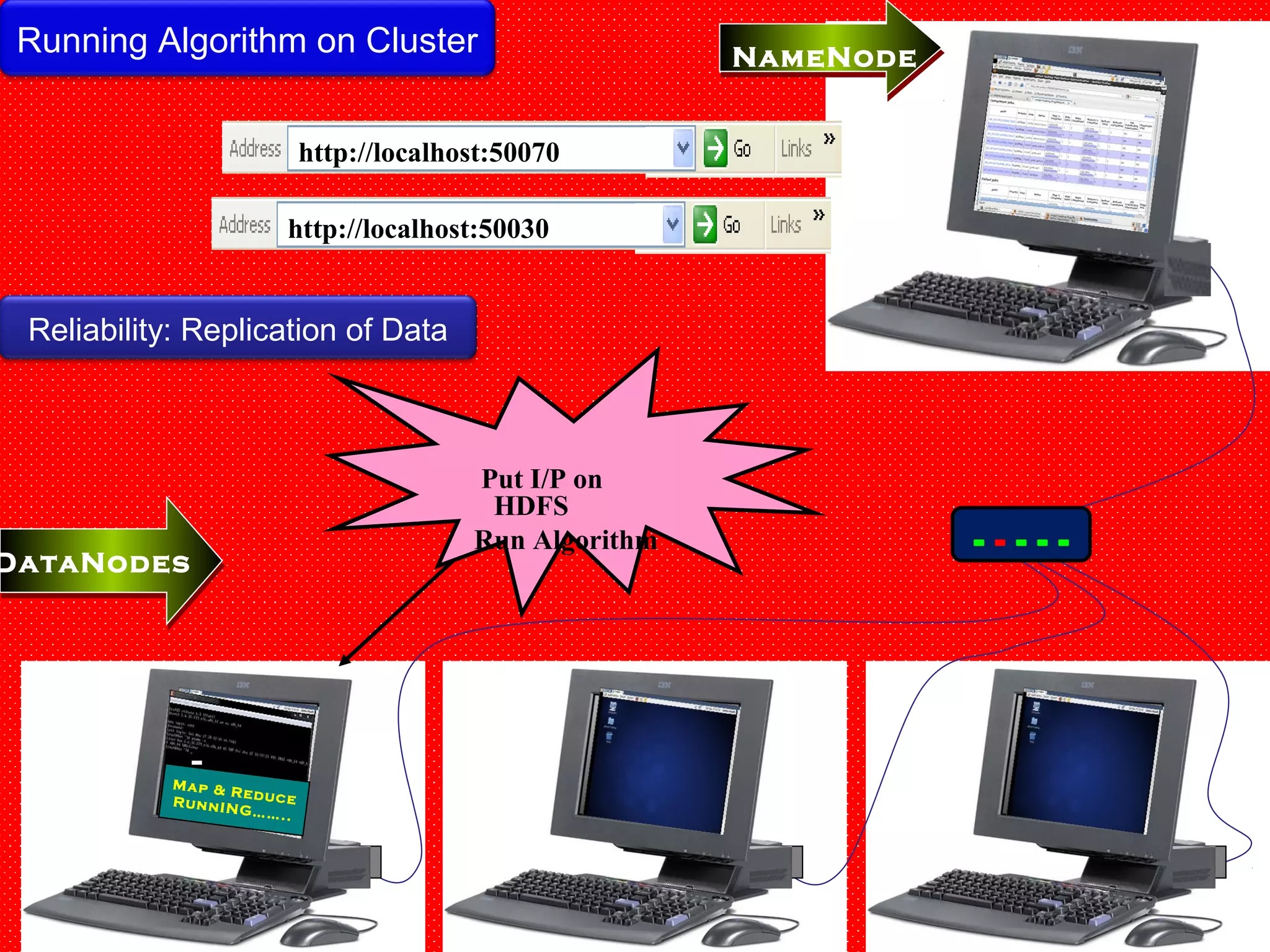
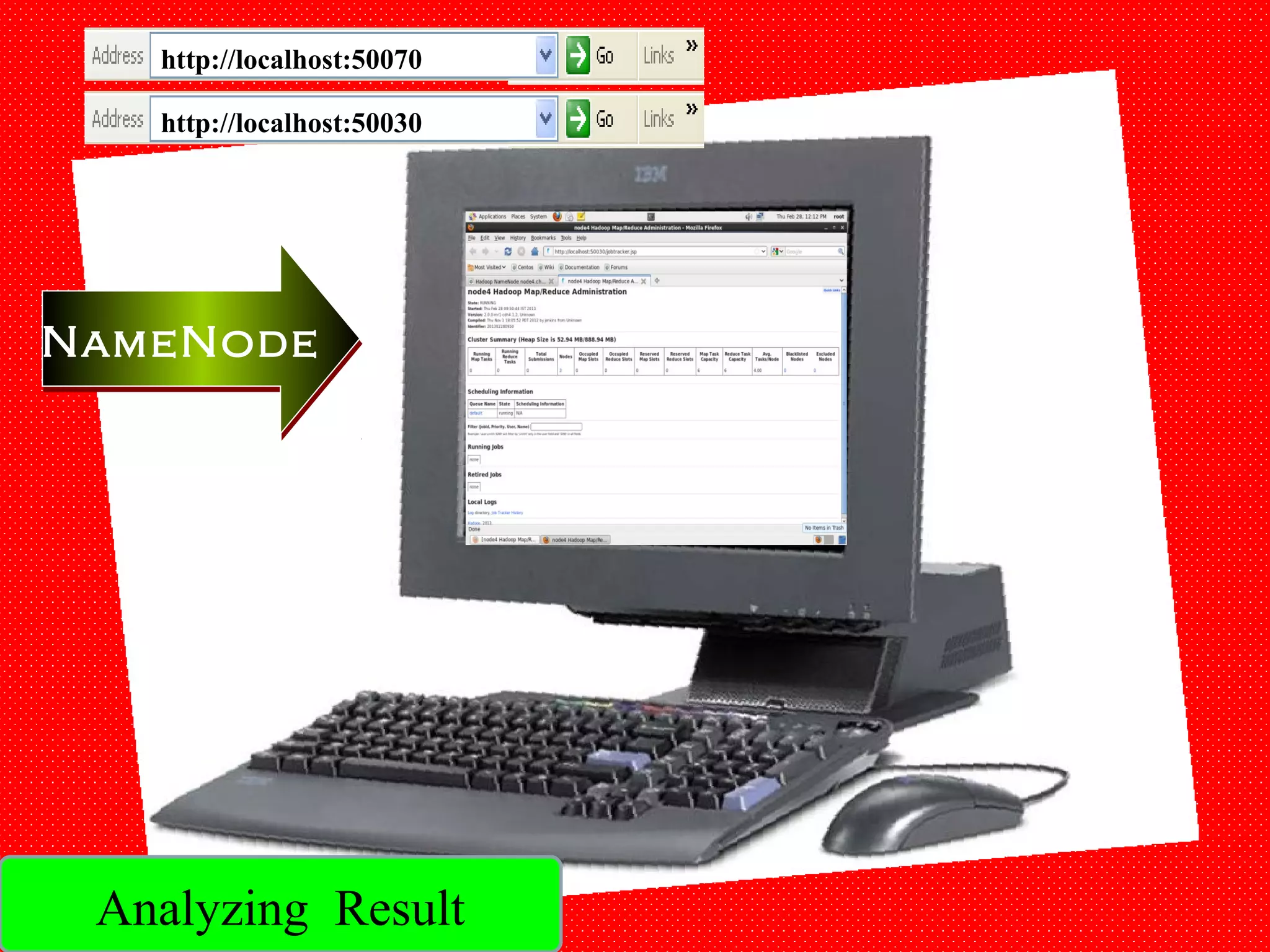
The document provides an overview of Hadoop architecture and the MapReduce programming model. It discusses that Hadoop is an open source software framework that provides scalable and fault-tolerant distributed storage and processing. It describes that Hadoop consists of two main components - the Hadoop Distributed File System (HDFS) for storage and the MapReduce framework for processing. HDFS stores data across compute nodes in a master-slave architecture with one namenode and multiple datanodes. MapReduce allows distributed processing of large datasets using a map and reduce function and executes jobs across a cluster of nodes managed by a jobtracker and multiple tasktrackers.




![12
[1] http://ieeexplore.ieee.org
[2] http://hadoop.apache.org/
[3] https://wiki.cloudera.com
[4] http://hadoop.apache.org/docs/hdfs/current/hdfs_design.html
[5] Books:
•Data-Intensive Text Processing with MapReduce, Jimmy Lin and
Chris Dyer University of Maryland, College Park.
•Hadoop: The Definitive Guide, Tom White.
12/05/14](https://image.slidesharecdn.com/xu3h7z4qrgus9s3rzkda-140512050916-phpapp02/75/Hadoop-and-MapReduce-12-2048.jpg)




































































