Downloaded 11 times








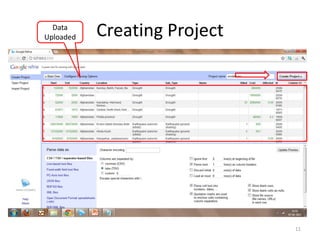

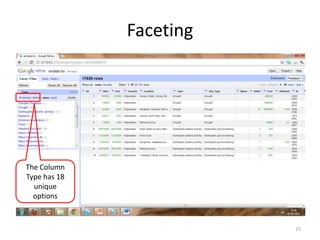
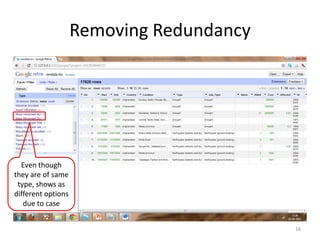
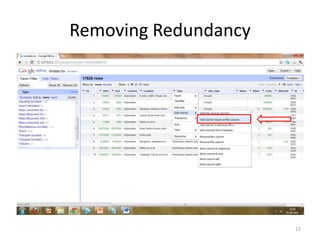
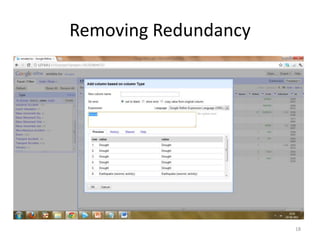
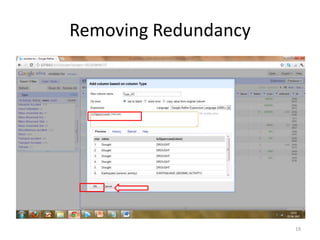
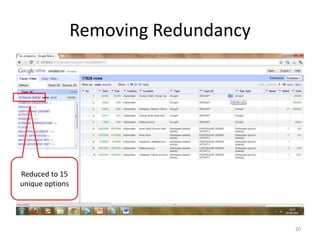
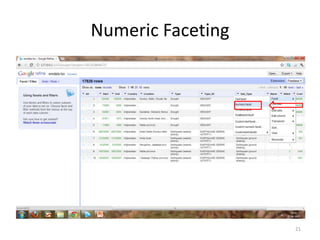
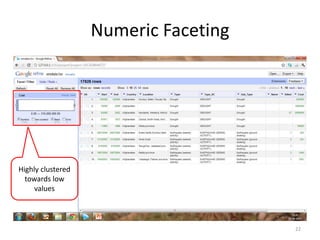
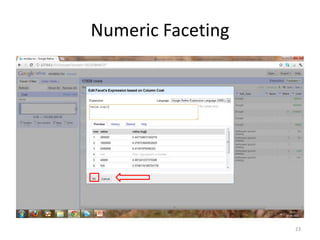
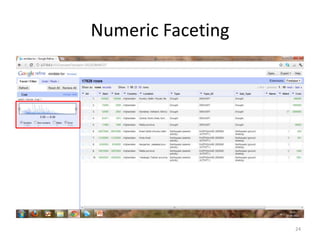
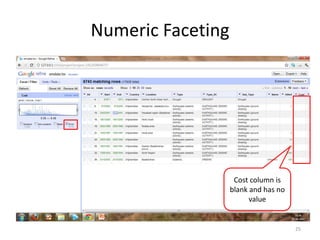
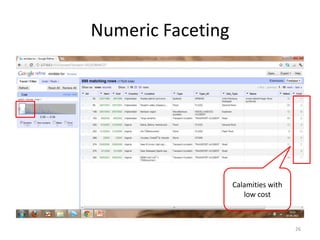
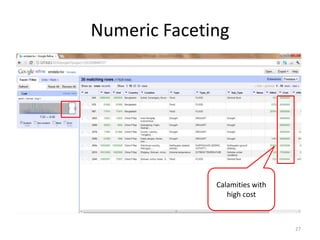
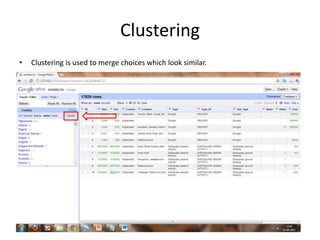
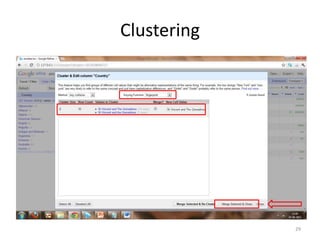
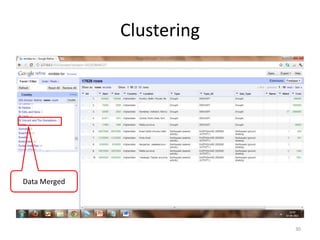
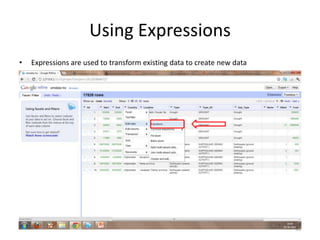
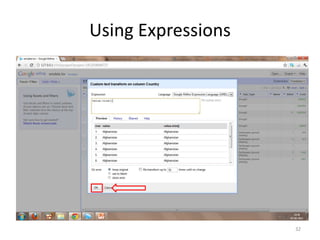
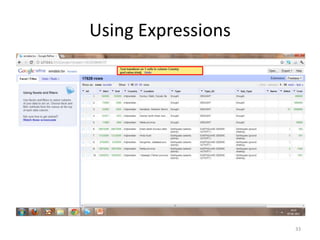

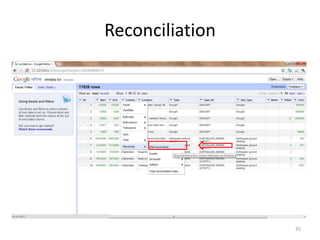
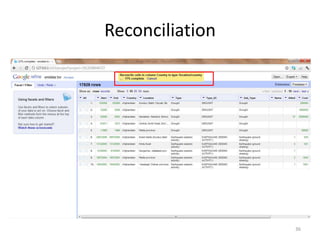
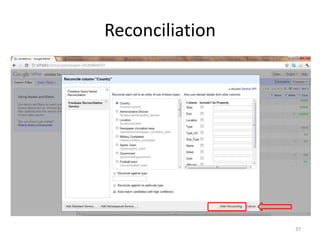


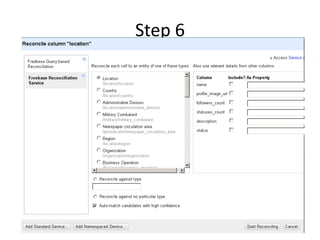

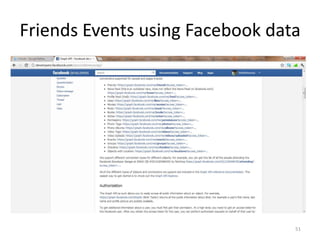
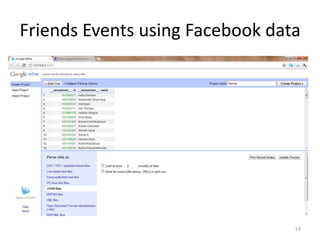
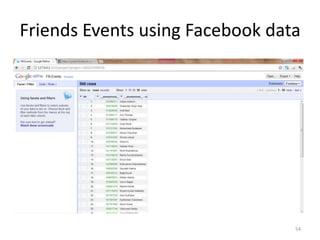
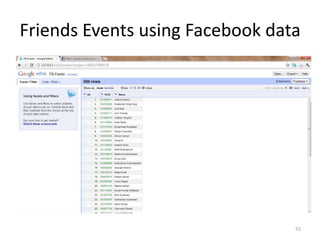
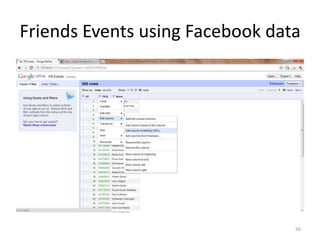

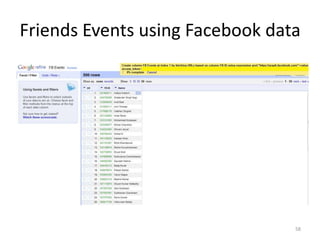
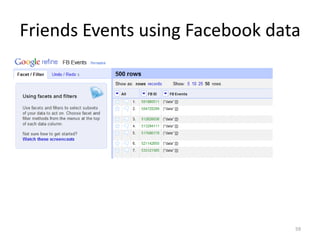
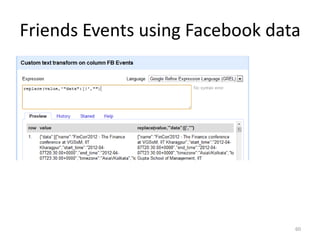
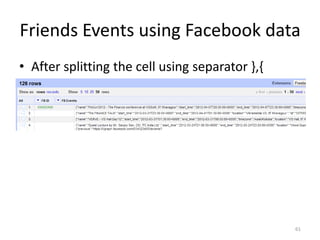
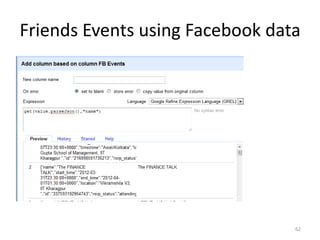
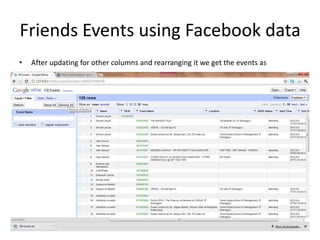
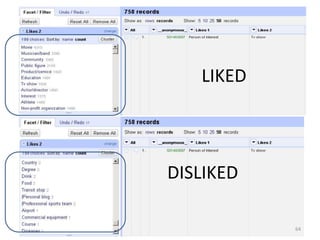


This tutorial demonstrates how to use Google Refine for data cleansing and enrichment. It shows how to import data, perform faceting to identify issues, remove redundancies, cluster similar values, use expressions to transform data, link data to external sources for augmentation, and export the refined data. Functions like numeric faceting, text faceting, and timeline faceting are covered. The tutorial also provides examples of using Refine to extract and structure information from Twitter and Facebook data.


























































