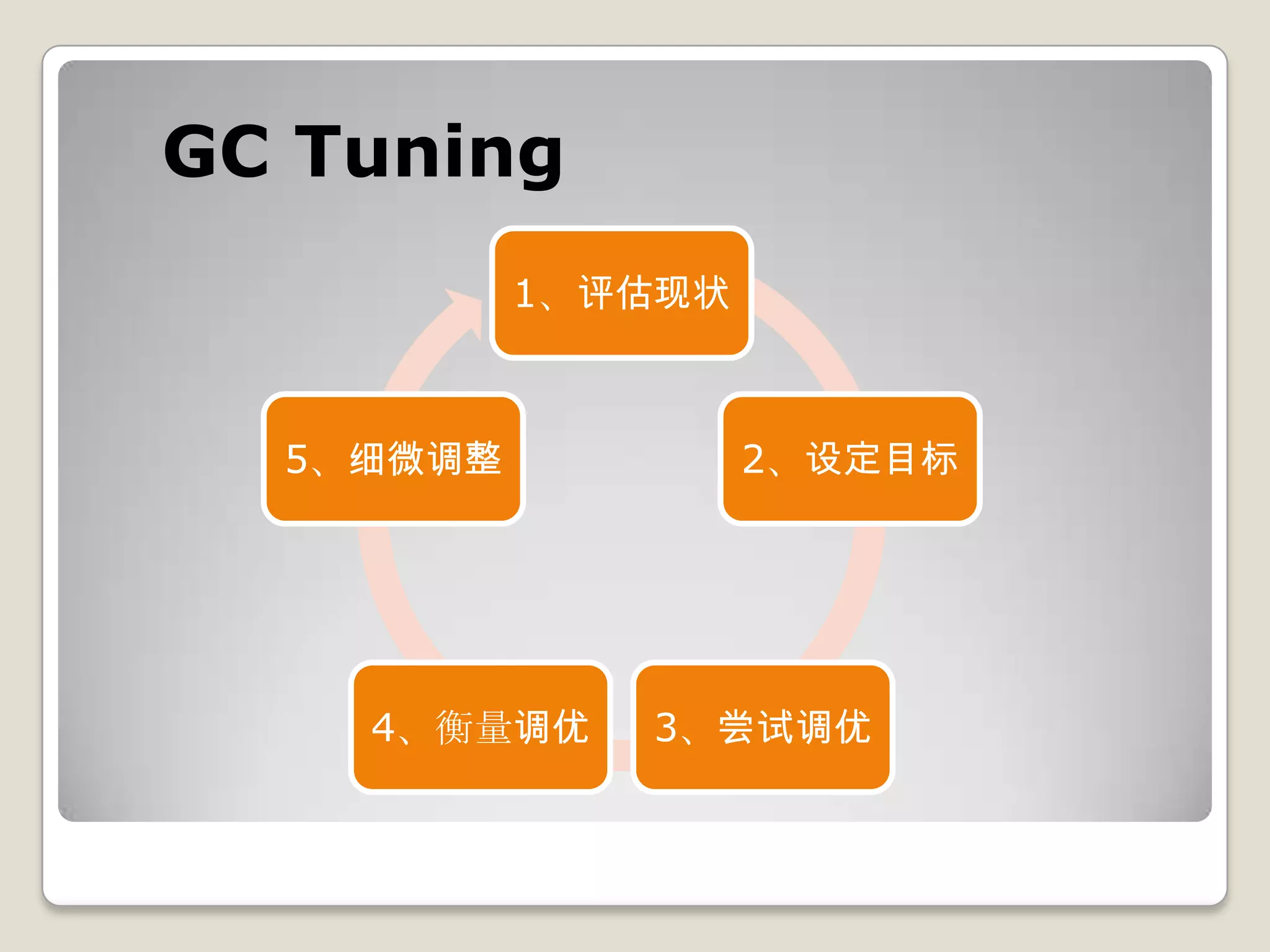
本文件深入探讨了 Sun JDK 1.6 的垃圾回收(GC)机制,包括内存分配、回收策略和不同类型的垃圾回收器(如串行、并行等)。文中详细介绍了内存的分代管理及对象晋升的规则,并提供了相关的代码示例及配置参数。理解 GC 的优化和调整策略对于解决 OOM 问题和提升应用程序的性能至关重要。










![新生代可用GC—串行
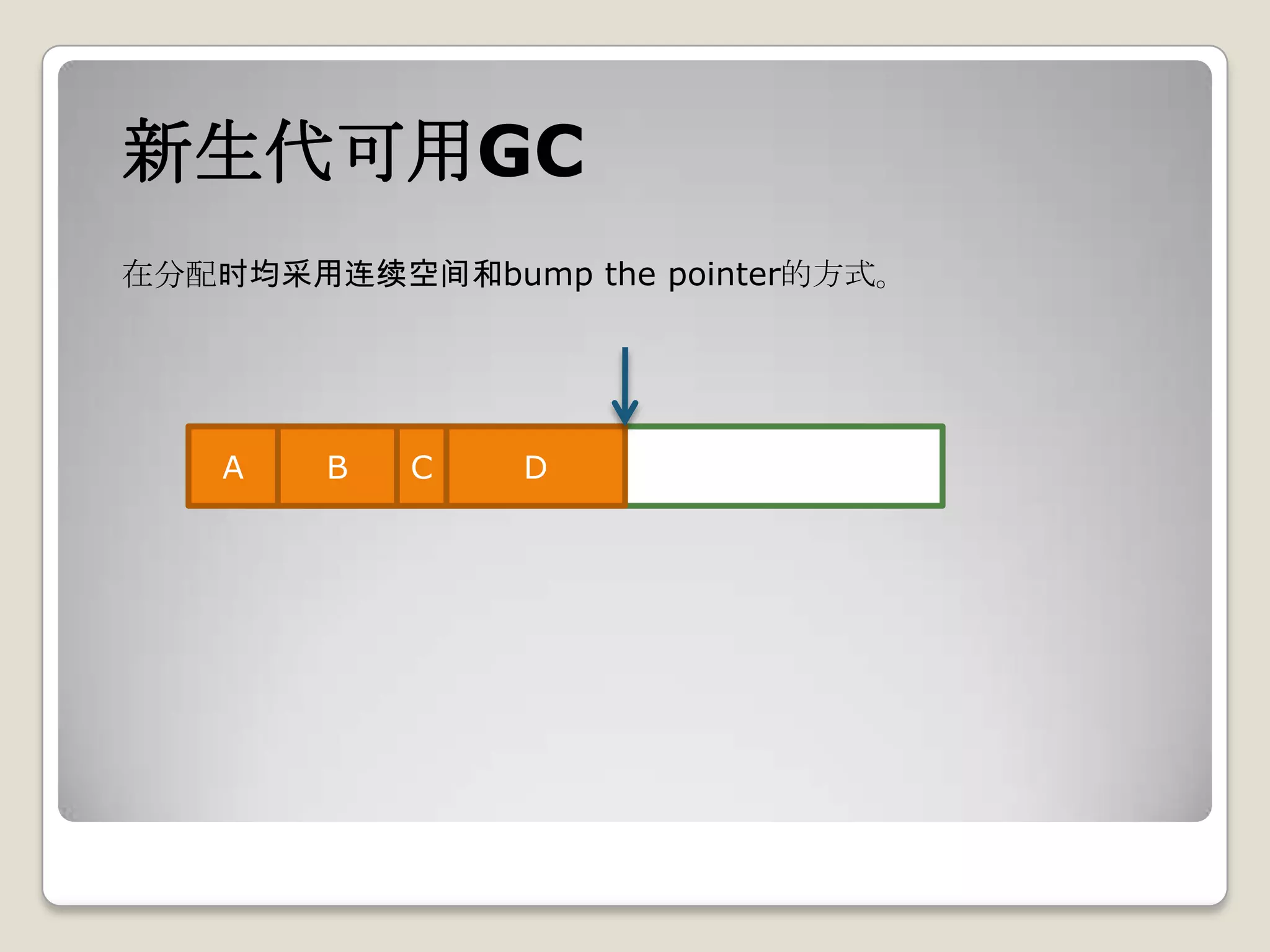
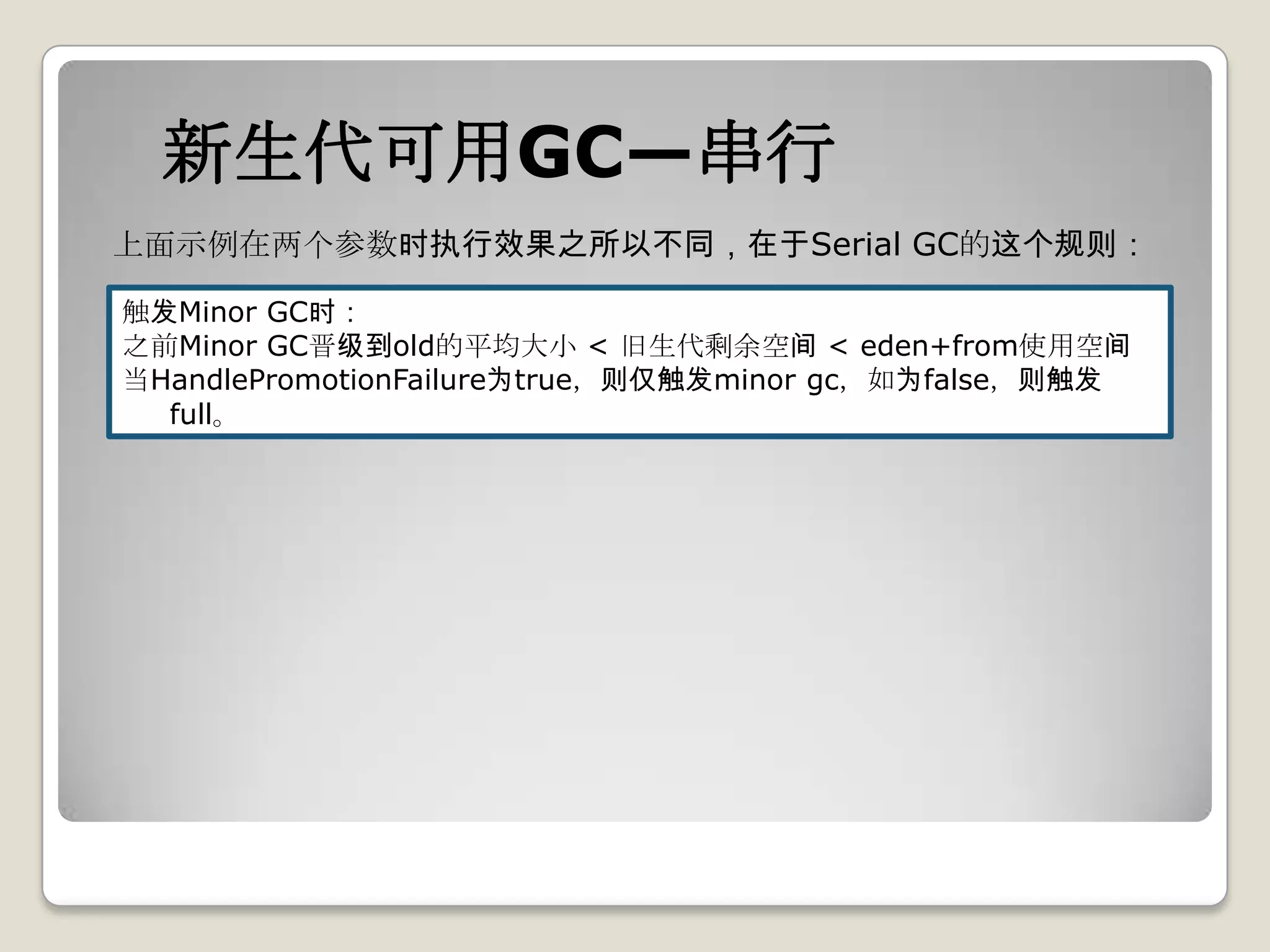
1. client模式下默认GC方式,也可通过-XX:+UseSerialGC来强制指定;
2. eden、s0、s1的大小通过-XX:SurvivorRatio来控制,默认为8,含义
为eden:s0的比例,启动后可通过jmap –heap [pid]查看。](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-13-2048.jpg)
![新生代可用GC—串行
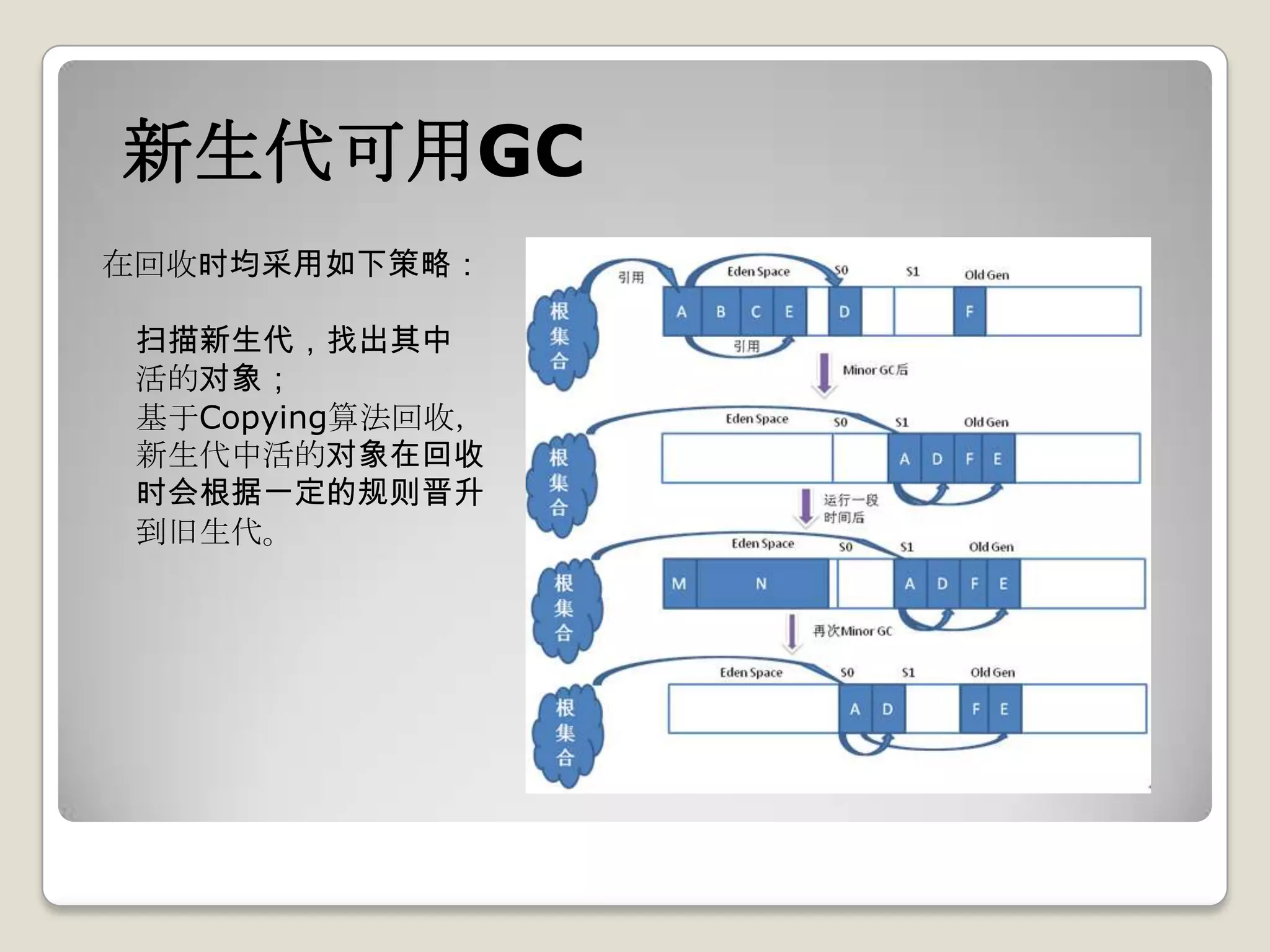
默认情况下,仅在TLAB或eden上分配,只有两种状况会在旧生代分配:
1、需要分配的大小超过eden space大小;
2、在配置了PretenureSizeThreshold的情况下,对象大小大于此值。
public class SerialGCDemo{
public static void main(String[] args) throws Exception{
byte[] bytes=new byte[1024*1024*2];
byte[] bytes2=new byte[1024*1024*2];
byte[] bytes3=new byte[1024*1024*2];
Thread.sleep(3000);
byte[] bytes4=new byte[1024*1024*4];
Thread.sleep(3000);
}
}
-Xms20M –Xmx20M –Xmn10M –XX:+UseSerialGC
-Xms20M –Xmx20M –Xmn10M -XX:PretenureSizeThreshold=3145728 –XX:+UseSerialGC](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-14-2048.jpg)
![新生代可用GC—串行
当eden space空间不足时触发。
public class SerialGCDemo{
public static void main(String[] args) throws Exception{
byte[] bytes=new byte[1024*1024*2];
byte[] bytes2=new byte[1024*1024*2];
byte[] bytes3=new byte[1024*1024*2];
System.out.println(“step 1");
byte[] bytes4=new byte[1024*1024*2];
Thread.sleep(3000);
System.out.println(“step 2");
byte[] bytes5=new byte[1024*1024*2];
byte[] bytes6=new byte[1024*1024*2];
System.out.println(“step 3");
byte[] bytes7=new byte[1024*1024*2];
Thread.sleep(3000);
}
}
-Xms20M –Xmx20M –Xmn10M –XX:+UseSerialGC](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-15-2048.jpg)

![新生代可用GC—串行
public class SerialGCDemo{
public static void main(String[] args) throws Exception{
byte[] bytes=new byte[1024*1024*2];
byte[] bytes2=new byte[1024*1024*2];
byte[] bytes3=new byte[1024*1024*2];
System.out.println("step 1");
bytes=null;
byte[] bytes4=new byte[1024*1024*2];
Thread.sleep(3000);
System.out.println("step 2");
byte[] bytes5=new byte[1024*1024*2];
byte[] bytes6=new byte[1024*1024*2];
bytes4=null;
bytes5=null;
bytes6=null;
System.out.println("step 3");
byte[] bytes7=new byte[1024*1024*2];
Thread.sleep(3000);
}
}
-Xms20M –Xmx20M –Xmn10M –XX:+UseSerialGC
-Xms20M –Xmx20M –Xmn10M -XX:-HandlePromotionFailure –XX:+UseSerialGC](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-17-2048.jpg)

![新生代可用GC—串行
public class SerialGCThreshold{ -Xms20M –Xmx20M –
public static void main(String[] args) throws Exception{ Xmn10M –
SerialGCMemoryObject object1=new SerialGCMemoryObject(1);
SerialGCMemoryObject object2=new SerialGCMemoryObject(8);
XX:+UseSerialGC
SerialGCMemoryObject object3=new SerialGCMemoryObject(8);
SerialGCMemoryObject object4=new SerialGCMemoryObject(8);
object2=null;
object3=null;
-Xms20M –Xmx20M –
SerialGCMemoryObject object5=new SerialGCMemoryObject(8); Xmn10M –
Thread.sleep(4000); XX:+UseSerialGC
object2=new SerialGCMemoryObject(8);
object3=new SerialGCMemoryObject(8); -
object2=null; XX:MaxTenuringThres
object3=null;
object5=null;
hold=1
SerialGCMemoryObject object6=new SerialGCMemoryObject(8);
Thread.sleep(5000);
}
}
class SerialGCMemoryObject{
private byte[] bytes=null;
public SerialGCMemoryObject(int multi){
bytes=new byte[1024*256*multi];
}
}](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-20-2048.jpg)


![JVM新生代可用GC—串行
[GC [DefNew: 11509K->1138K(14336K), 0.0110060 secs] 11509K-
>1138K(38912K),
0.0112610 secs] [Times: user=0.00 sys=0.01, real=0.01 secs]](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-23-2048.jpg)

![新生代可用GC—ParNew
[GC [ParNew: 11509K->1152K(14336K), 0.0129150 secs] 11509K-
>1152K(38912K),
0.0131890 secs] [Times: user=0.05 sys=0.02, real=0.02 secs]
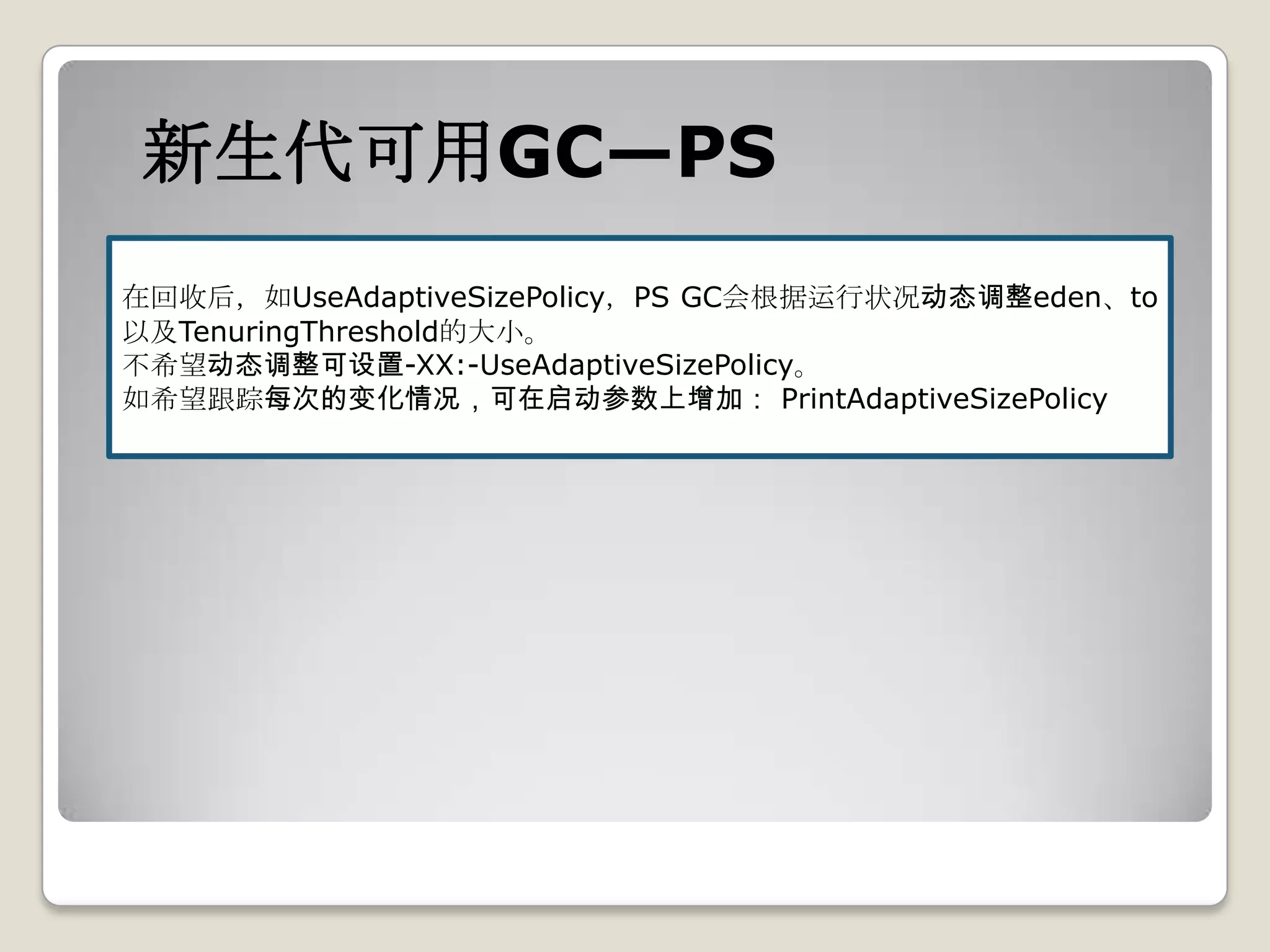
如启动参数上设置了-XX:+UseAdaptiveSizePolicy,则会输出
[GC [ASParNew: 7495K->120K(9216K), 0.0403410 secs] 7495K-
>7294K(19456K), 0.0406480 secs] [Times: user=0.06
sys=0.15, real=0.04 secs]](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-25-2048.jpg)

![新生代可用GC—PS
大多数情况下,会在TLAB或eden上分配。
如下一段代码:
public class PSGCDemo{
public static void main(String[] args) throws Exception{
byte[] bytes=new byte[1024*1024*2];
byte[] bytes2=new byte[1024*1024*2];
byte[] bytes3=new byte[1024*1024*2];
Thread.sleep(3000);
byte[] bytes4=new byte[1024*1024*4];
Thread.sleep(3000);
}
}
-Xms20M –Xmx20M –Xmn10M –XX:SurvivorRatio=8 –XX:+UseParallelGC](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-27-2048.jpg)
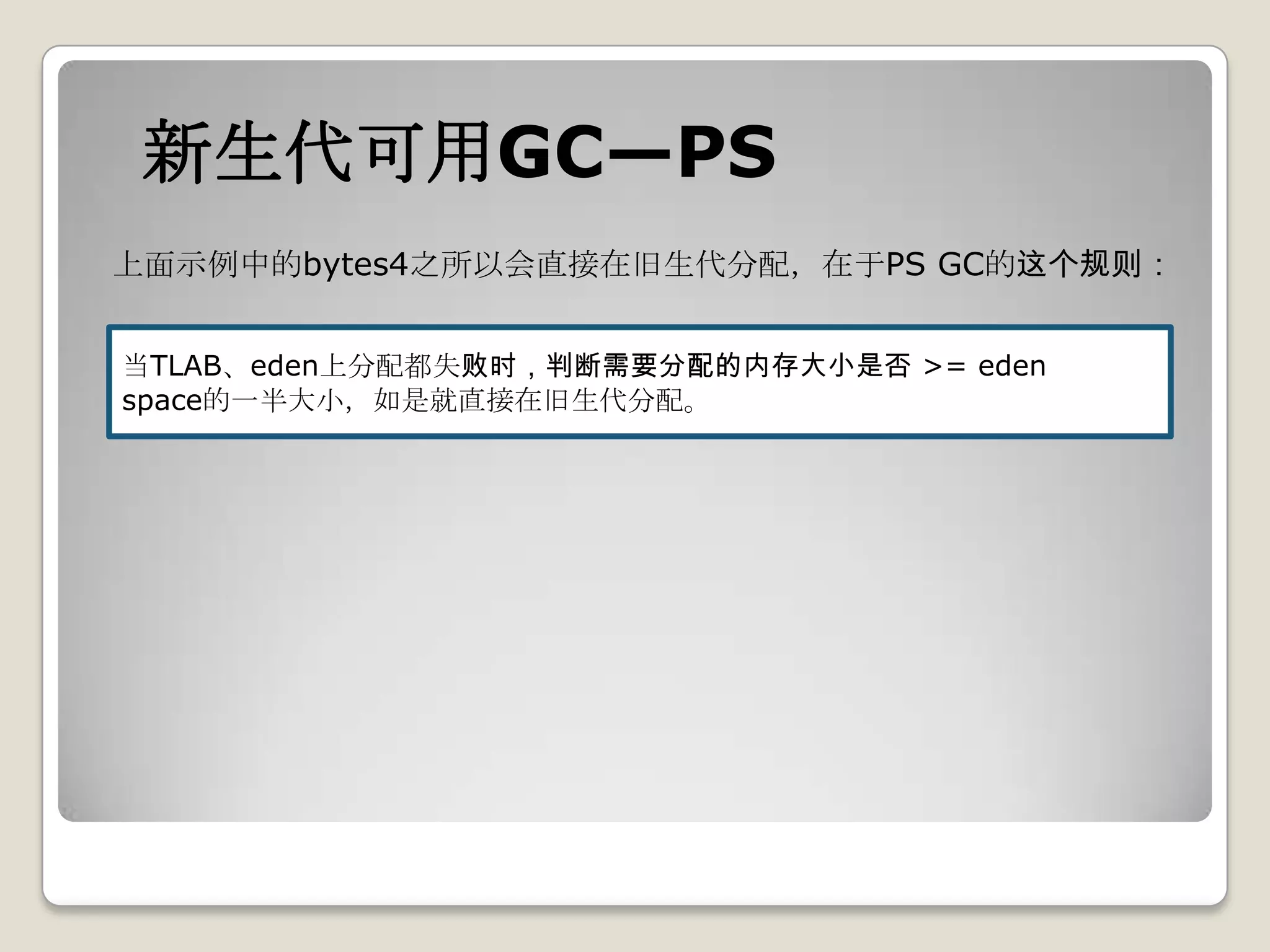
![新生代可用GC—PS
eden space分配不下,且需要分配的对象大小未超过eden space的一半或old区分配失败,
触发回收;
public class PSGCDemo{
public static void main(String[] args) throws Exception{
byte[] bytes=new byte[1024*1024*2];
byte[] bytes2=new byte[1024*1024*2];
byte[] bytes3=new byte[1024*1024*2];
System.out.println(“step 1");
byte[] bytes4=new byte[1024*1024*2];
Thread.sleep(3000);
System.out.println(“step 2");
byte[] bytes5=new byte[1024*1024*2];
byte[] bytes6=new byte[1024*1024*2];
System.out.println(“step 3");
byte[] bytes7=new byte[1024*1024*2];
Thread.sleep(3000);
}
}
-Xms20M –Xmx20M –Xmn10M –XX:SurvivorRatio=8 –XX:+UseParallelGC
-XX:+PrintGCDetails –XX:verbose:gc](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-29-2048.jpg)


![新生代可用GC—PS
[GC [PSYoungGen: 11509K->1184K(14336K)] 11509K-
>1184K(38912K), 0.0113360 secs]
[Times: user=0.03 sys=0.01, real=0.01 secs]](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-33-2048.jpg)



![旧生代可用GC—串行
[Full GC [Tenured: 9216K->4210K(10240K), 0.0066570 secs]
16584K->4210K(19456K), [Perm : 1692K-
>1692K(16384K)], 0.0067070 secs]
[Times: user=0.00 sys=0.00, real=0.01 secs]](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-37-2048.jpg)


![旧生代可用GC—并行MSC
[Full GC [PSYoungGen: 1208K->0K(8960K)] [PSOldGen: 6144K-
>7282K(10240K)] 7352K->7282K(19200K) [PSPermGen: 1686K-
>1686K(16384K)], 0.0165880 secs] [Times: user=0.01
sys=0.01, real=0.02 secs]](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-40-2048.jpg)


![旧生代可用GC—并行Compacting
[Full GC [PSYoungGen: 1224K->0K(8960K)] [ParOldGen: 6144K-
>7282K(10240K)] 7368K->7282K(19200K) [PSPermGen: 1686K-
>1685K(16384K)], 0.0223510 secs] [Times: user=0.02
sys=0.06, real=0.03 secs]](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-43-2048.jpg)


![旧生代可用GC—并发
public class CMSGCOccur{
public static void main(String[] args) throws Exception{
byte[] bytes=new byte[1024*1024*2];
byte[] bytes1=new byte[1024*1024*2];
byte[] bytes2=new byte[1024*1024*2];
byte[] bytes3=new byte[1024*1024*1];
byte[] bytes4=new byte[1024*1024*2];
Thread.sleep(5000);
}
}
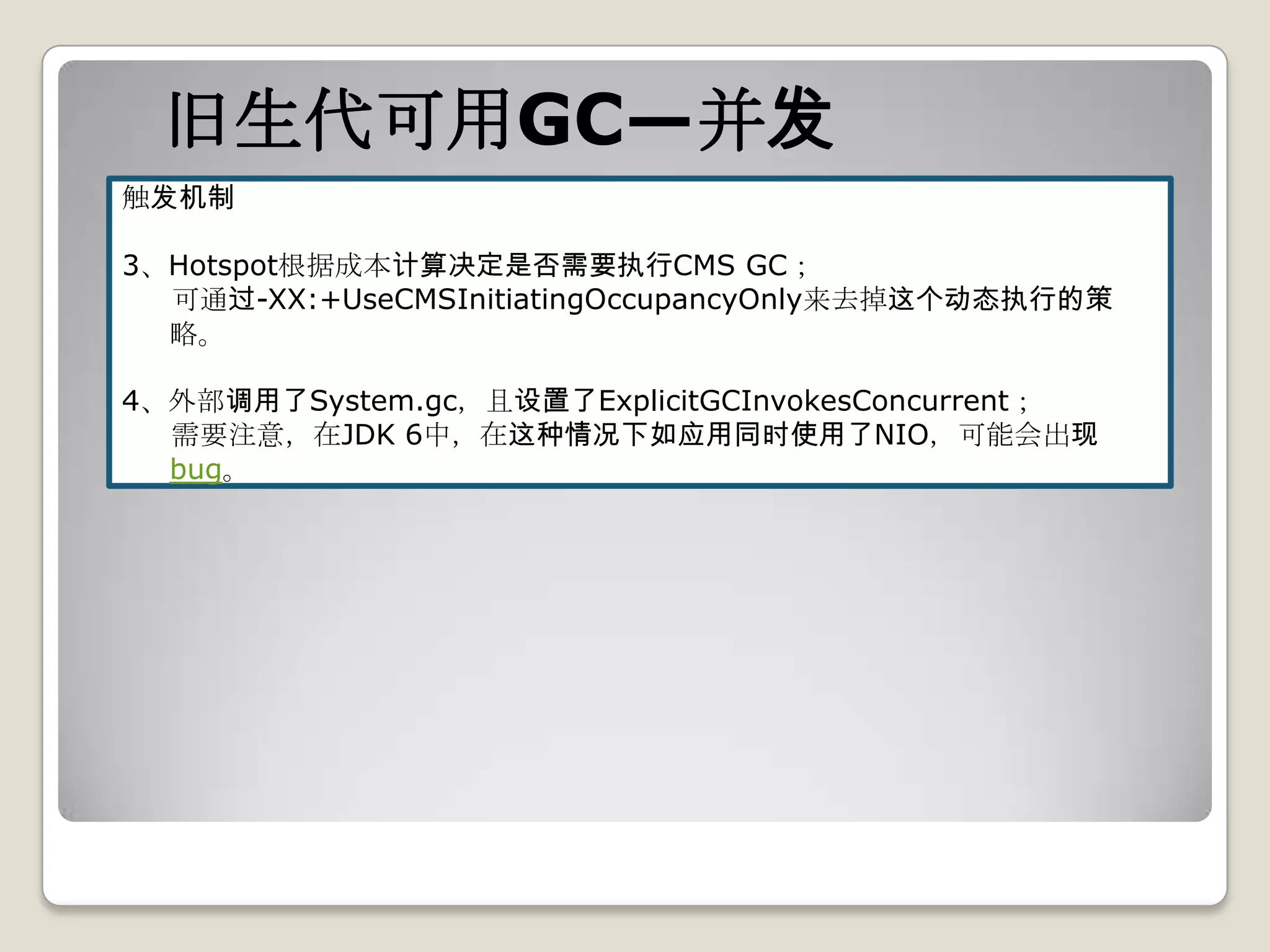
-Xms20M –Xmx20M –Xmn10M -XX:+UseConcMarkSweepGC -
XX:+UseCMSInitiatingOccupancyOnly -XX:+PrintGCDetails
-Xms20M –Xmx20M –Xmn10M -XX:+UseConcMarkSweepGC -
XX:+PrintGCDetails](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-47-2048.jpg)

![旧生代可用GC—并发
[GC [1 CMS-initial-mark: 13433K(20480K)] 14465K(29696K), 0.0001830 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
[CMS-concurrent-mark: 0.004/0.004 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
[CMS-concurrent-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
CMS: abort preclean due to time [CMS-concurrent-abortable-preclean: 0.007/5.042 secs]
[Times: user=0.00 sys=0.00, real=5.04 secs]
[GC[YG occupancy: 3300 K (9216 K)][Rescan (parallel) , 0.0002740 secs]
[weak refs processing, 0.0000090 secs]
[1 CMS-remark: 13433K(20480K)] 16734K(29696K), 0.0003710 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
[CMS-concurrent-sweep: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
当在启动参数上设置了-XX:+UseAdaptiveSizePolicy后,上面的日志中的CMS会变为ASCMS
CMS GC Log解读](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-49-2048.jpg)




![OOM(一些代码造成OOM的例子)
Java Heap OOM产生的原因是在多次gc后仍然分配不了,具体策略取决于这三个
参数:
-XX:+UseGCOverheadLimit -XX:GCTimeLimit=98 –XX:GCHeapFreeLimit=2
1、OOM的前兆通常体现在每次Full GC后旧生代的消耗呈不断上涨趋势;
查看方法:jstat –gcutil [pid] [intervel] [count]
2、解决方法
dump多次Full GC后的内存消耗状况,方法:
jmap –dump:format=b,file=[filename] [pid]
dump下来的文件可用MAT进行分析,简单视图分析:MAT Top Consumers
或在启动参数上增加:-XX:+HeapDumpOnOutOfMemoryError,当OOM
时会在工作路径(或通过-XX:HeapDumpPath来指定路径)下生成
java_[pid].hprof文件。
还有Native Heap造成的OOM,堆外内存使用过多。](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-55-2048.jpg)
![GC监测
1、jstat –gcutil [pid] [intervel] [count]
2、-verbose:gc // 可以辅助输出一些详细的GC信息
-XX:+PrintGCDetails // 输出GC详细信息
-XX:+PrintGCApplicationStoppedTime // 输出GC造成应用暂停的时间
-XX:+PrintGCDateStamps // GC发生的时间信息
-XX:+PrintHeapAtGC // 在GC前后输出堆中各个区域的大小
-Xloggc:[file] // 将GC信息输出到单独的文件中
gc的日志拿下来后可使用GCLogViewer或gchisto进行分析。
3、图形化的情况下可直接用jvisualvm进行分析。](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-56-2048.jpg)








![case 2 – 场景
4 cpu,os: linux 2.6.18 32 bit
启动参数
◦ -server -Xms1536m -Xmx1536m –Xmn700m
在系统运行到67919.837秒时发生了一次Full GC,日志信息
如下:
67919.817: [GC [PSYoungGen: 588706K->70592K(616832K)]
1408209K->906379K(1472896K),
0.0197090 secs] [Times: user=0.06 sys=0.00,
real=0.02 secs]
67919.837: [Full GC [PSYoungGen: 70592K->0K(616832K)]
[PSOldGen: 835787K->375316K(856064K)]
906379K->375316K(1472896K)
[PSPermGen: 64826K->64826K(98304K)],
0.5478600 secs]
[Times: user=0.55 sys=0.00, real=0.55 secs]](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-65-2048.jpg)

![case 2 – 场景
在68132.893时又发生了一次Full GC,日志信息如下:
◦ 68132.862: [GC [PSYoungGen: 594736K-
>63715K(609920K)] 1401225K->891090K(1465984K),
0.0309810 secs] [Times: user=0.06
sys=0.01, real=0.04 secs]
◦ 68132.893: [Full GC [PSYoungGen: 63715K-
>0K(609920K)]
[PSOldGen: 827375K->368026K(856064K)]
891090K->368026K(1465984K)
[PSPermGen: 64869K-
>64690K(98304K)], 0.5341070 secs]
[Times: user=0.53 sys=0.00, real=0.53
secs]
之后的时间的GC基本也在重复上述过程。](https://image.slidesharecdn.com/sun-jdk-1-6-gc-120410073557-phpapp02/75/Sun-jdk-1-6-gc-67-2048.jpg)