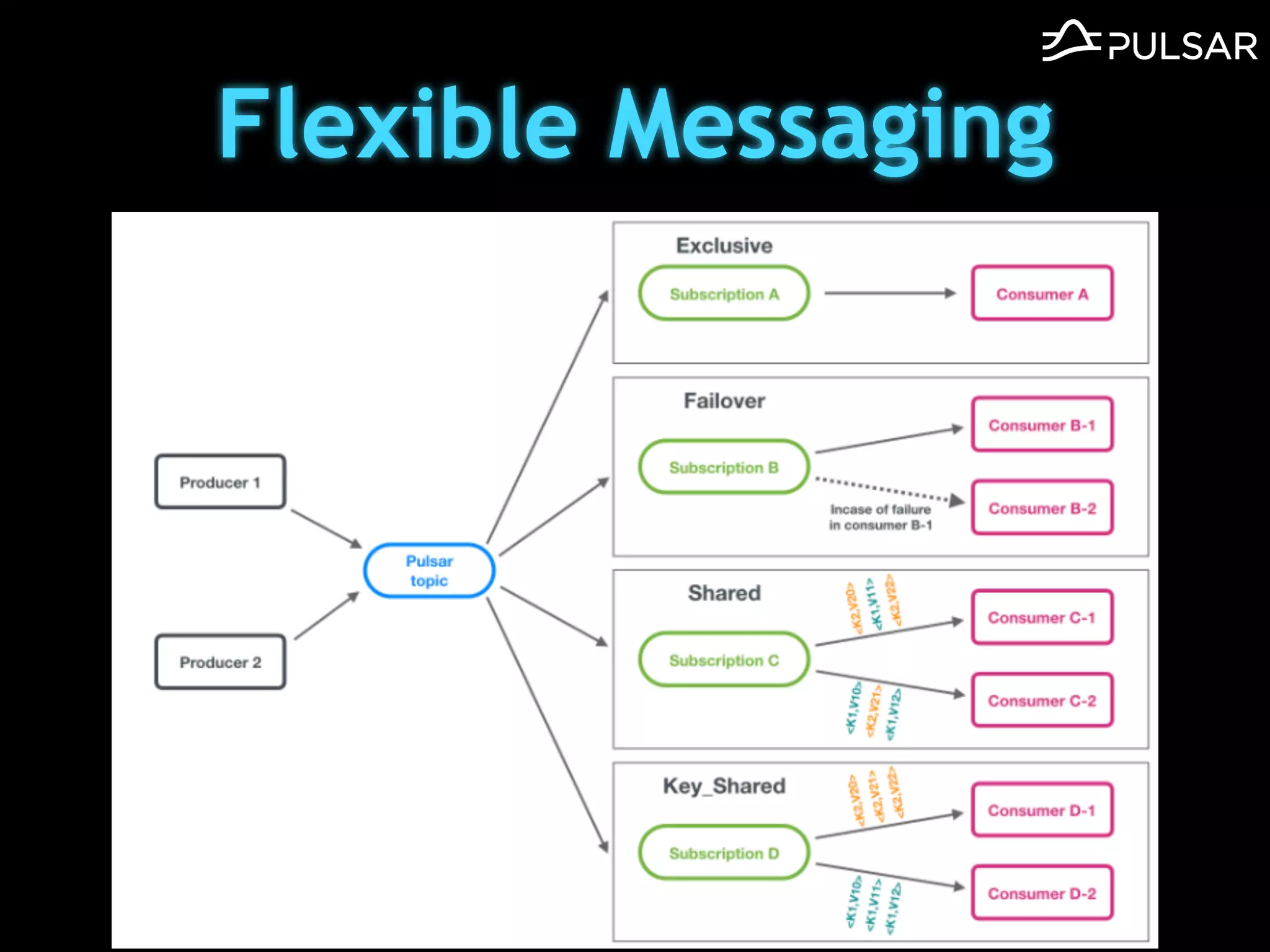
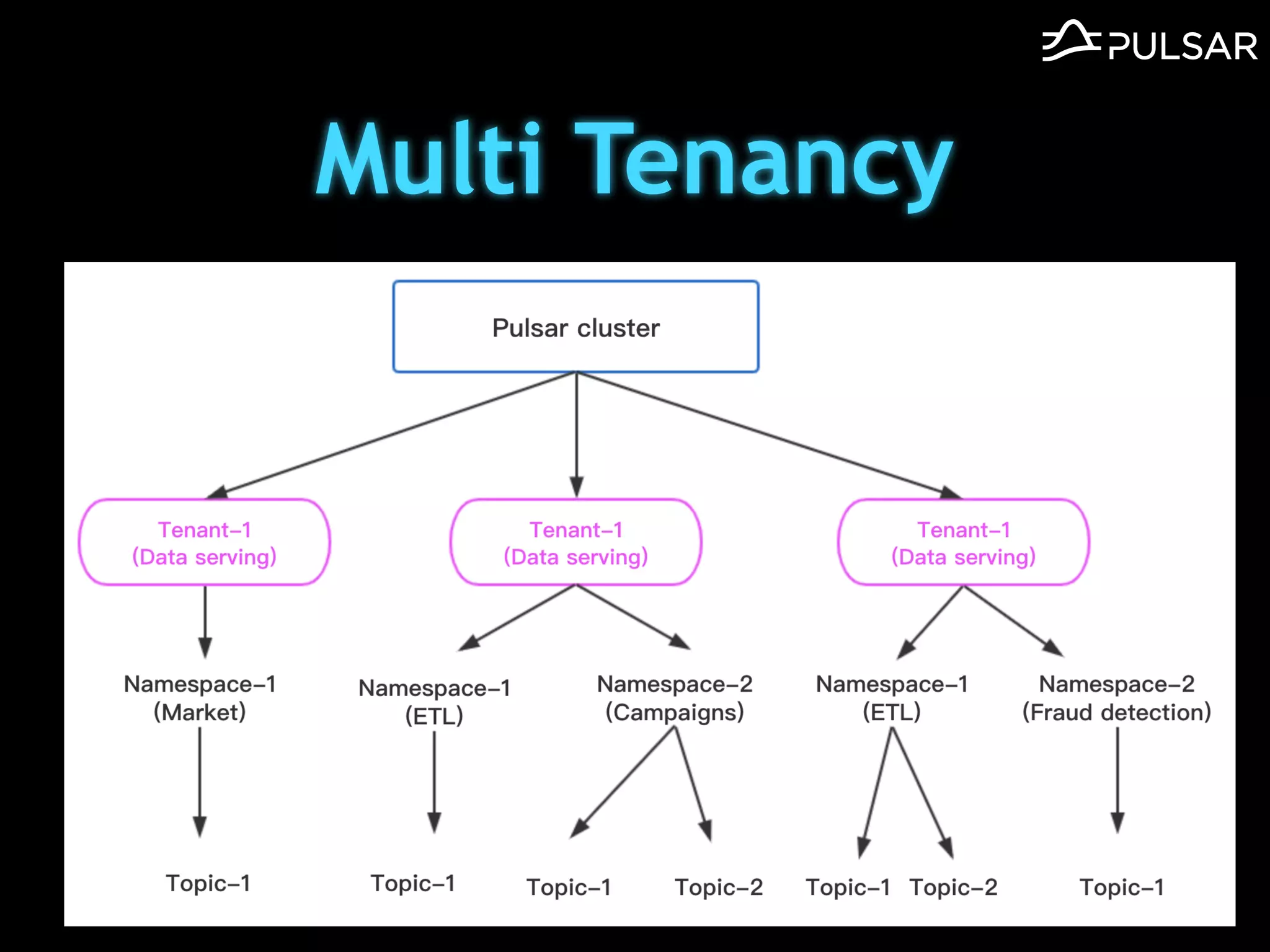
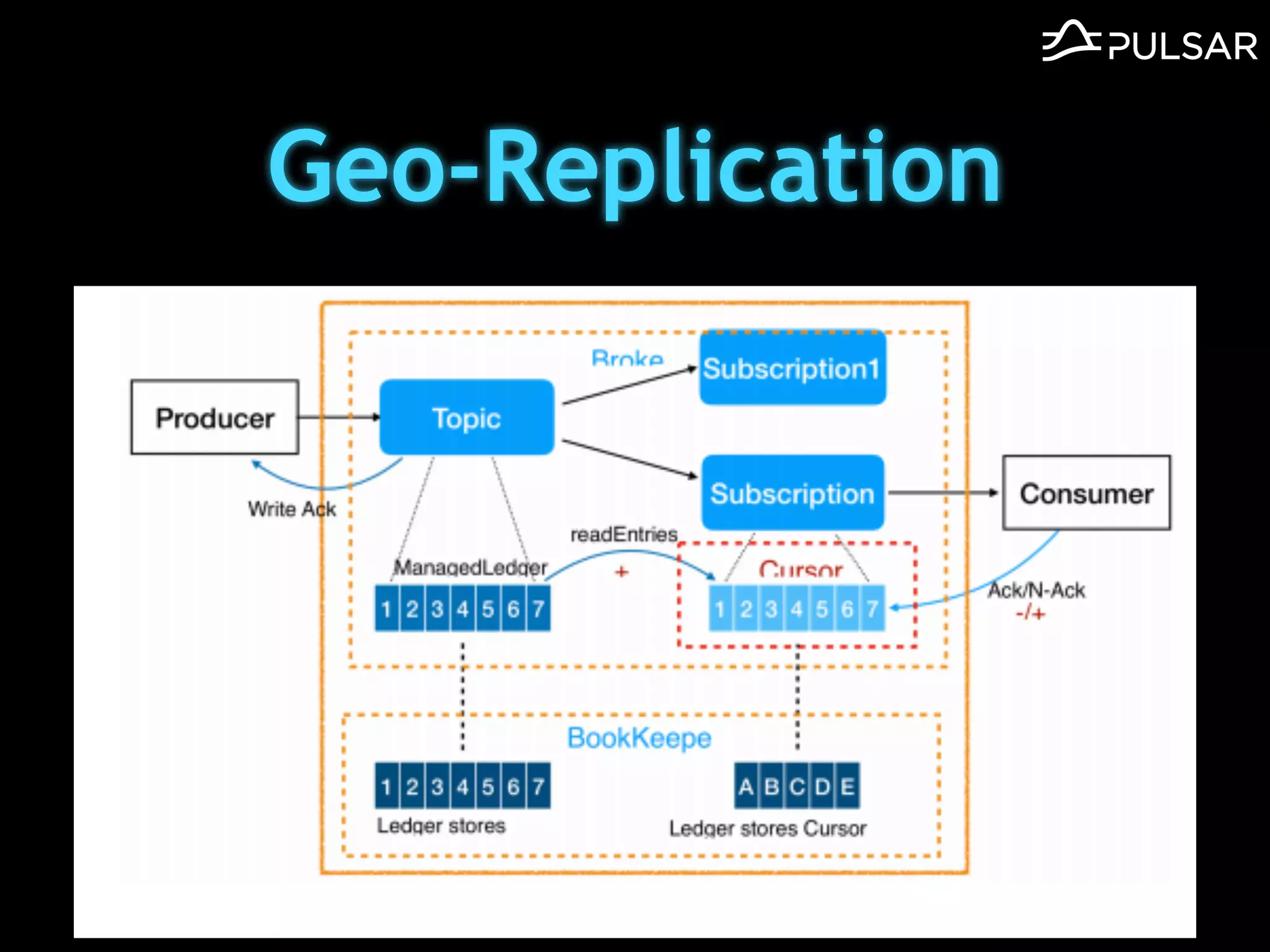
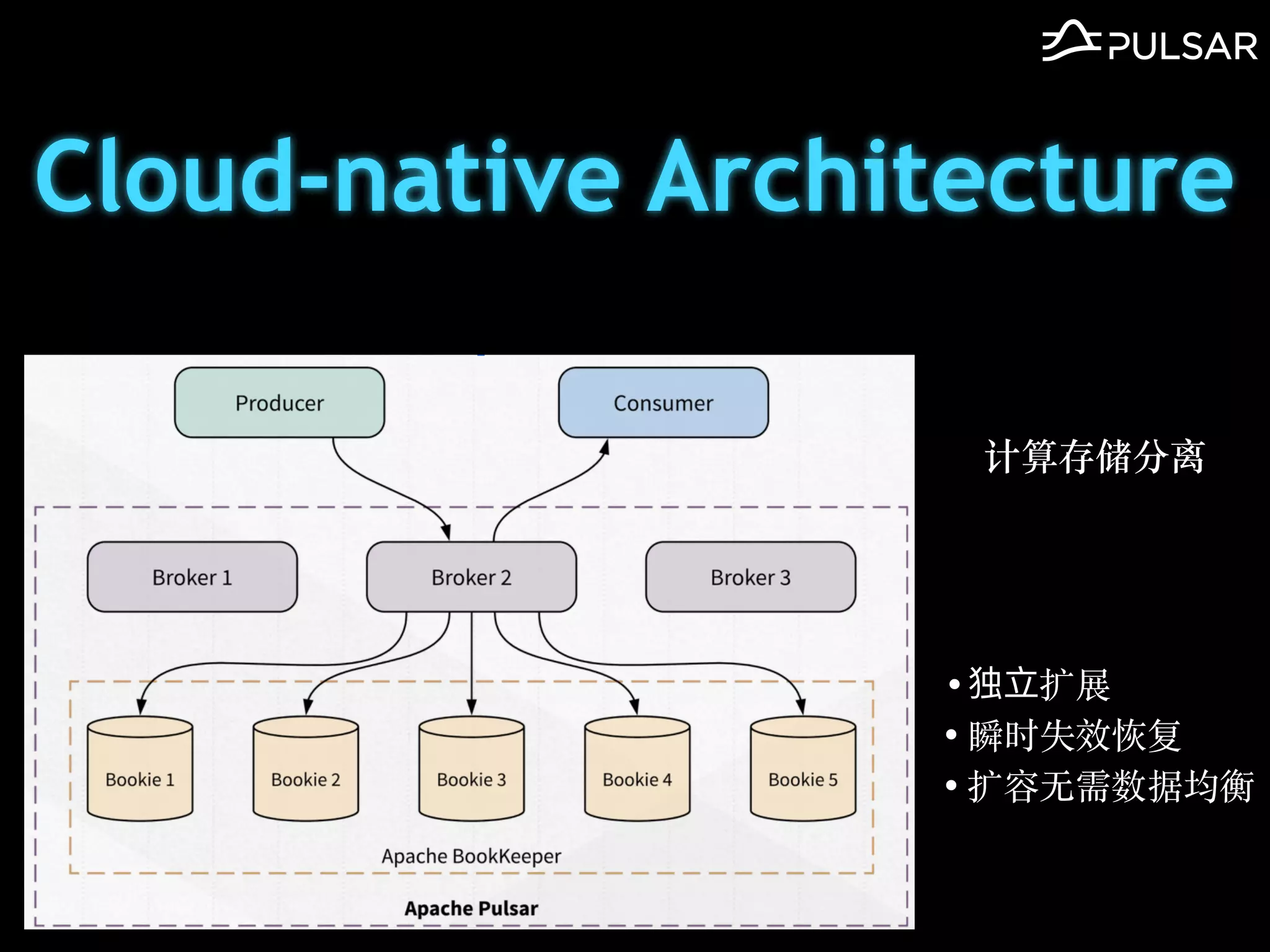
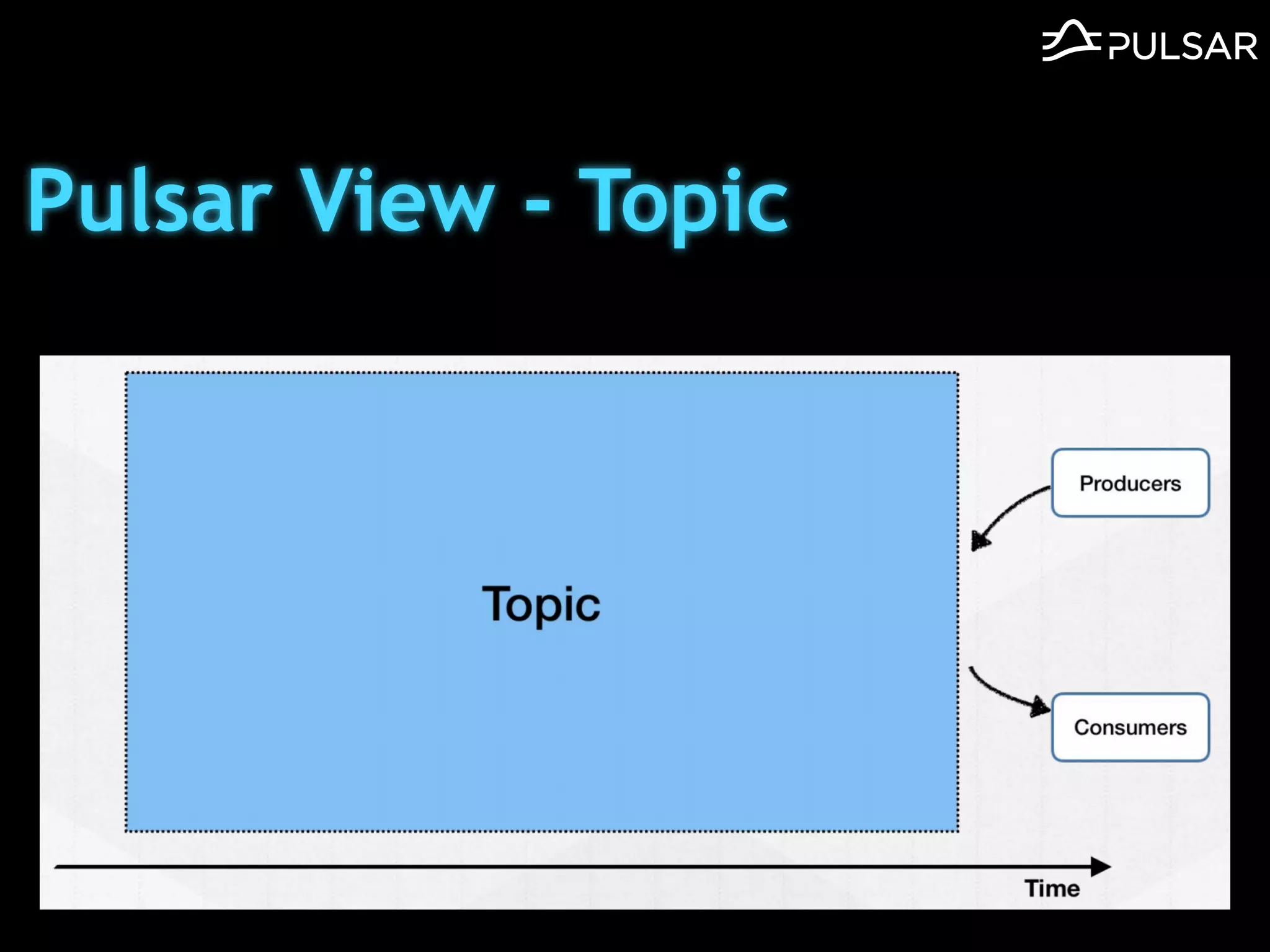
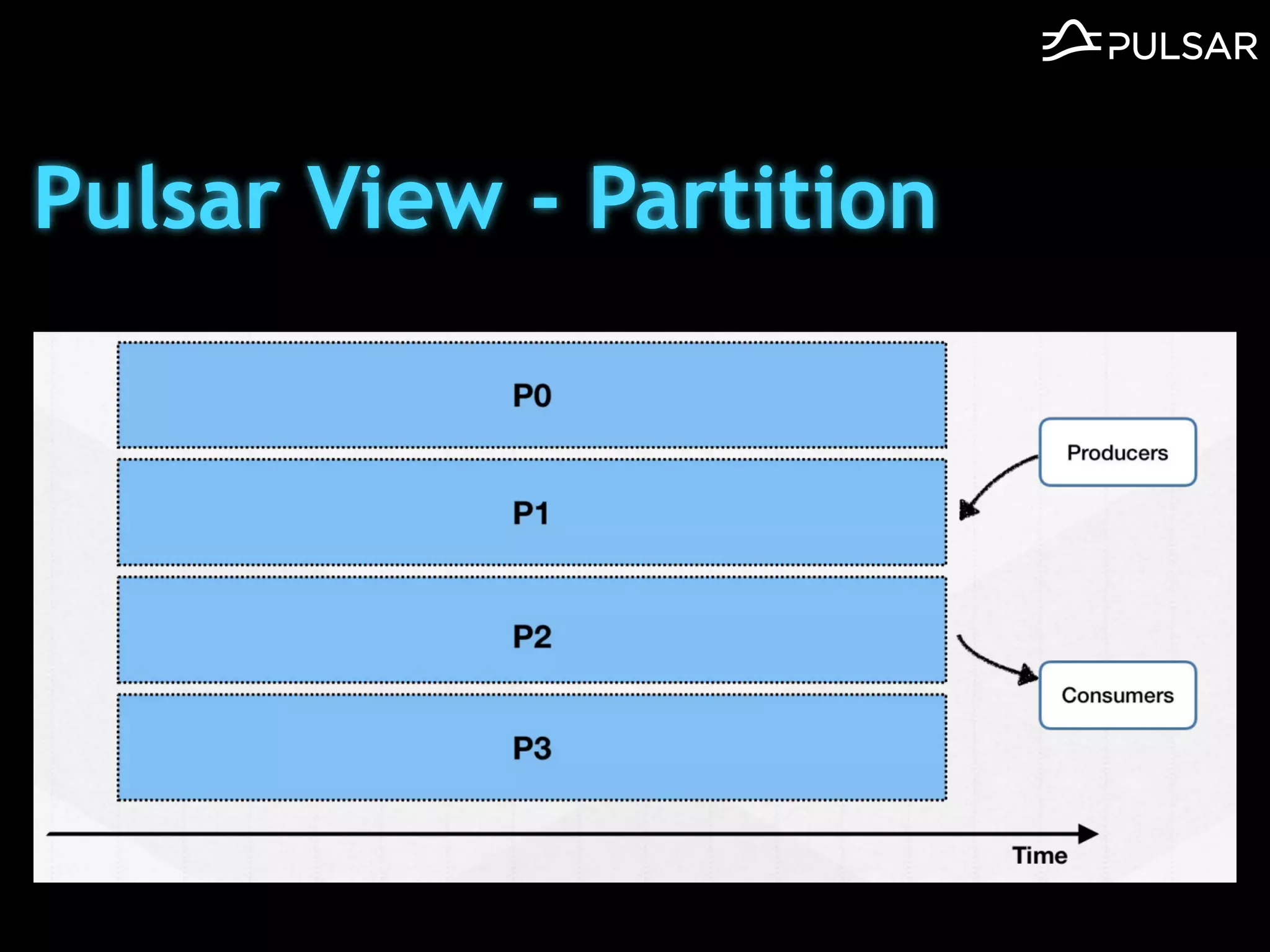
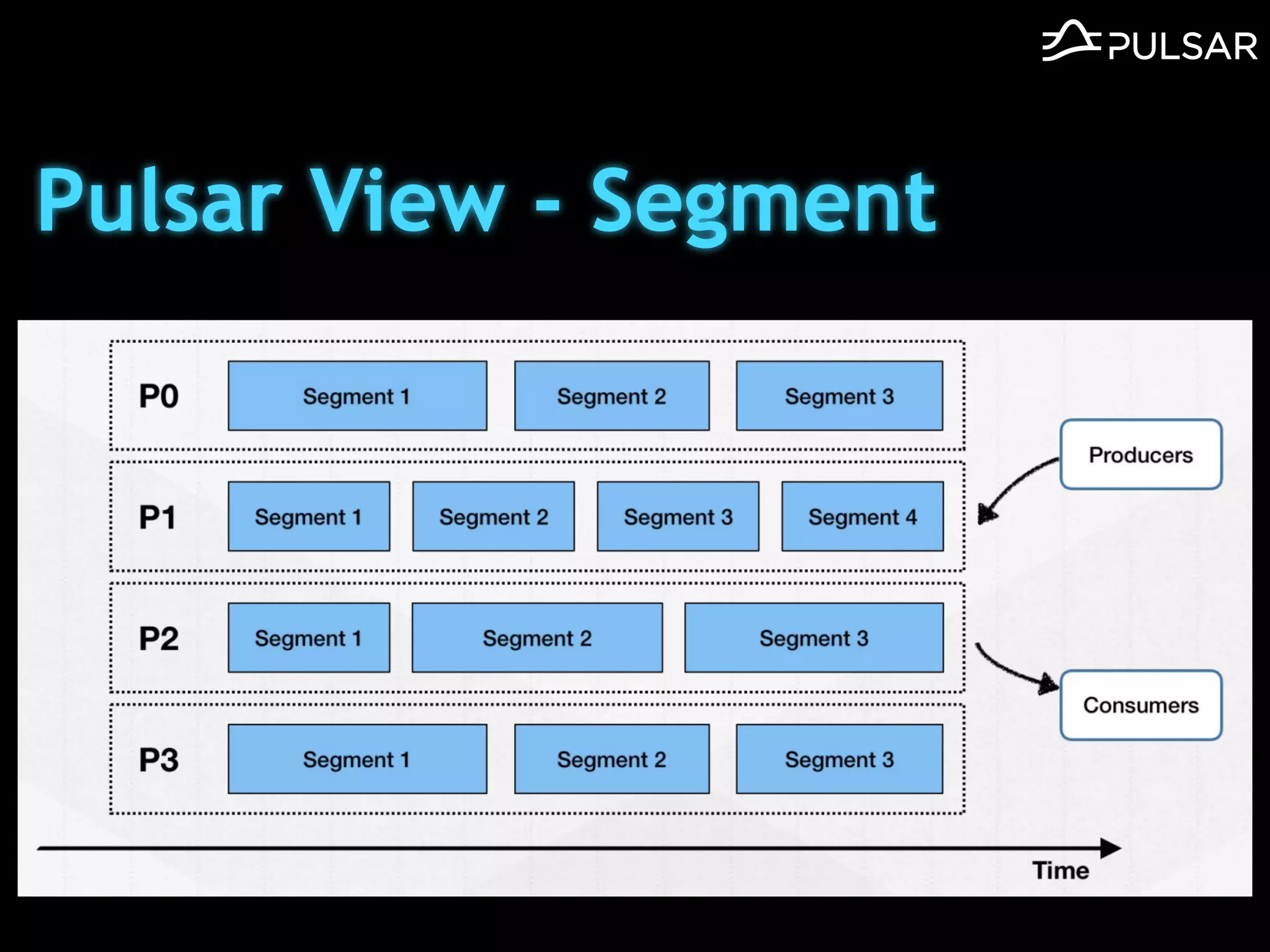
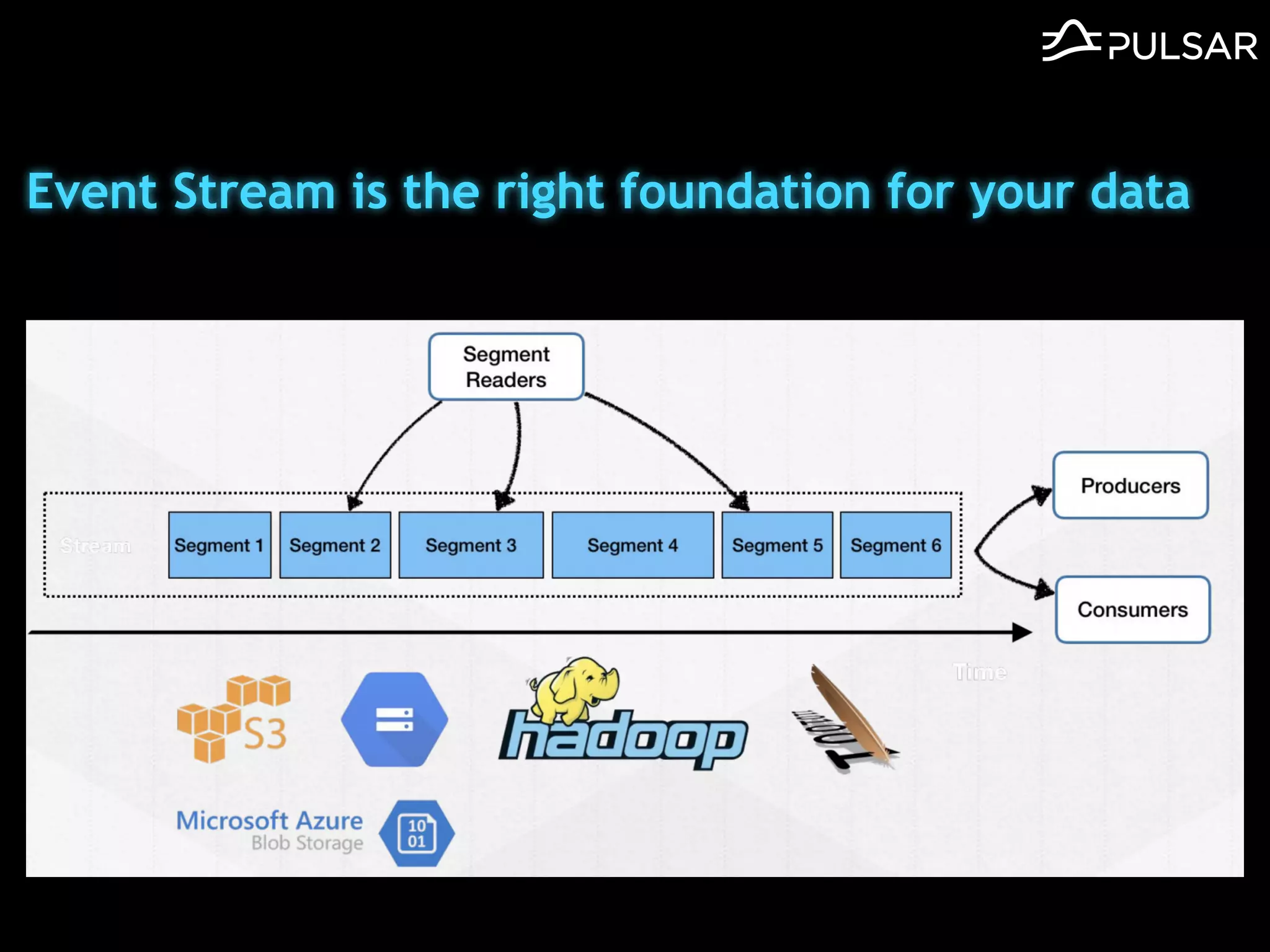
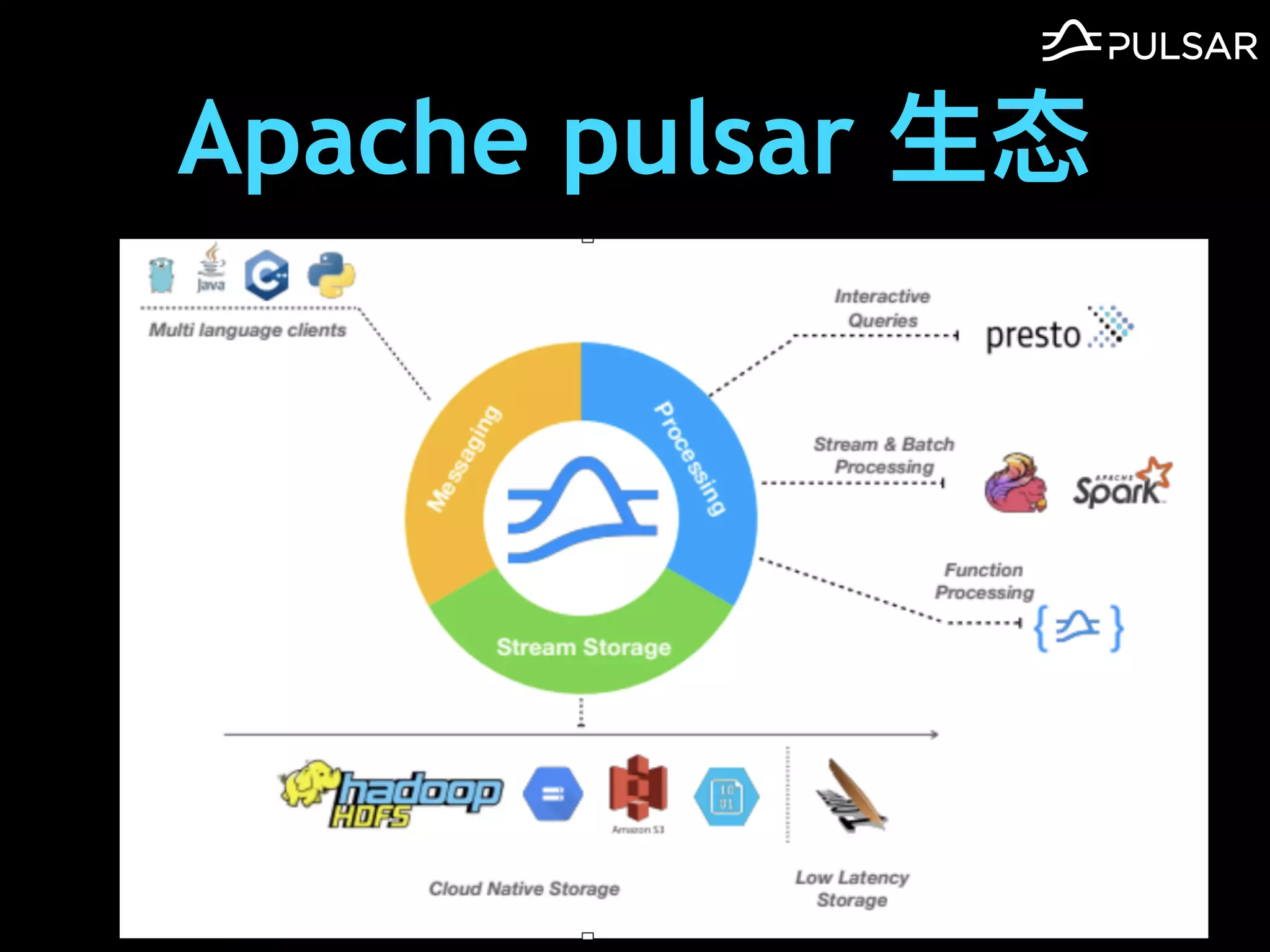
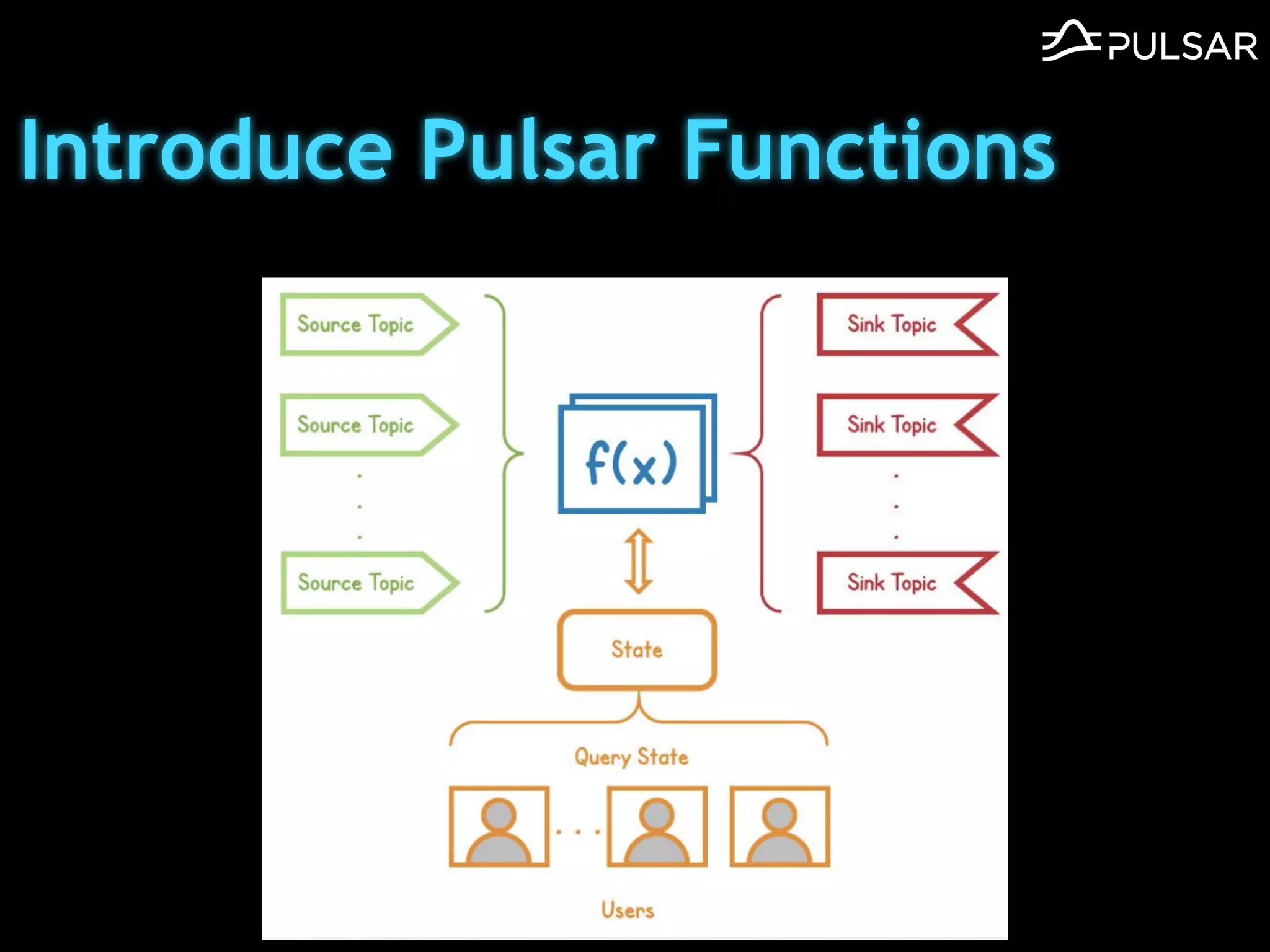
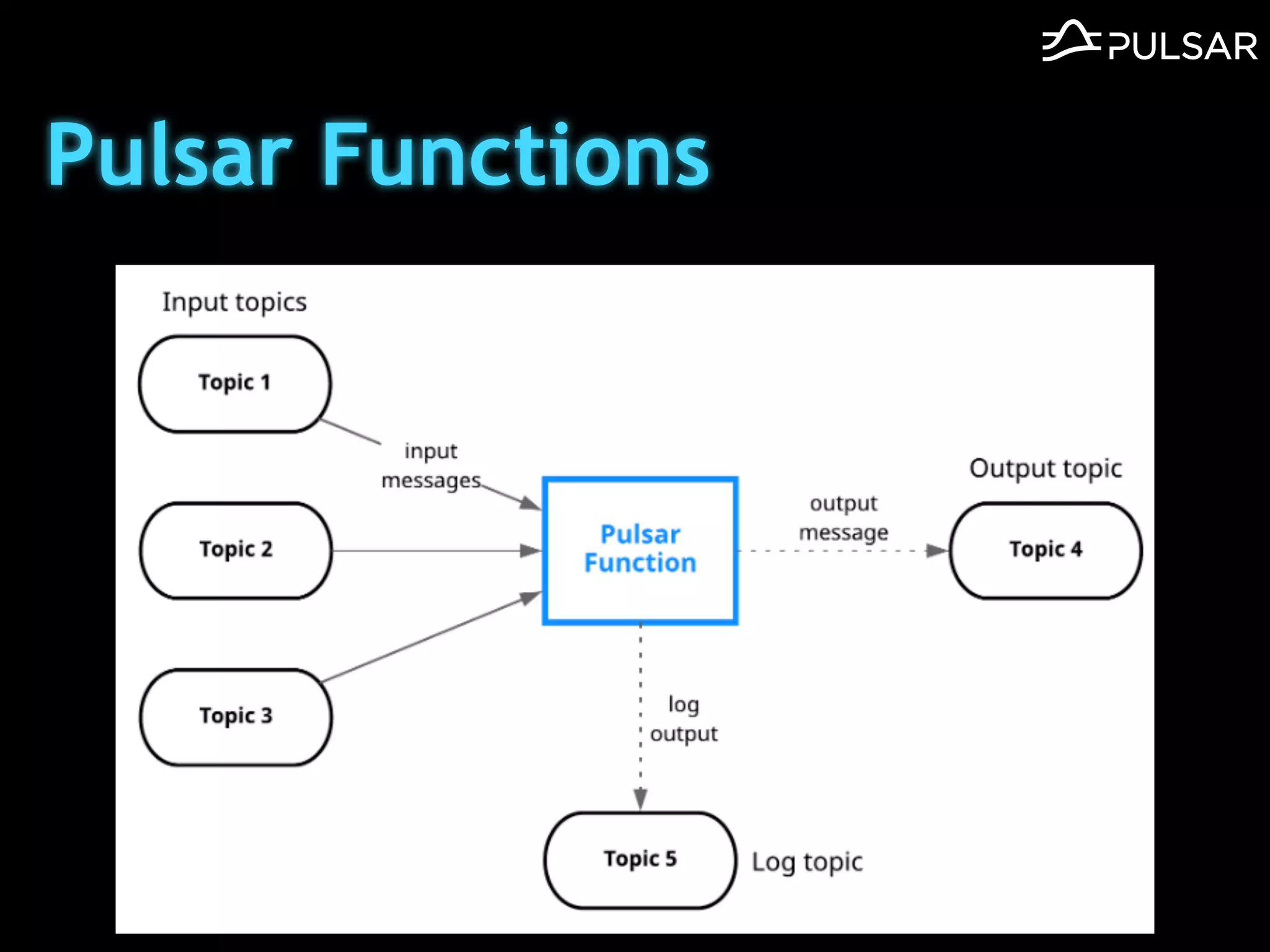
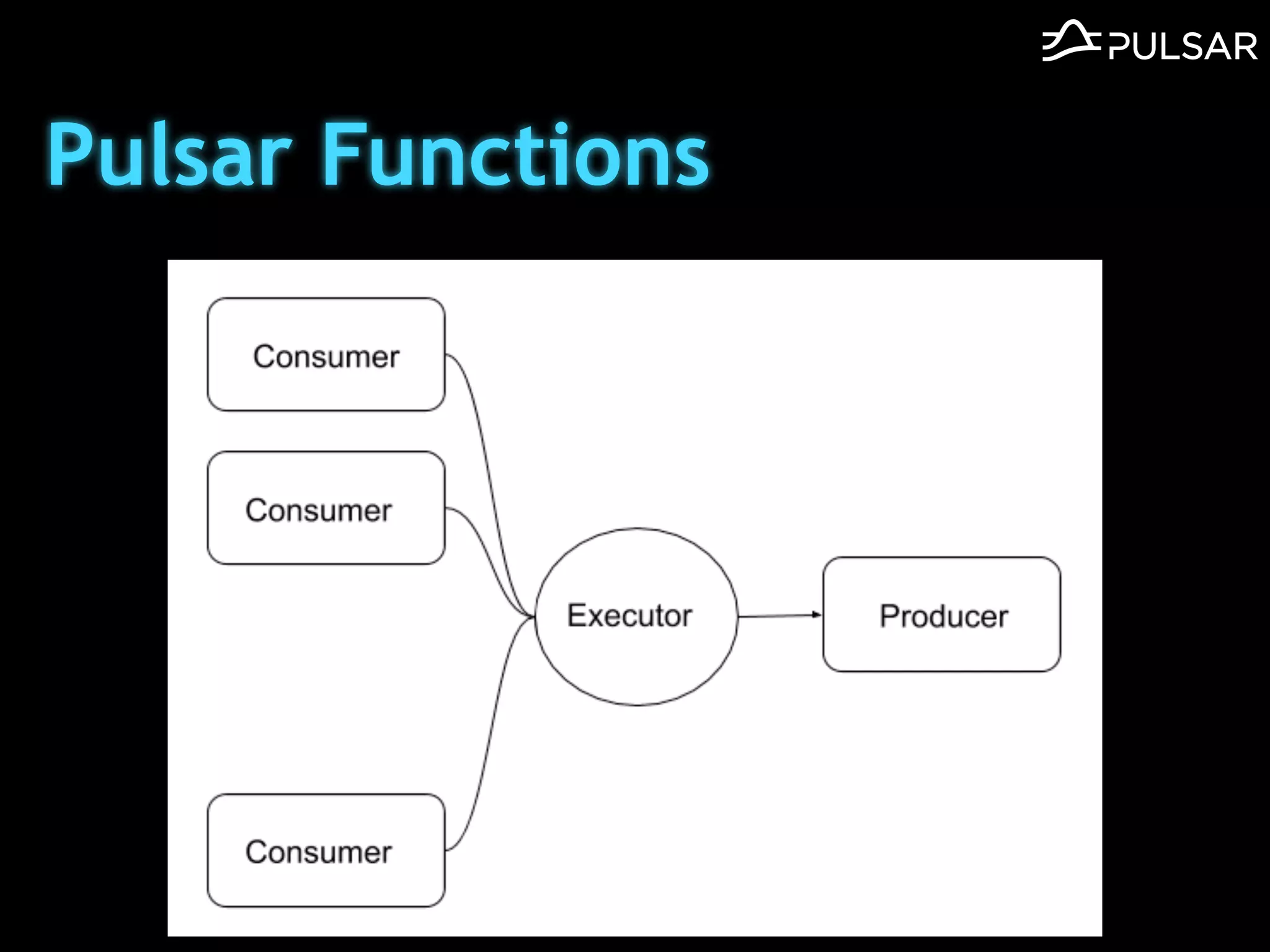
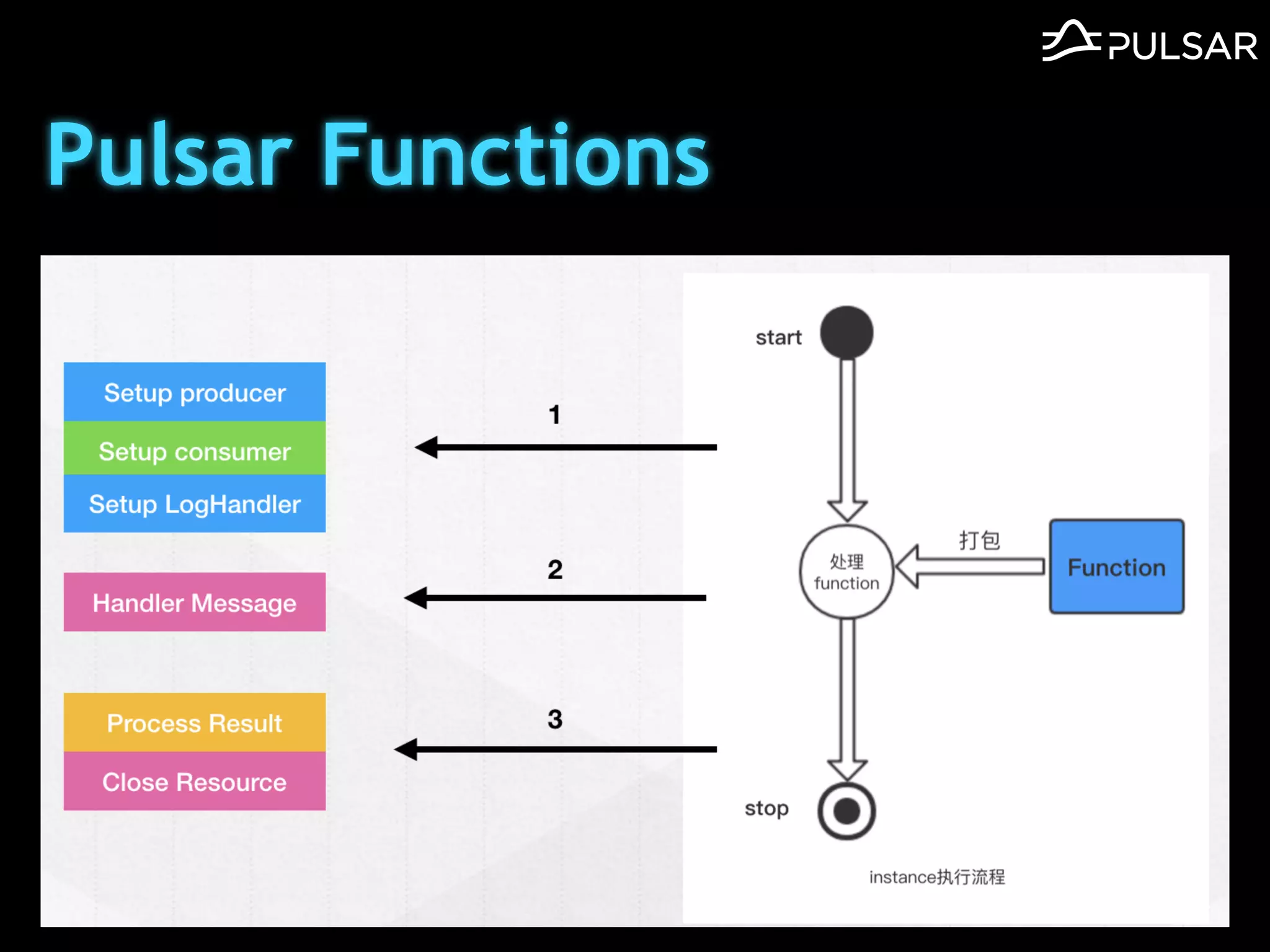
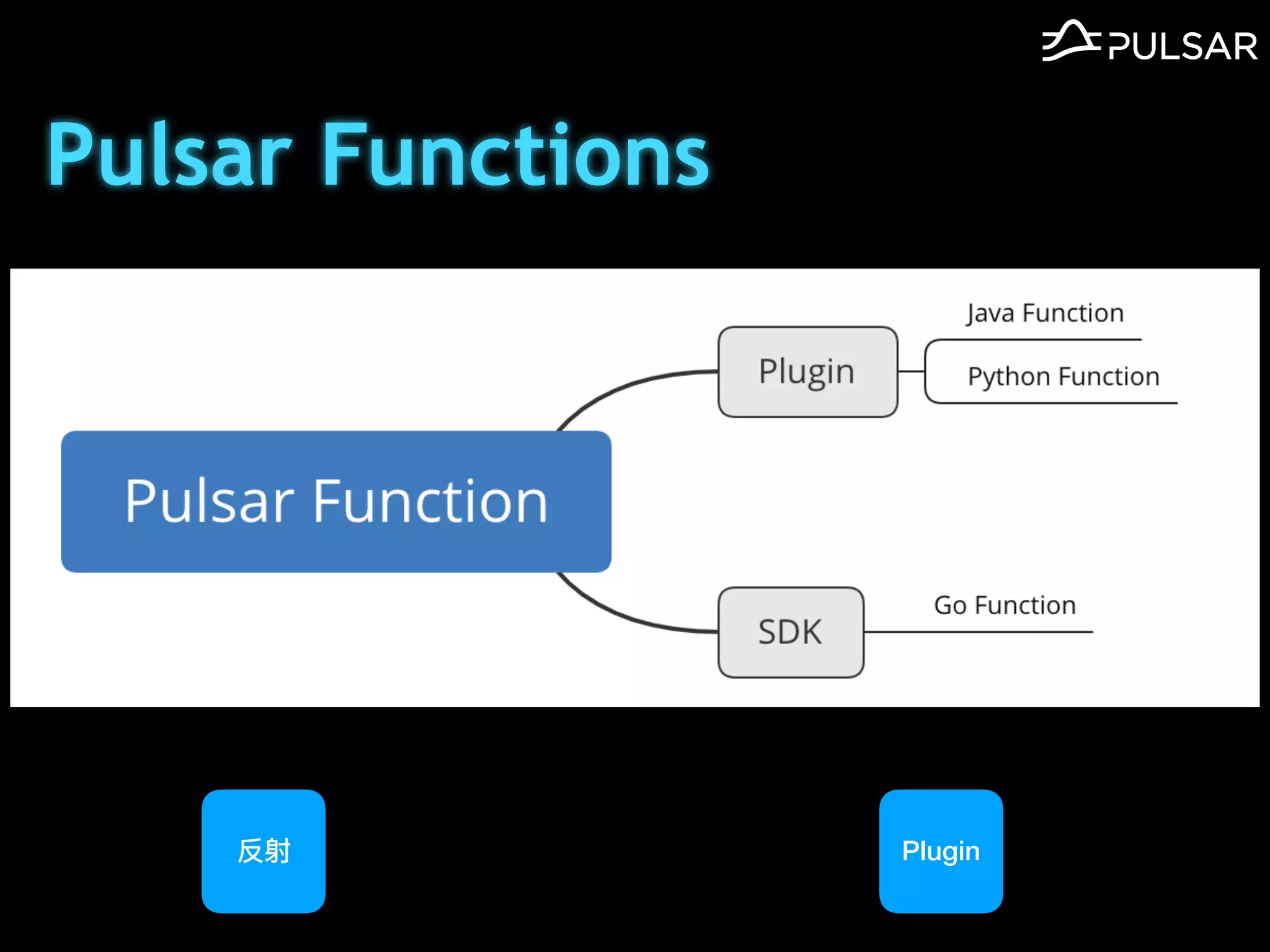
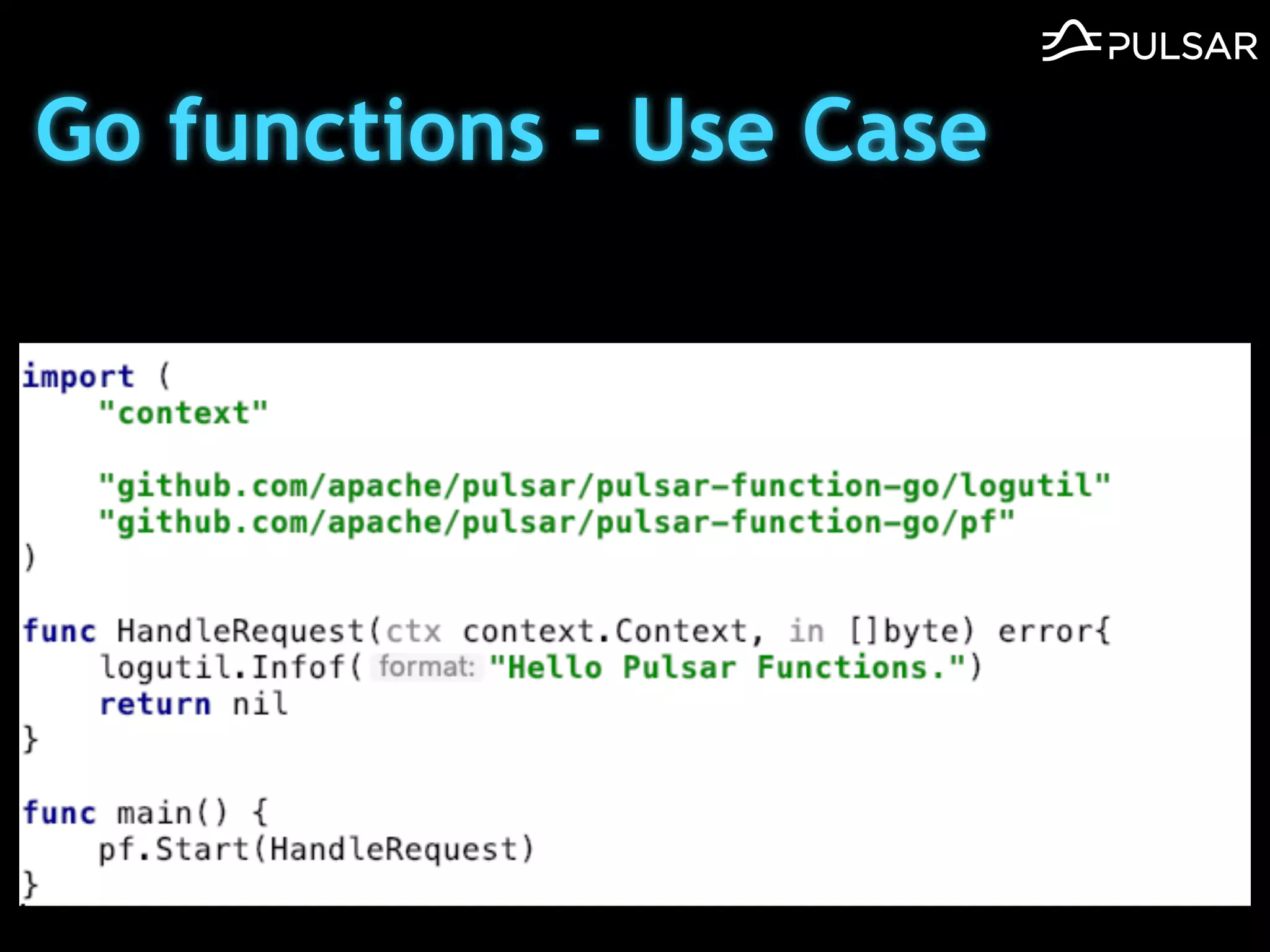
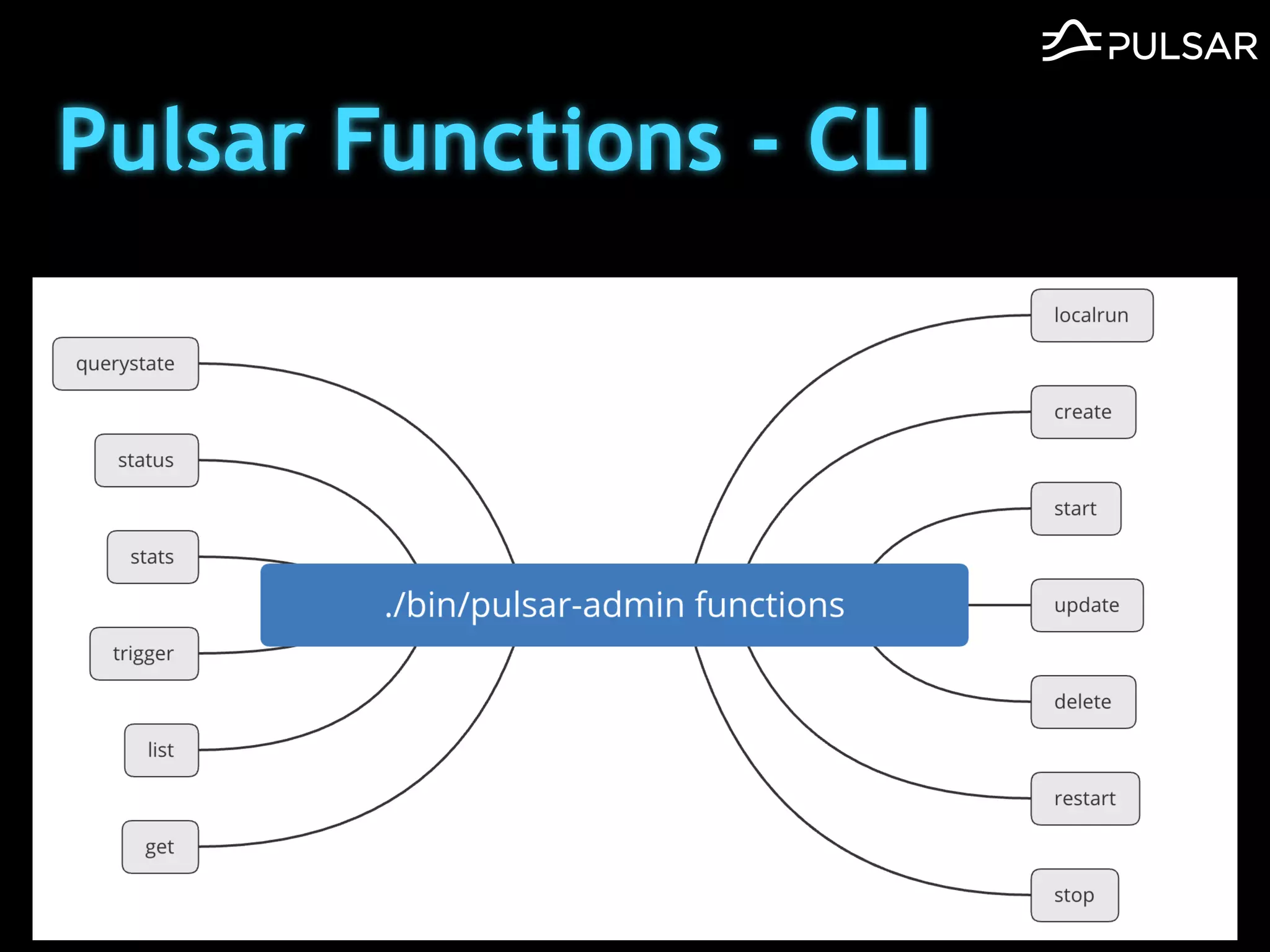
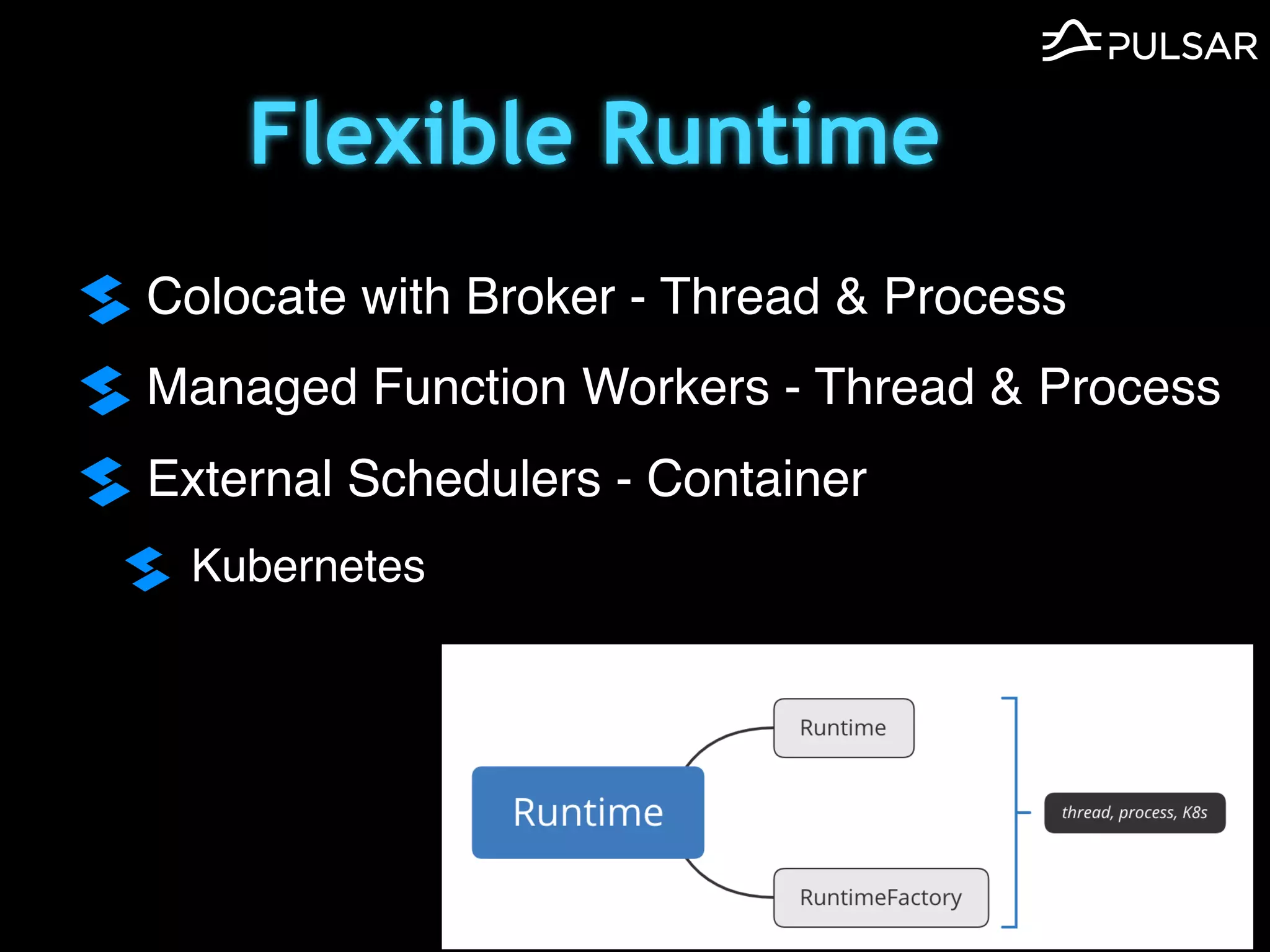
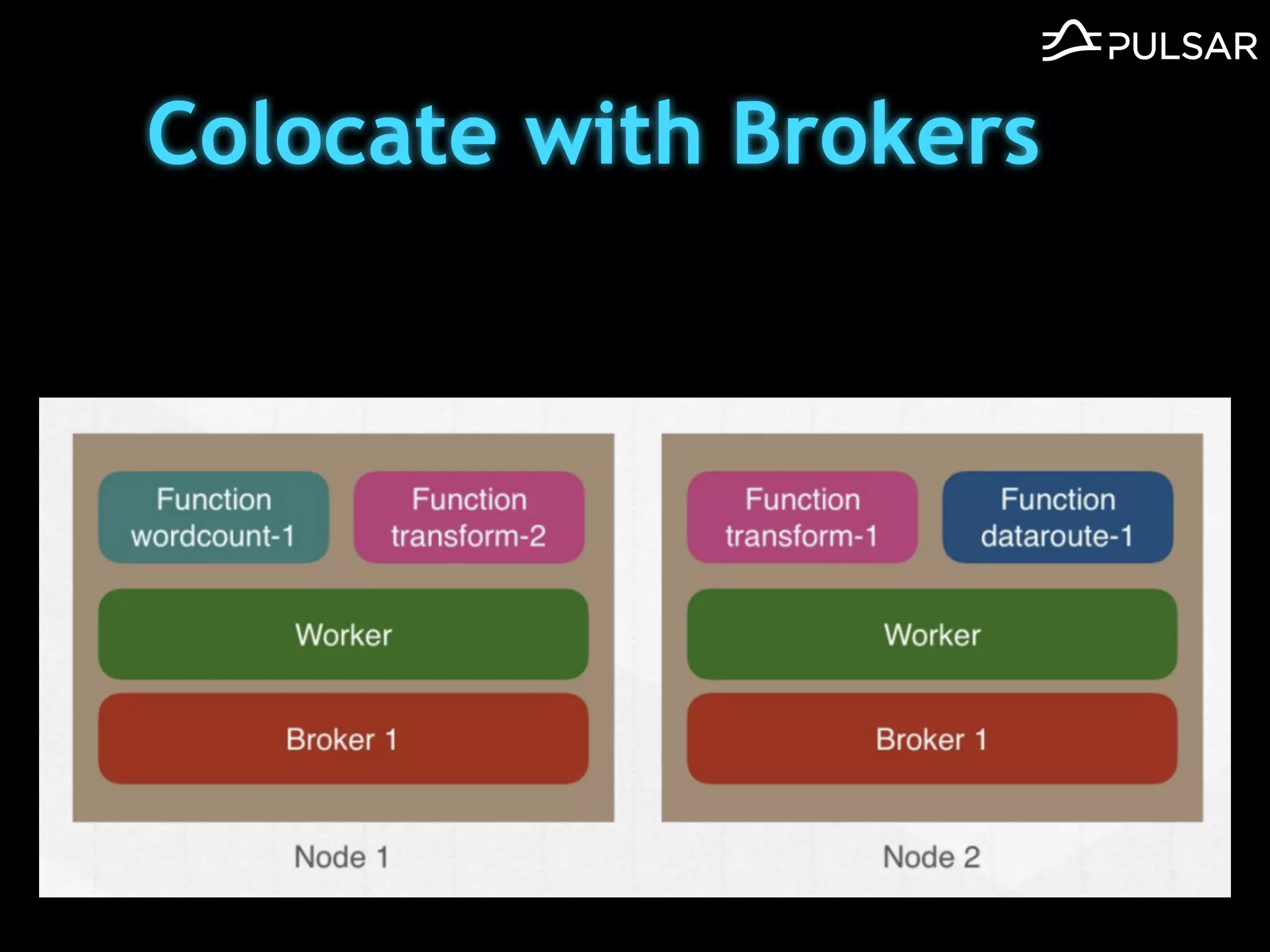
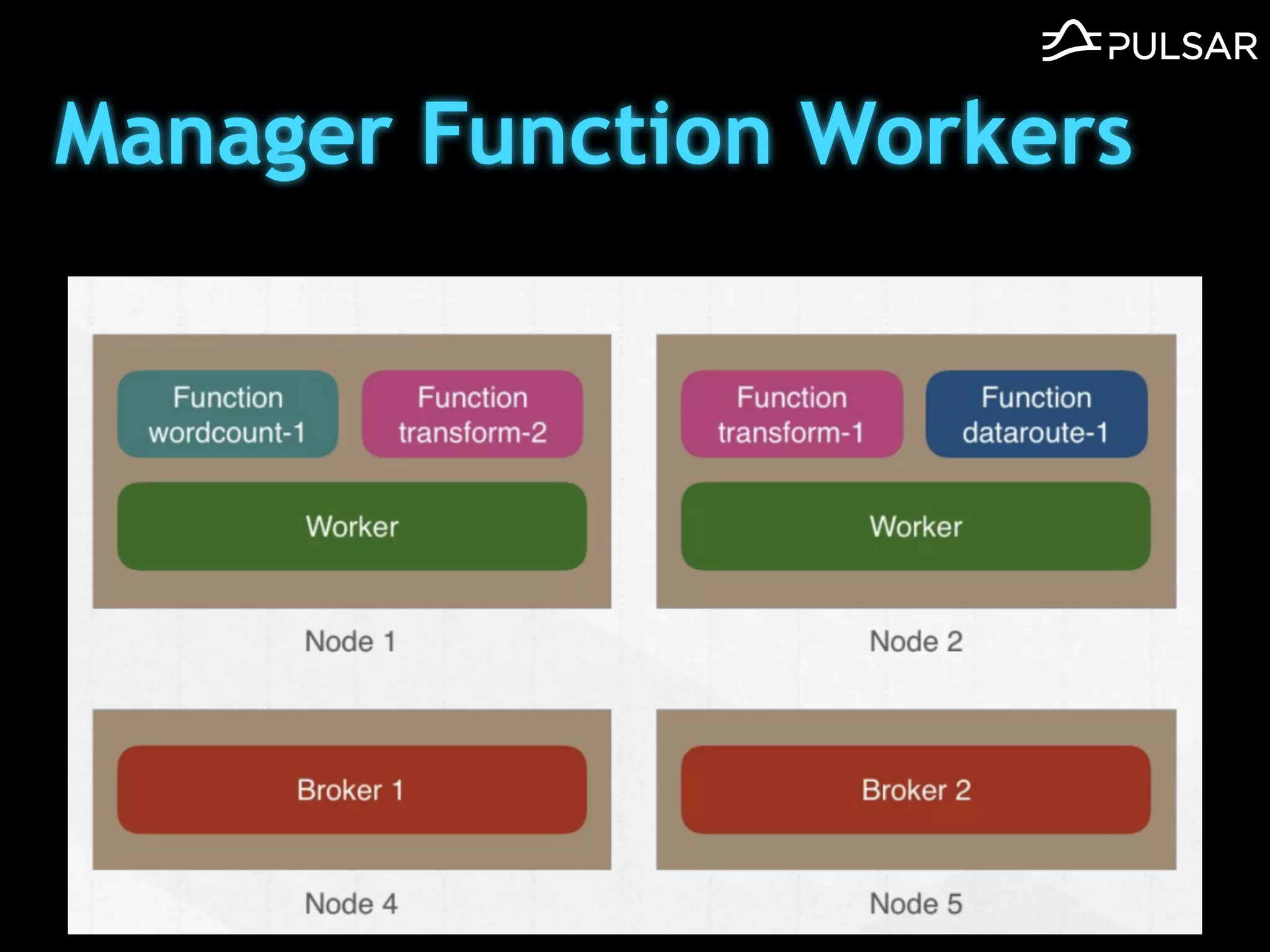
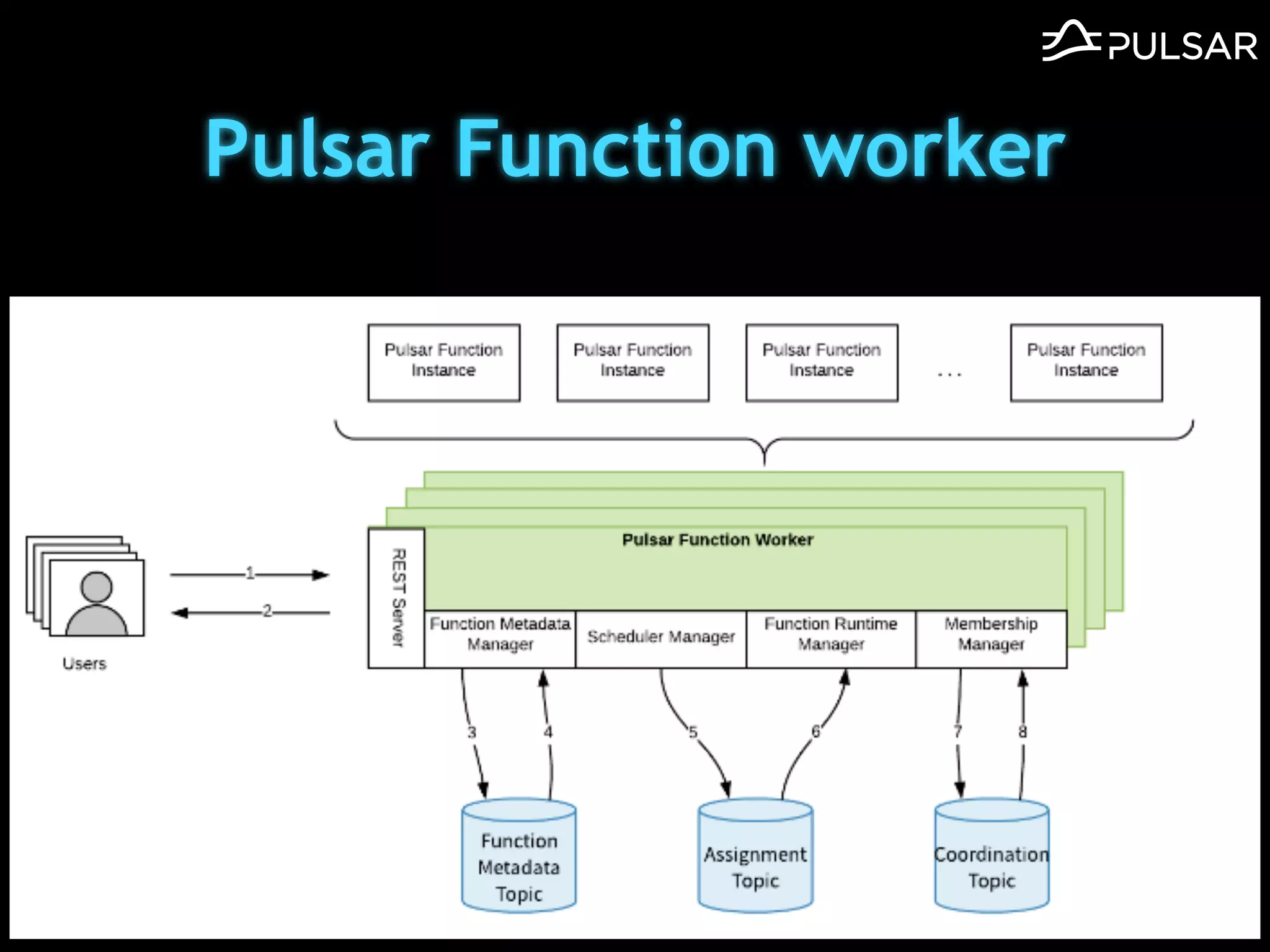
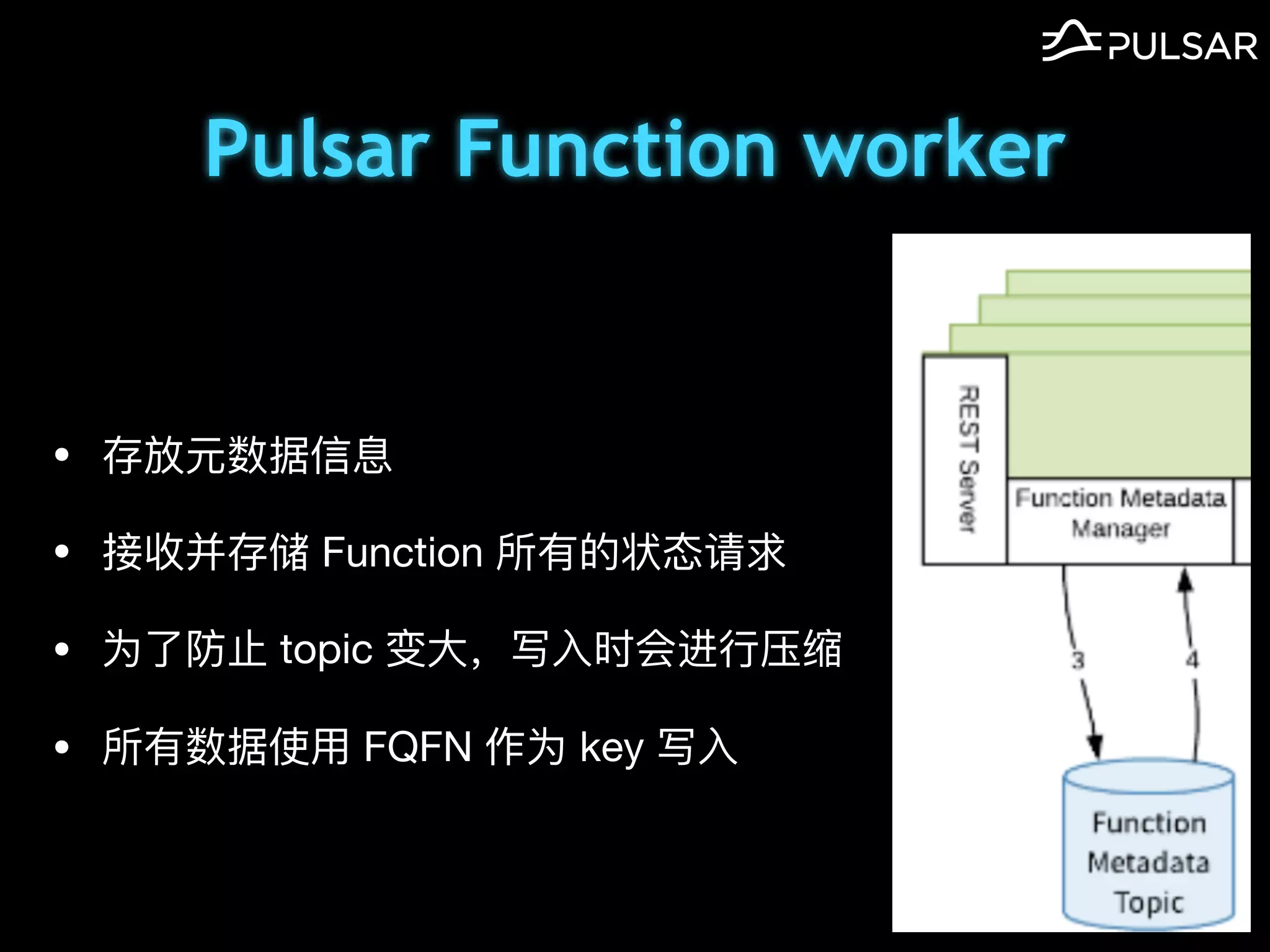
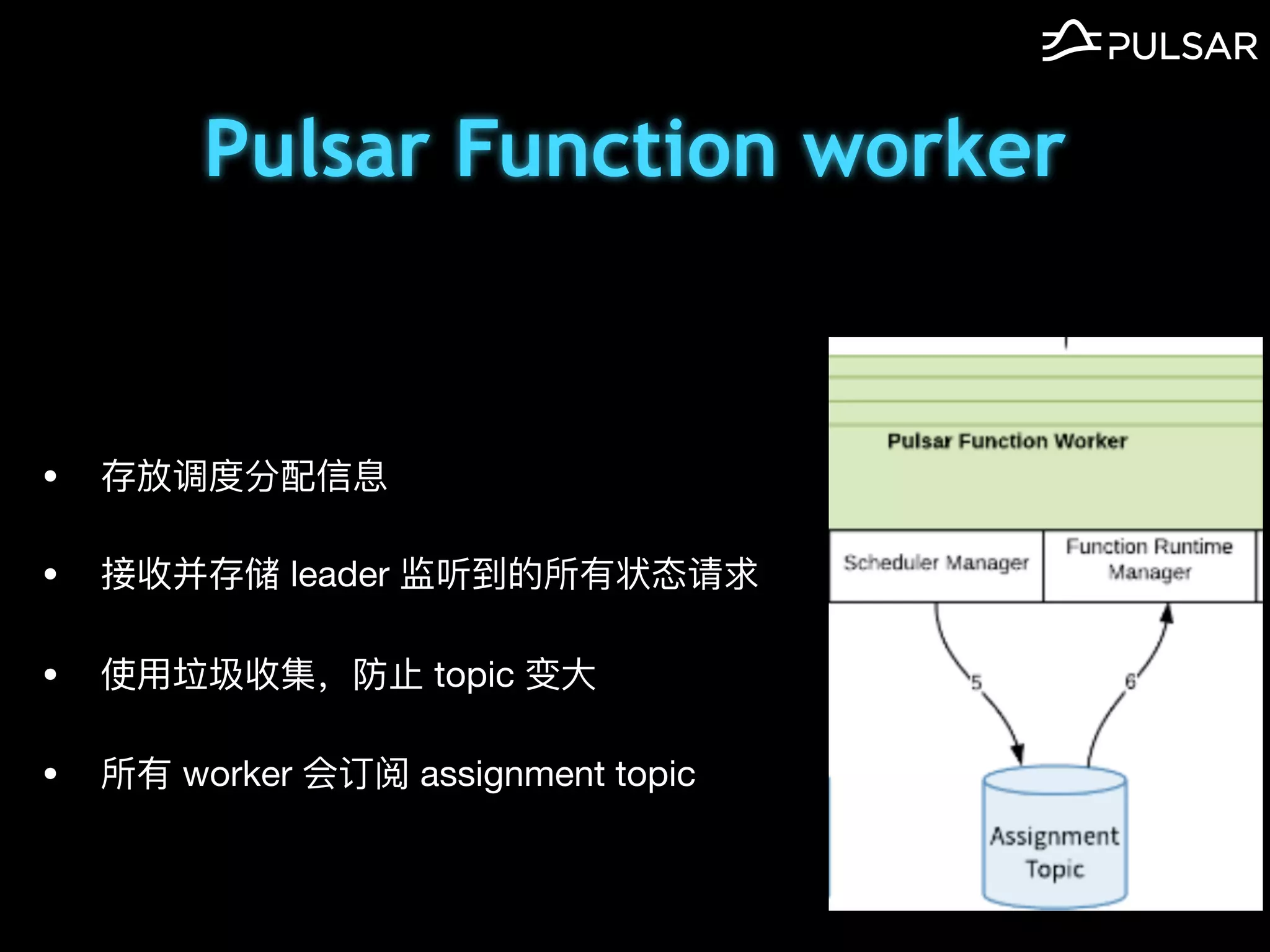
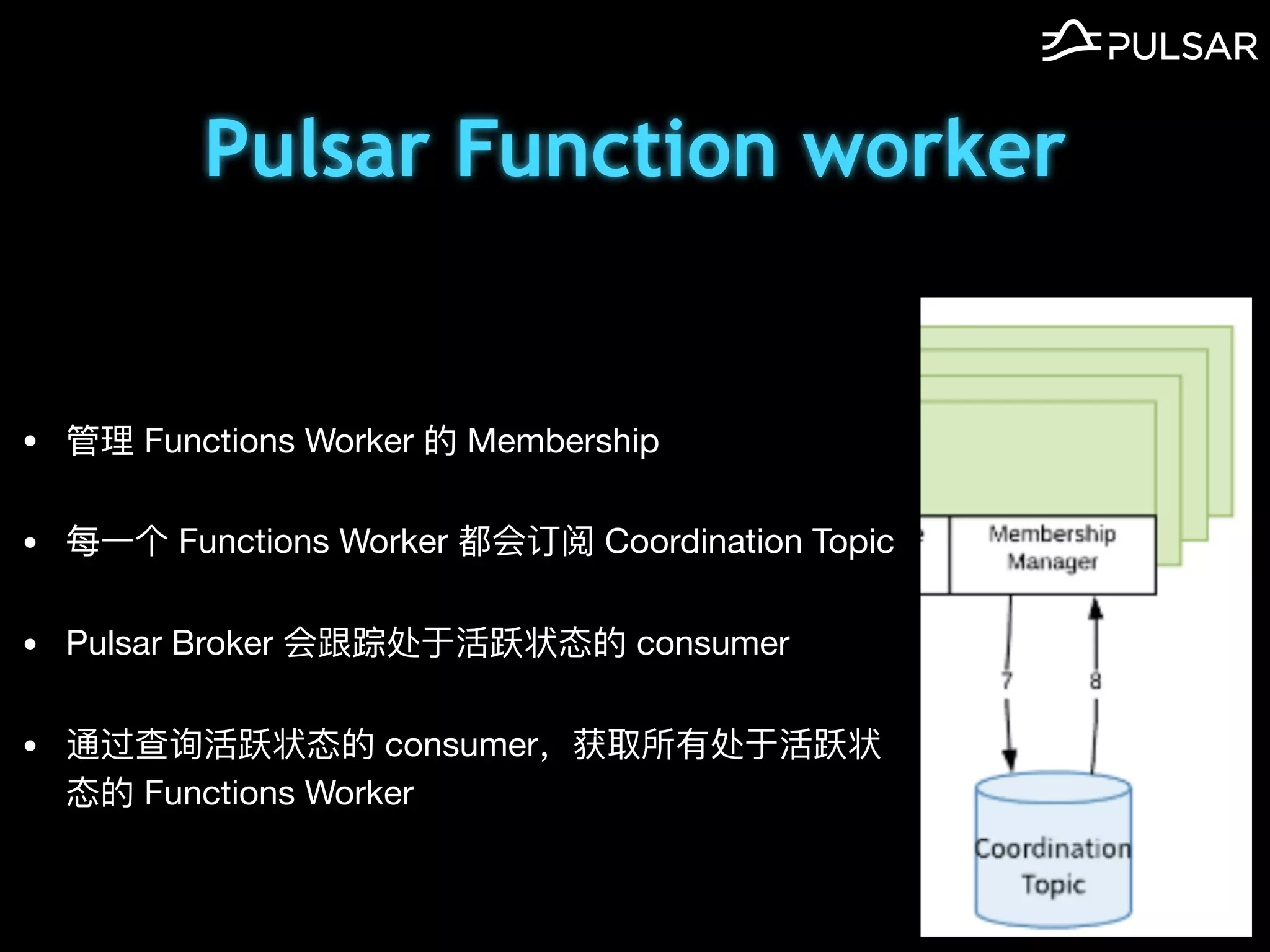
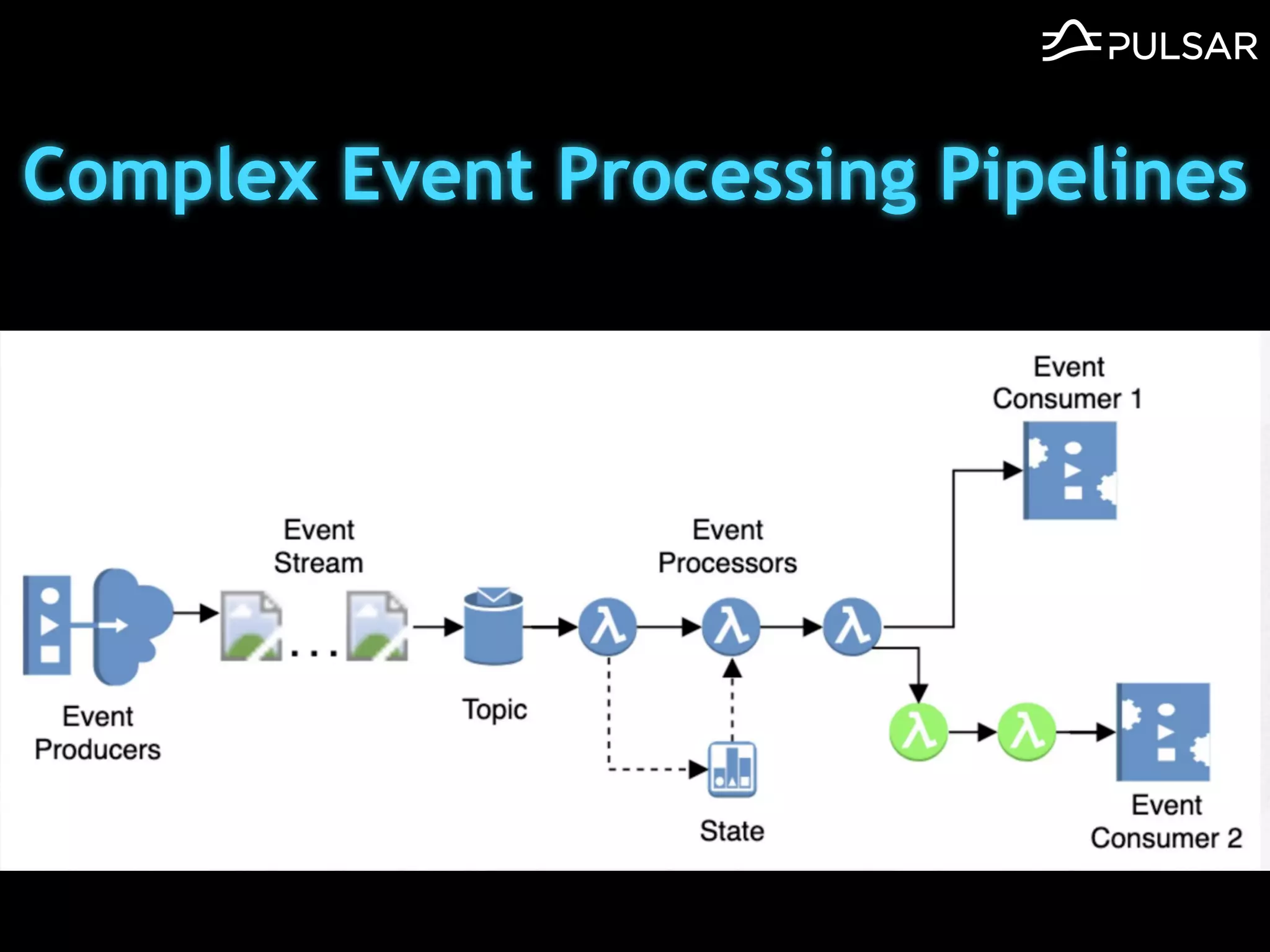
本文介绍了 Apache Pulsar 的架构及其服务器无事件流处理功能的实现,重点讨论了 Go 函数的设计和使用场景,包括 ETL、数据过滤和动态路由等。Pulsar 函数作为一个轻量级的事件流框架,支持多种语言和运行时,并利用自动负载均衡机制进行函数的管理和调度。文中还提到了一些安全隐患和 Go 语言的使用限制。