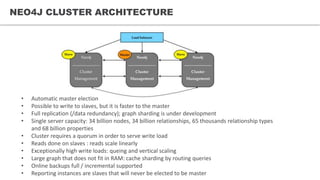
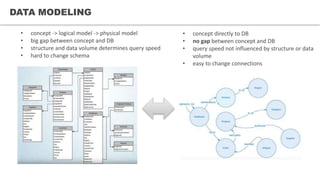
This document discusses graph databases and provides examples using Neo4j. It begins by explaining some of the limitations of relational databases for certain types of queries on social network and recommendation system data. It then provides basics on graph data models and examples of creating and querying graph data using the Cypher query language in Neo4j. It also discusses Neo4j's architecture, development, and resources.





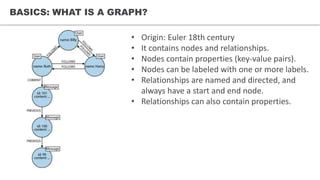

![CYPHER – GRAPH DATABASE QUERY LANGUAGE
Name:
Joe
Name:
Bob
FRIEND
Person Person
(:Person{name:”Joe”})-[:FRIEND]->(:Person{name:”Bob”})
• Other query languages: SPARQL, Gremlin ...
• Case sensitive
• Most human friendly](https://image.slidesharecdn.com/neo4jv2-161104133032/85/Neo4j-20-minutes-introduction-10-320.jpg)
![CREATING SOME TEST DATA IN CYPHER
// creating nodes
create(:Person{name:"Tom Hanks"});
....
// creating relation between two specific nodes
match (a:Person),(b:Movie)
where
a.name='Ron Howard'
and b.title = 'The Da Vinci Code'
create (a)-[r:DIRECTED]->(b) return r;
....
// set relation property
match(Person{name:"Tom Hanks"})-[n:KNOWS]->
(Person{name:„Ron Howard"}) set n.since=1987;
....
// delete relation
match (a)-[r:KNOWS]->(b)
where
a.name='Matt Damon'
and b.name='Matt Damon'
delete r;](https://image.slidesharecdn.com/neo4jv2-161104133032/85/Neo4j-20-minutes-introduction-11-320.jpg)
![QUERYING DATA IN CYPHER
// whom does Tom Hanks know?
match (:Person{name:"Tom Hanks"})-[r:KNOWS]->(b) return b;
// who knows Steven Spielberg?
match (:Person{name:"Steven Spielberg"})<-[:KNOWS]-(b) return b;
// which films has Tom Hanks Acted in?
match (:Person{name:"Tom Hanks"})-[:ACTED_IN]-(b) return b;
// delete by id
match (n) where ID(n)=11 delete n;
// get Steven Spielberg aquantances 3 levels deep
match (:Person{name:"Steven Spielberg"})
-[:KNOWS]-(b)
-[:KNOWS]-(c)
-[:KNOWS]-(d)
return b, c, d](https://image.slidesharecdn.com/neo4jv2-161104133032/85/Neo4j-20-minutes-introduction-12-320.jpg)
![A BIGGER EXAMPLE
MATCH (tom:Person {name:"Tom Hanks"})
-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors)
RETURN tom, m, coActors
Tom Hanks’ co-actors:](https://image.slidesharecdn.com/neo4jv2-161104133032/85/Neo4j-20-minutes-introduction-13-320.jpg)
![FINDING THE SHORTEST PATH
MATCH p=shortestPath(
(kevin:Person {name:"Kevin Bacon"})-[*]-(meg:Person {name:"Meg Ryan"})
)
RETURN p
The shortest path between Kevin Bacon and Meg Ryan:](https://image.slidesharecdn.com/neo4jv2-161104133032/85/Neo4j-20-minutes-introduction-14-320.jpg)
![RECOMMENDING CO-ACTORS TO TOM HANKS
MATCH
// coActors: acted in the same movies as Tom
// cocoActors: acted in the same movies as coActors but they Tom did not
// act in the same movies as the coActors
(tom:Person {name:"Tom Hanks"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors),
(coActors)-[:ACTED_IN]->(m2)<-[:ACTED_IN]-(cocoActors)
WHERE NOT (tom)-[:ACTED_IN]->(m2)
RETURN
cocoActors.name AS Recommended,
// strength: how many times the same cocoActor was found
count(*) AS Strength ORDER BY Strength DESC
Find co-actors who haven't work with Tom Hanks (co-co-actors):
Tom
m
(movie)
ACTED_IN
coActor
ACTED_IN
m2
(movie)
ACTED_IN
cocoActor
ACTED_IN
ACTED_IN](https://image.slidesharecdn.com/neo4jv2-161104133032/85/Neo4j-20-minutes-introduction-15-320.jpg)