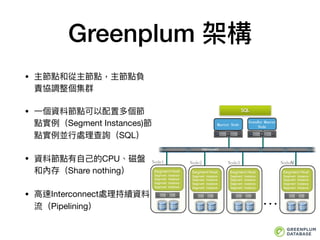
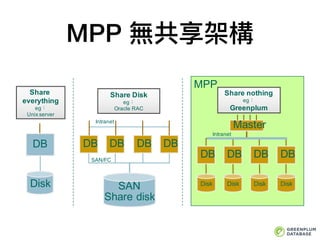
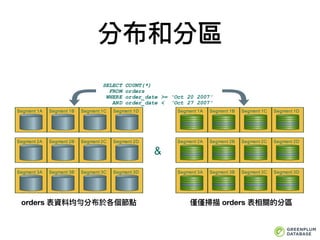
MPP 無共享架構
Share Disk
eg
OracleRAC
DB
SAN
Share disk
DB DBDB
Intranet
SAN/FC
Share
everything
eg
Unix server
DB
Disk
Share nothing
eg
Greenplum
DBDB DBDB
Disk Disk Disk Disk
Master
Intranet
MPP
8.
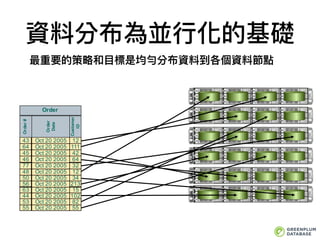
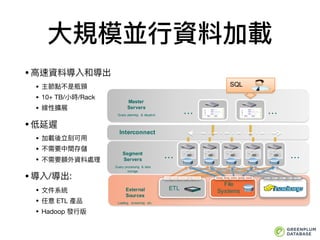
資料分布為並⾏行行化的基礎
43 Oct 202005 12
64 Oct 20 2005 111
45 Oct 20 2005 42
46 Oct 20 2005 64
77 Oct 20 2005 32
48 Oct 20 2005 12
Order
Order#
Order
Date
Customer
ID
50 Oct 20 2005 34
56 Oct 20 2005 213
63 Oct 20 2005 15
44 Oct 20 2005 102
53 Oct 20 2005 82
55 Oct 20 2005 55
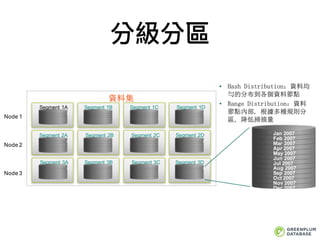
最重要的策略略和⽬目標是均勻分布資料到各個資料節點
9.
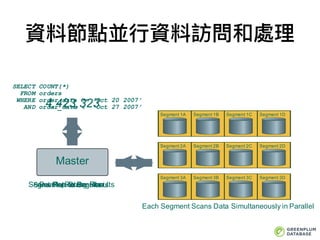
資料節點並⾏行行資料訪問和處理理
Master
Segment 1A Segment1B Segment 1C Segment 1D
Segment 2A Segment 2B Segment 2C Segment 2D
Segment 3A Segment 3B Segment 3C Segment 3D
Segment 1A Segment 1B Segment 1C Segment 1D
Segment 2A Segment 2B Segment 2C Segment 2D
Segment 3A Segment 3B Segment 3C Segment 3D
SELECT COUNT(*)
FROM orders
WHERE order_date >= ‘Oct 20 2007’
AND order_date < ‘Oct 27 2007’
Develop Query PlanSend Plan to SegmentsReturn ResultsSegments Return Results
4,423,323
Each Segment Scans Data Simultaneously in Parallel
分級分區
• , ,
•,
D
H
Segment 1A Segment 1C Segment 1D
Segment 2A Segment 2B Segment 2C Segment 2D
Segment 3A Segment 3B Segment 3C Segment 3D
Jan 2007
Feb 2007
Mar 2007
Apr 2007
May 2007
Jun 2007
Jul 2007
Aug 2007
Sep 2007
Oct 2007
Nov 2007
Dec 2007
Segment 1B
Node 1
Node 2
Node 3
12.
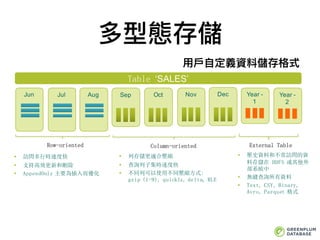
多型態存儲
Ÿ Tb q
ŸTa p d
Ÿ T Ow oe
9 : AD: C -
Ÿ p d
Ÿ ki lqn
Ÿ H L u R PV
‘SALES’
Jun
( D B: CF B: C
Oct Year -
1
Year -
2
C B
Ÿ m c x
mb ,) 1 gS
yz
Ÿ v r m
Ÿ C (1 : BH
EB BAD C te
Nov DecJul Aug Sep
⽤用⼾戶⾃自定義資料儲存格式