About Operation
• 现在:
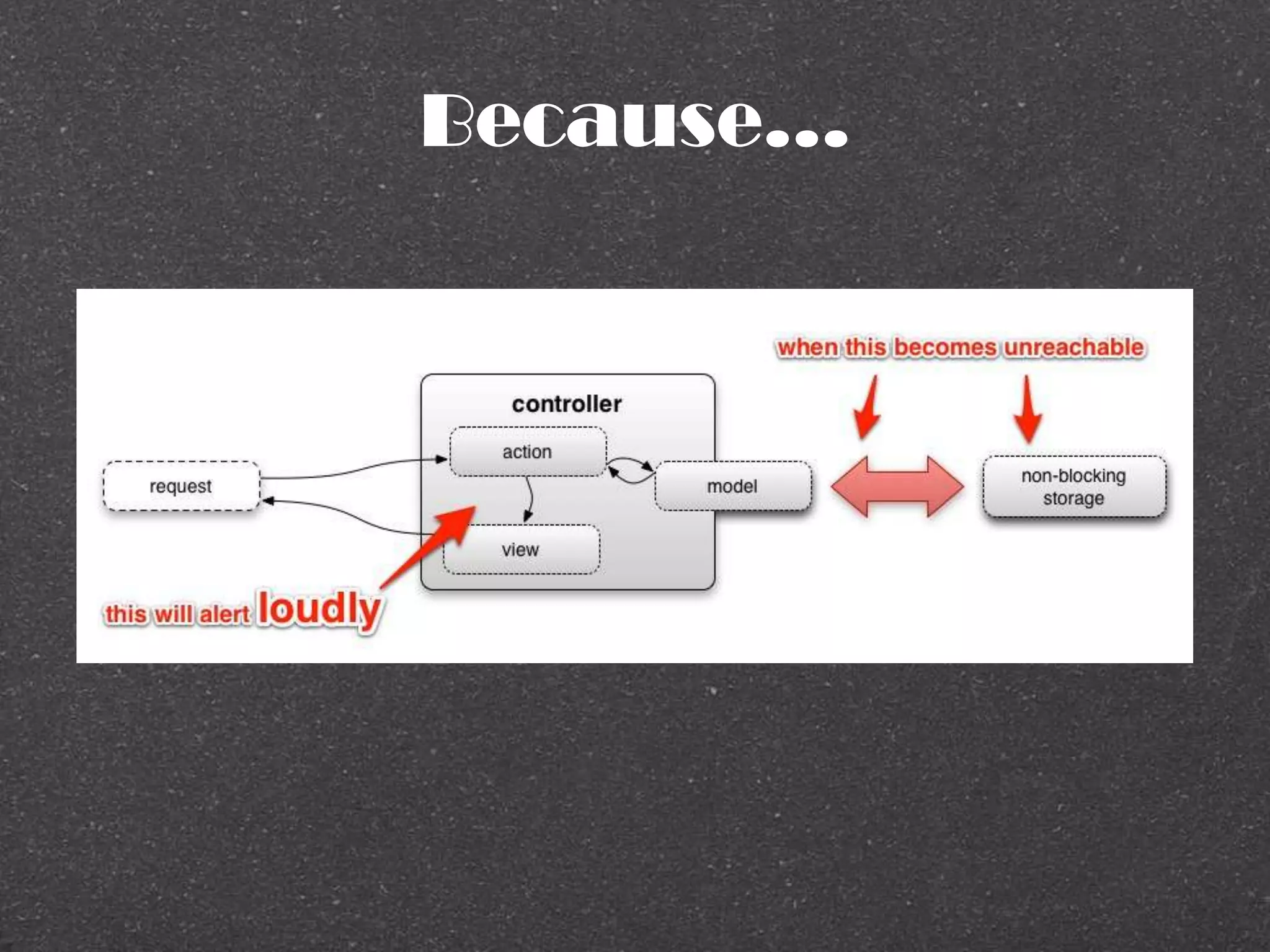
–SRE(Google)
Keep the site up
Work at a Large Scale
Balance competing demands
– PE(淘宝)
– DevOps(Facebook)
Move Fast, Monitor Close
– SDN
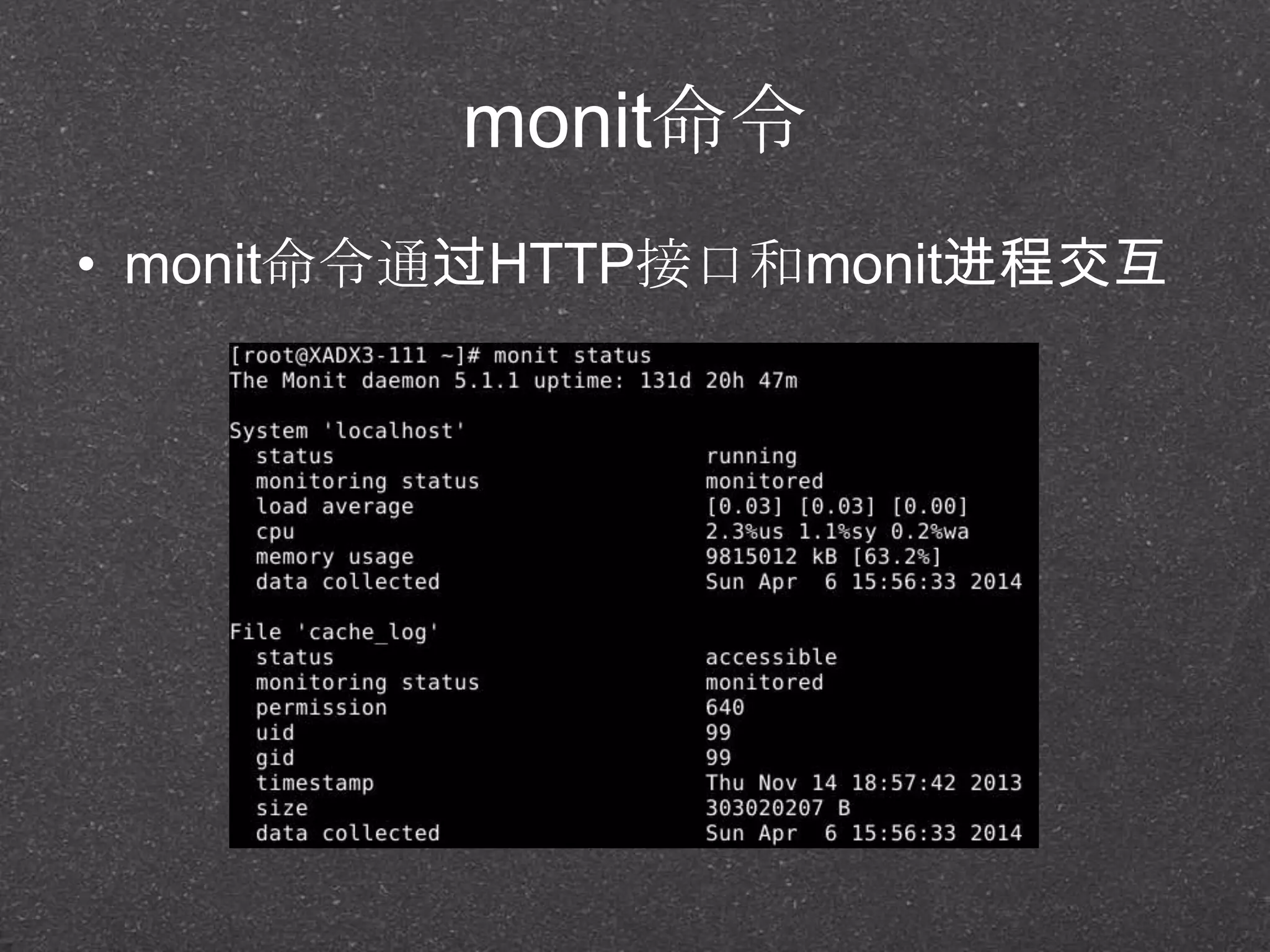
monit
set httpd port2812 and
use address localhost
allow localhost
set daemon 60
set alert 'noreply@admin.com'
check system localhost
if cpu usage (wait) > 5% for 2 cycles then alert
check process squid with pidfile '/var/run/squid.pid'
start program = '/etc/init.d/squid start'
stop program = '/etc/init.d/squid stop'
if totalmem > 8192 Mb then restart squid
check file cache_log with path /var/log/squid/cache.log
if match "COSS: /data/stripe: Rebuild Completed"
then exec "/usr/libexec/squid/online" every 10 cycles
natification_options
r =Recovery(恢复)
f = Flapping(抖动)
s = Scheduled downtime(规划内停止和恢复)
n = None(不发送)
d = Down(host状态)
u = Unreachable(host不可达)或Unknown(service未知)
w = Warning(service警告)
c = Critical(service危险)














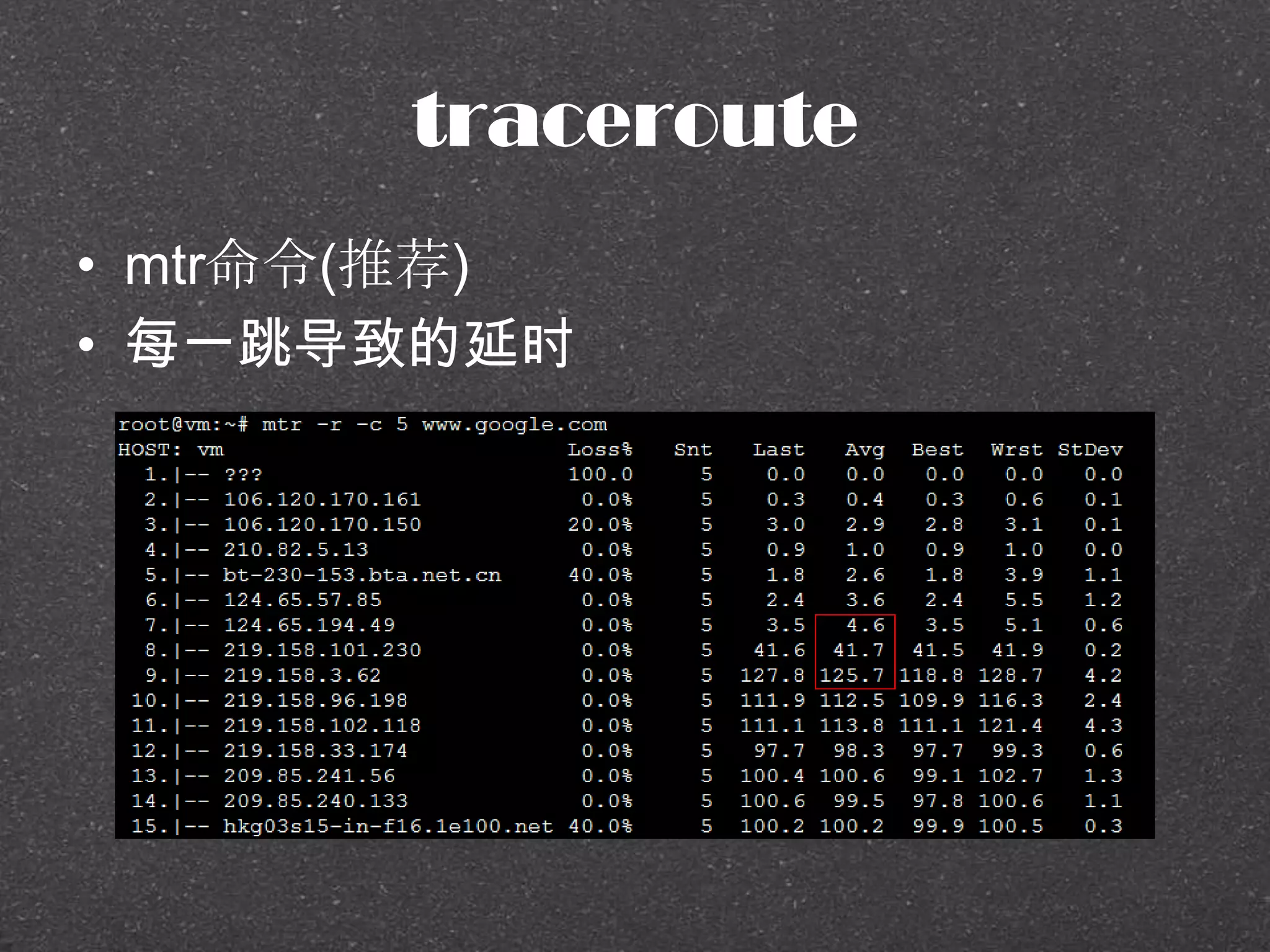
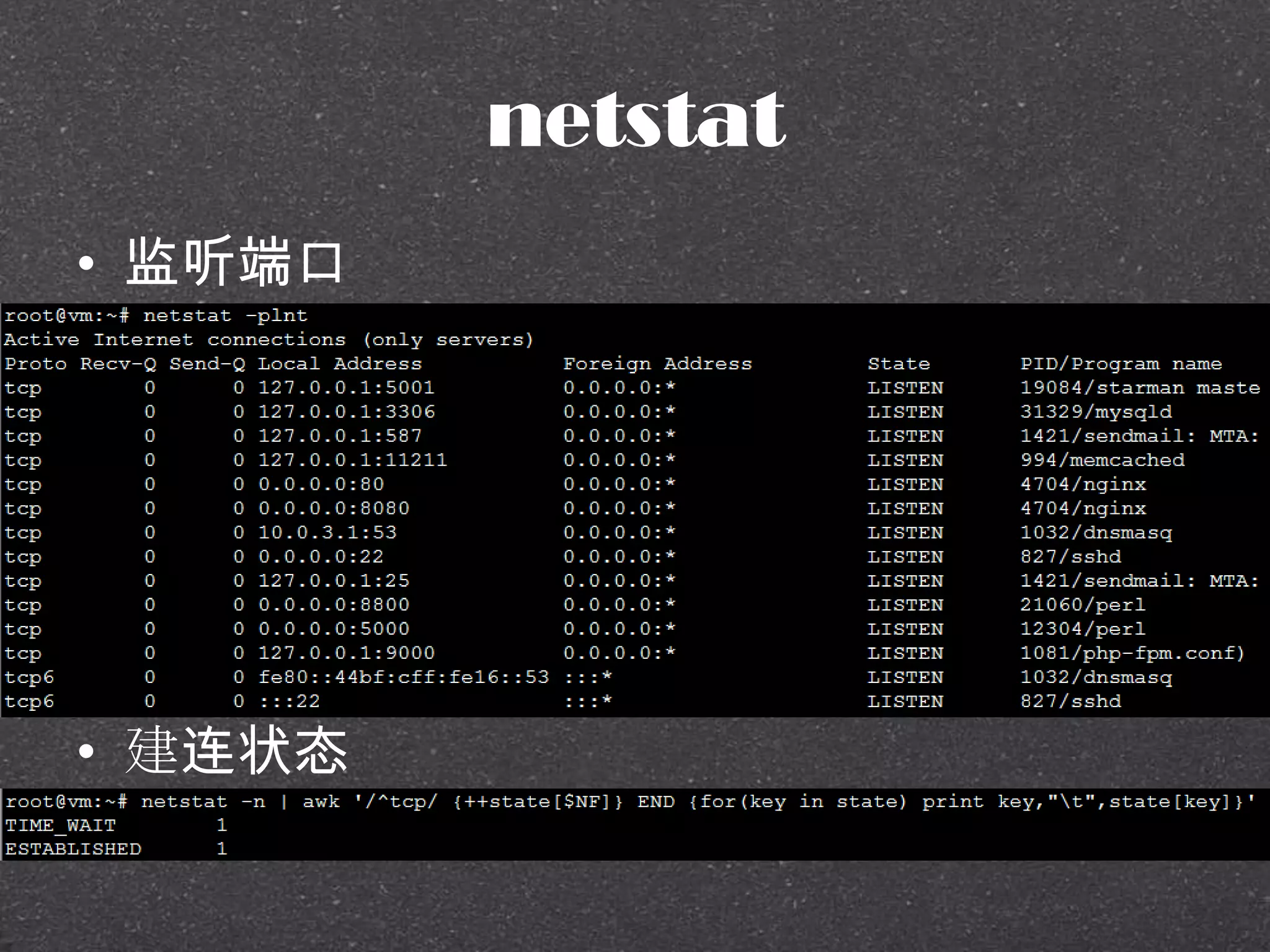
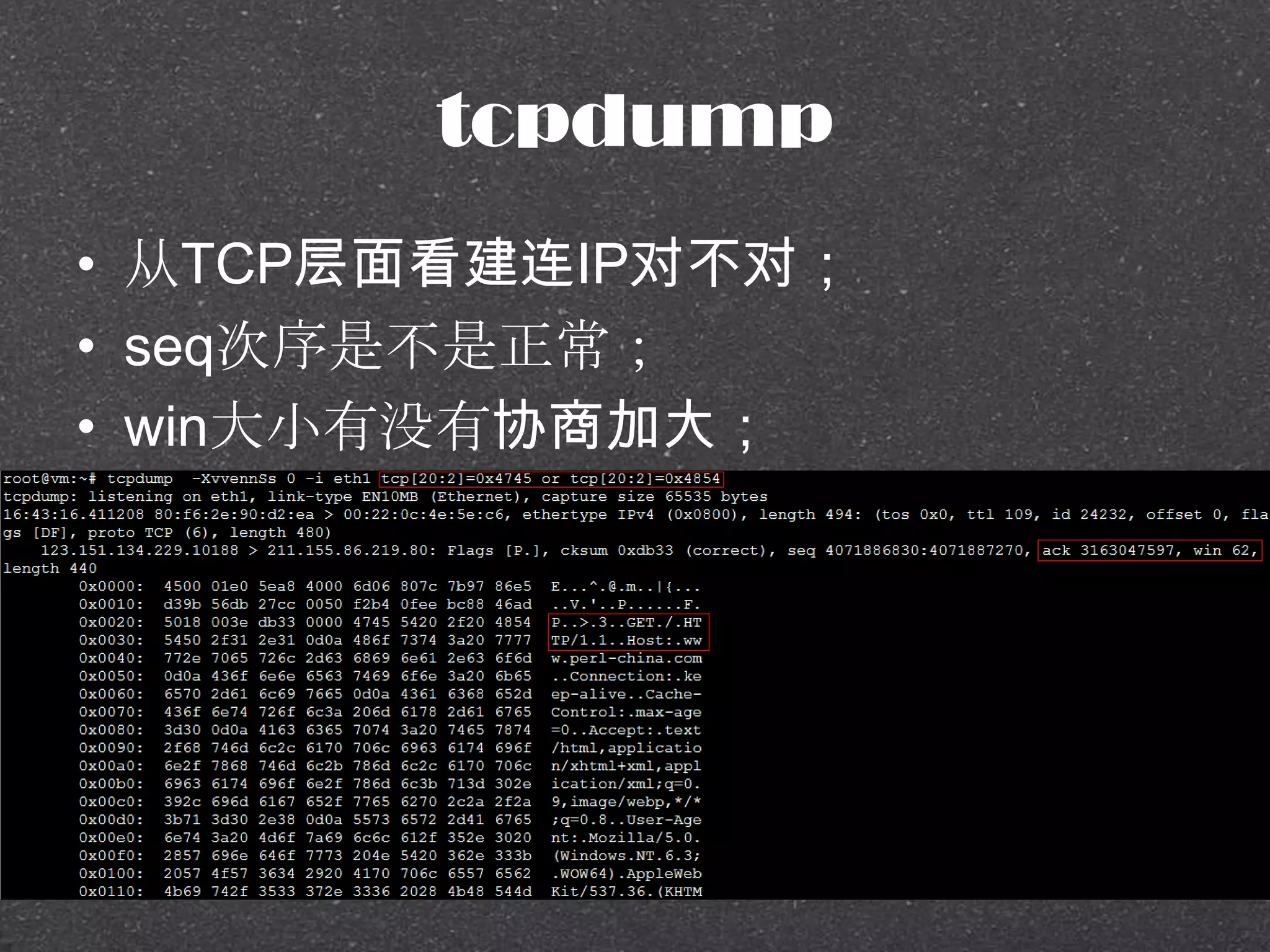

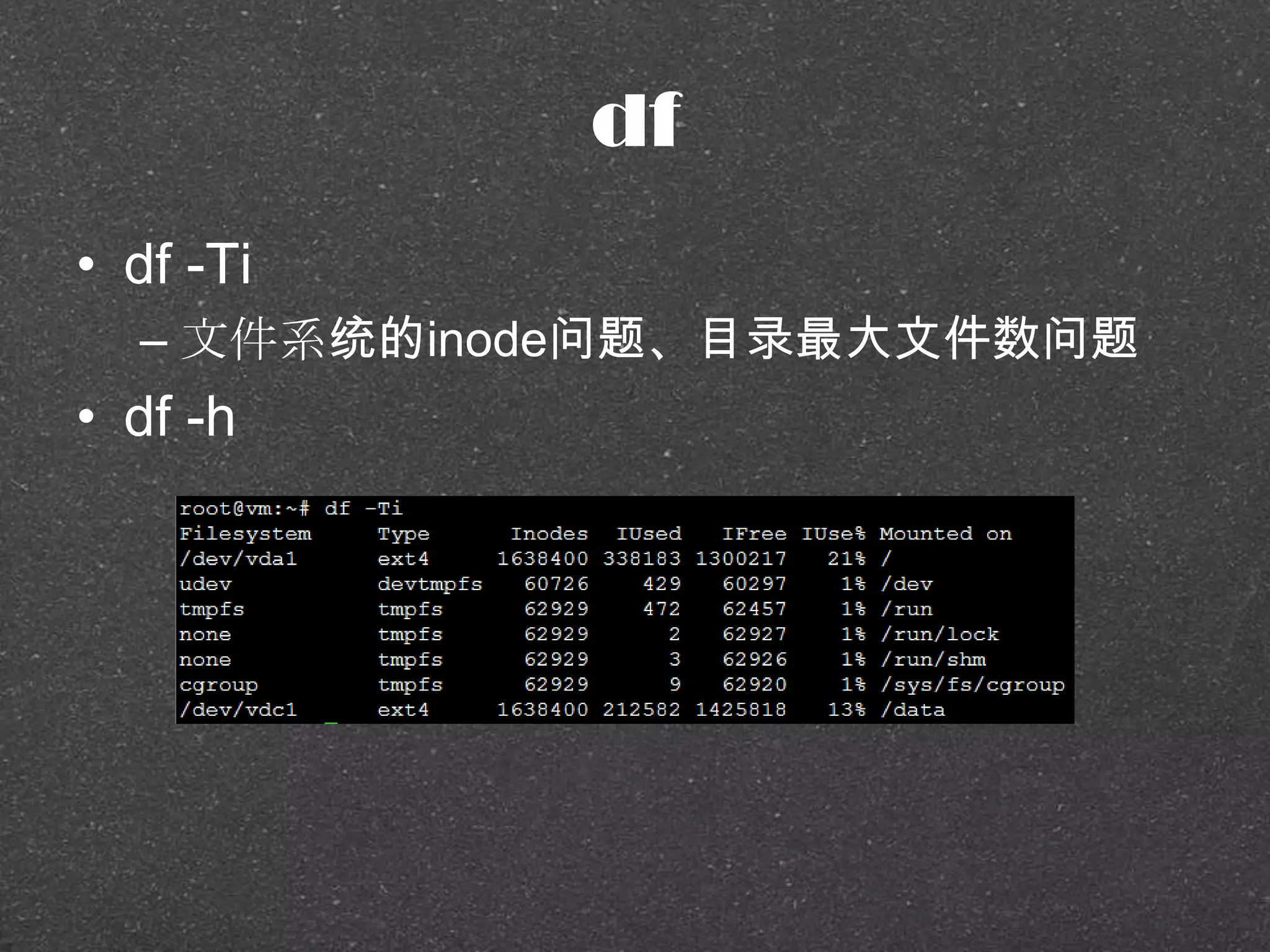
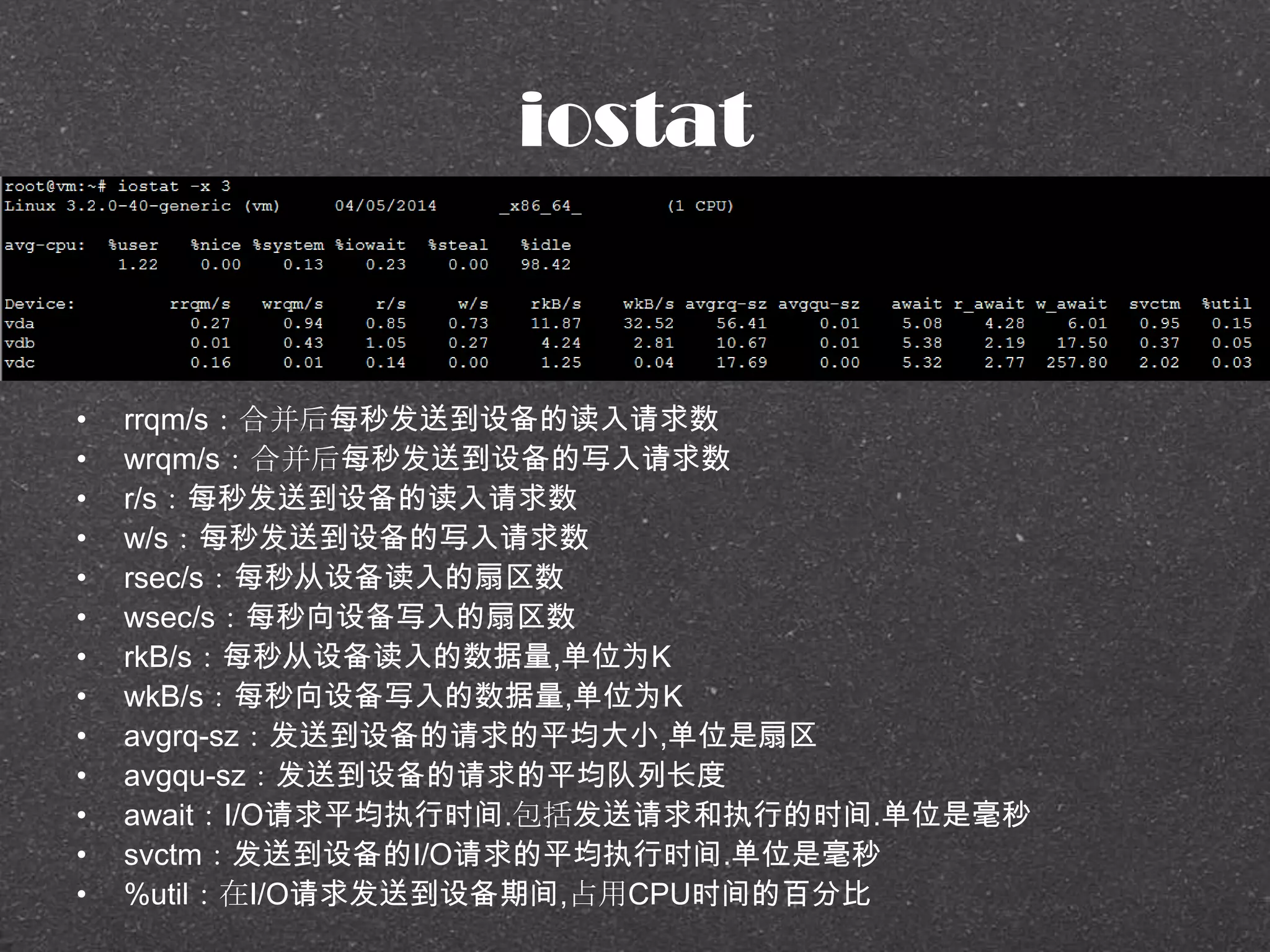

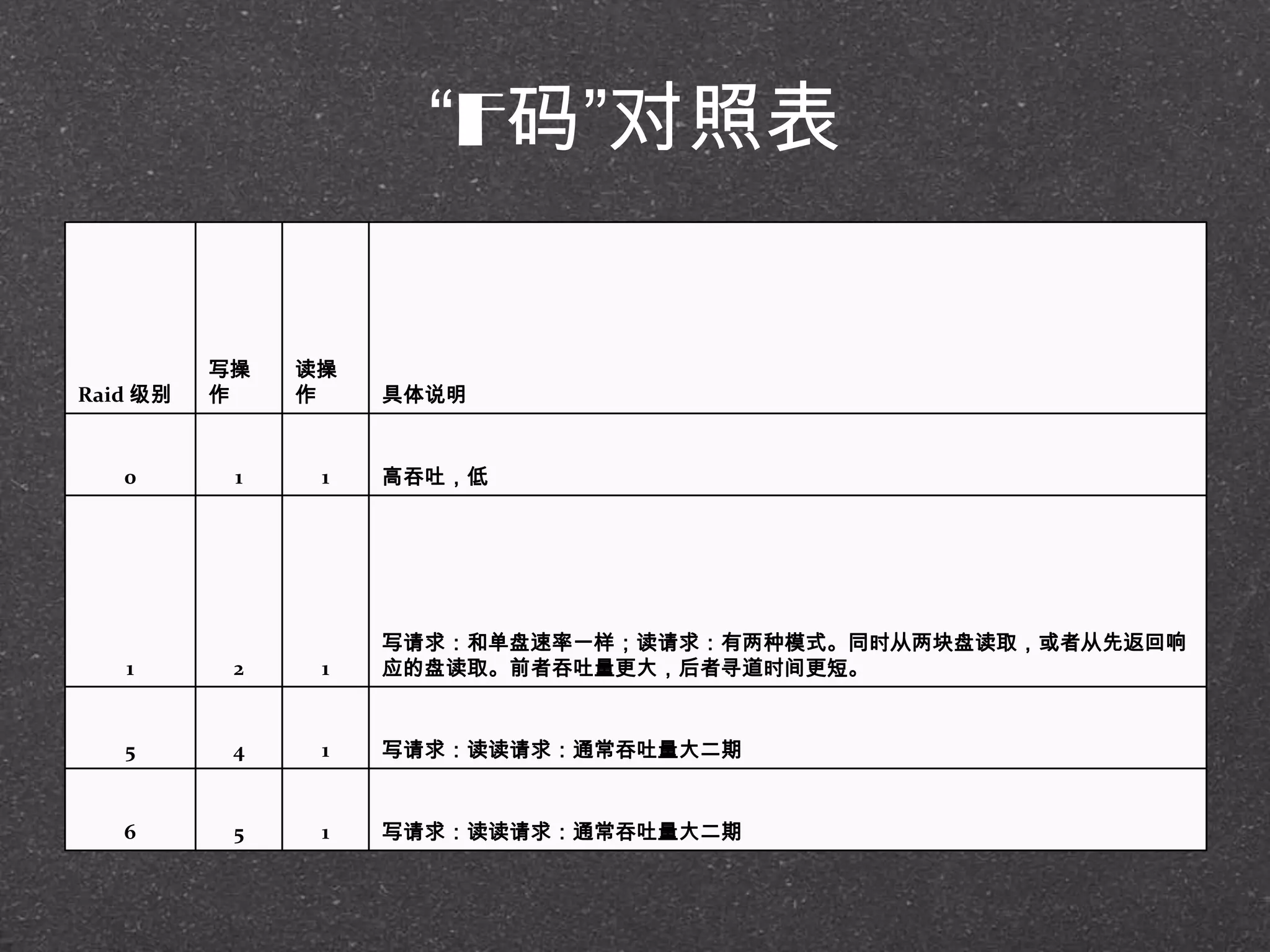

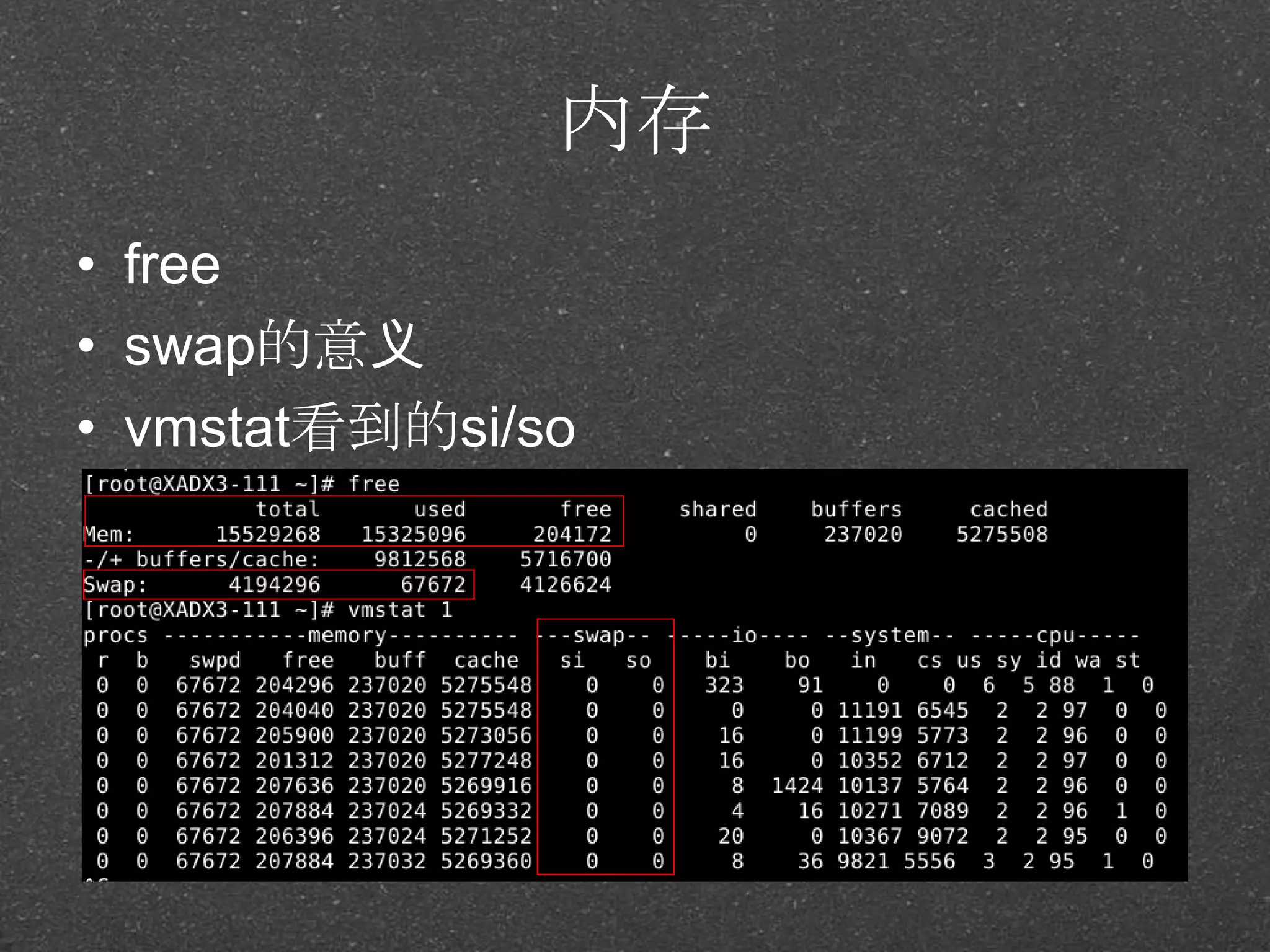
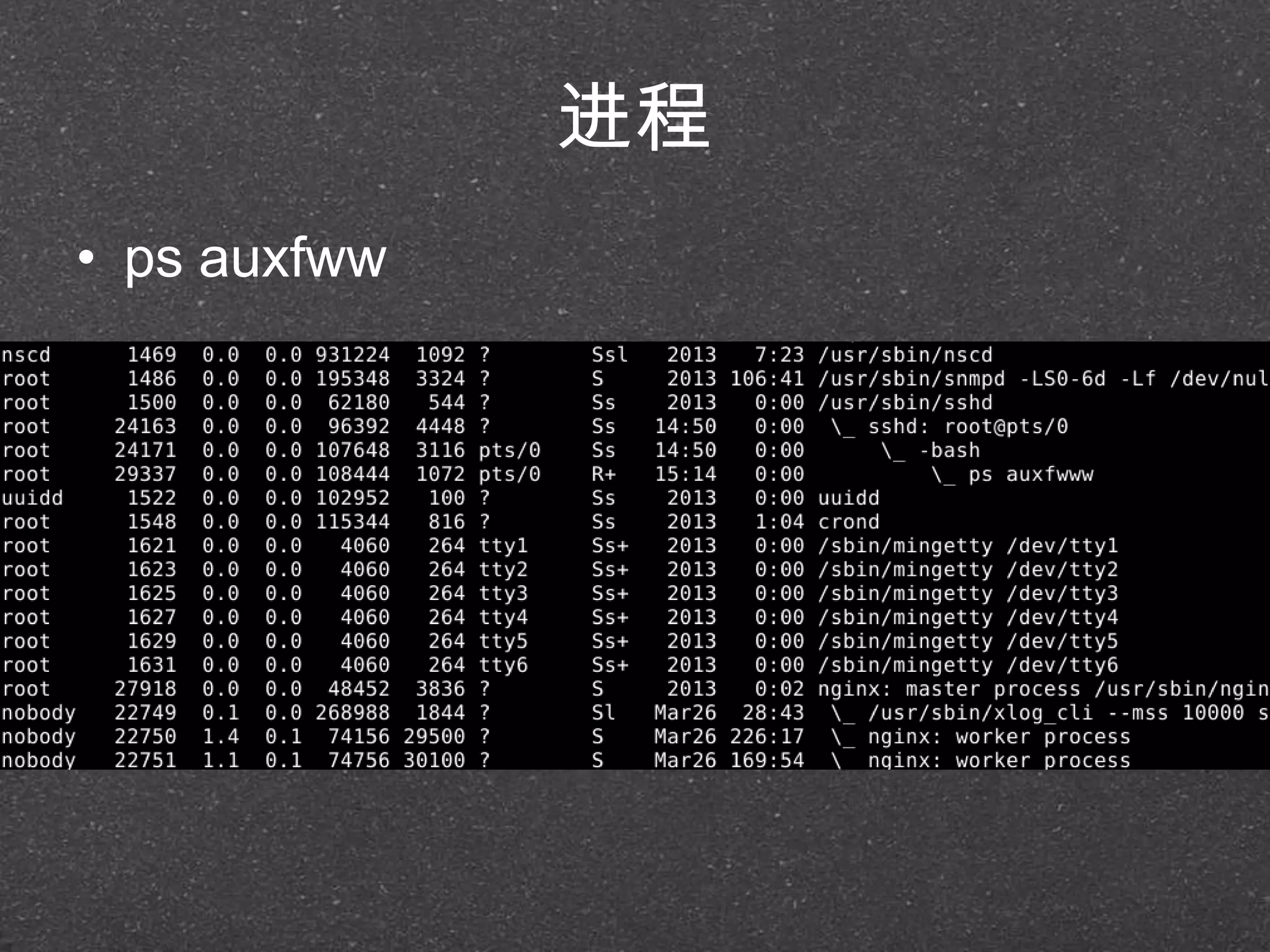











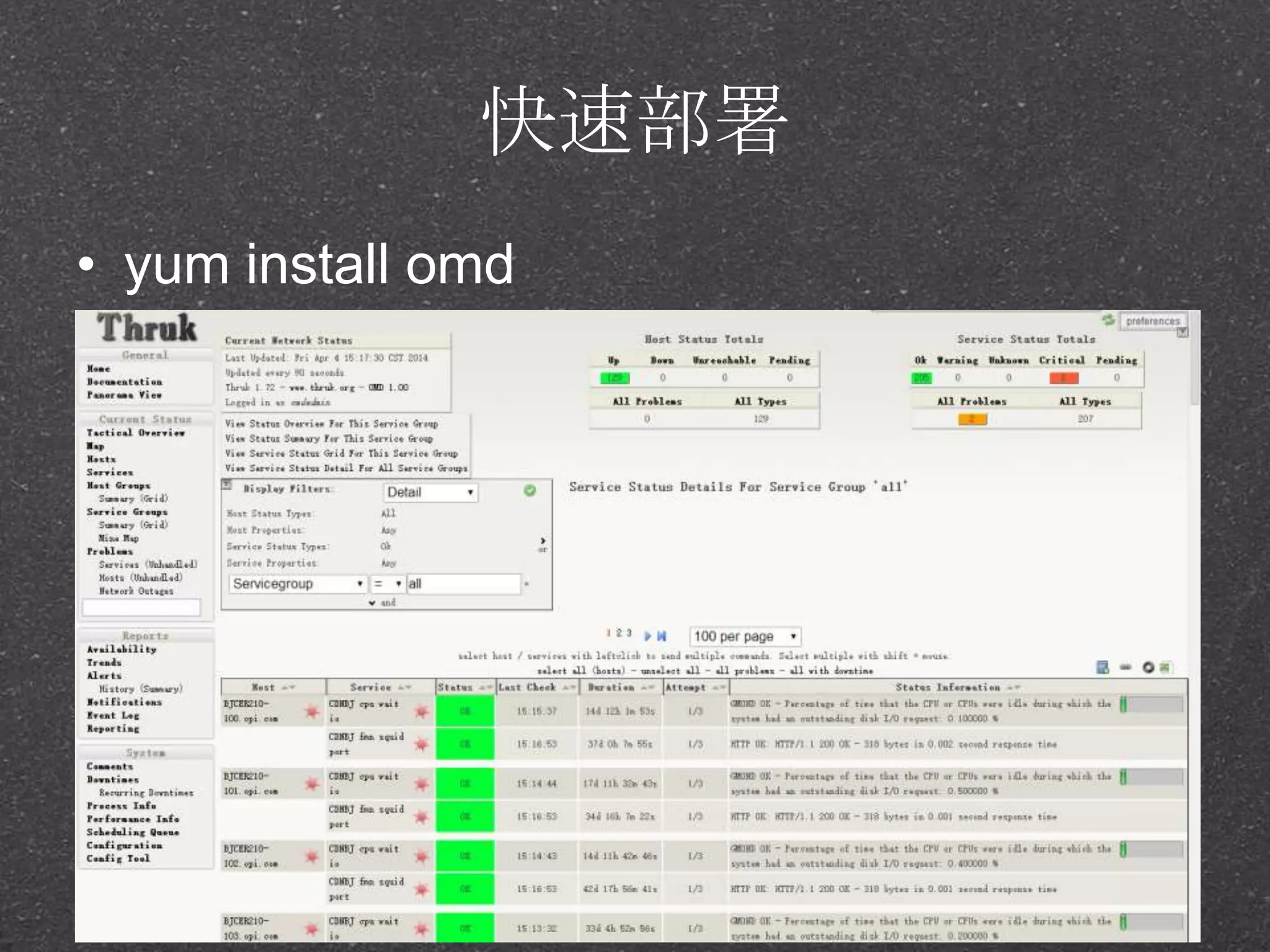







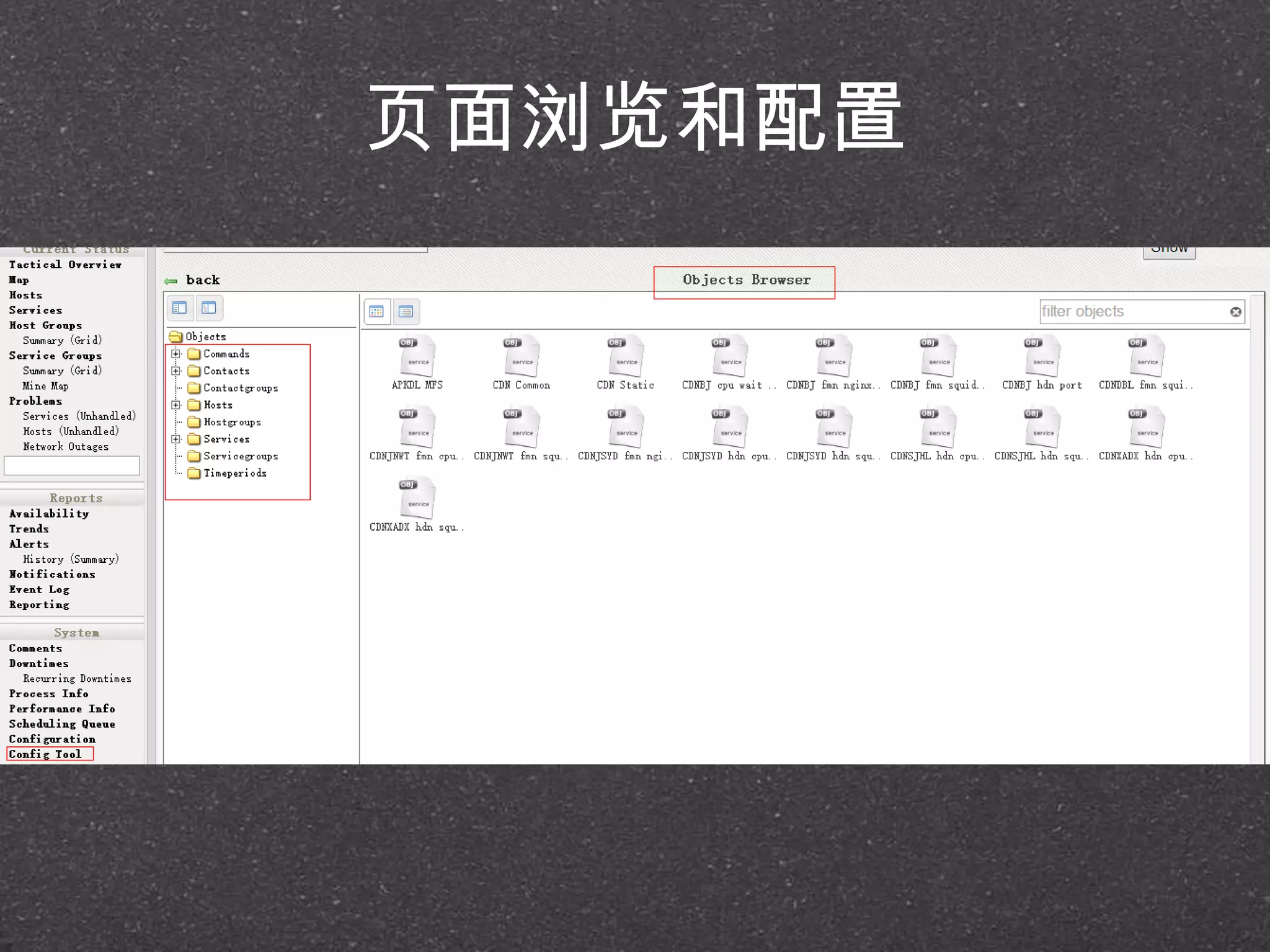




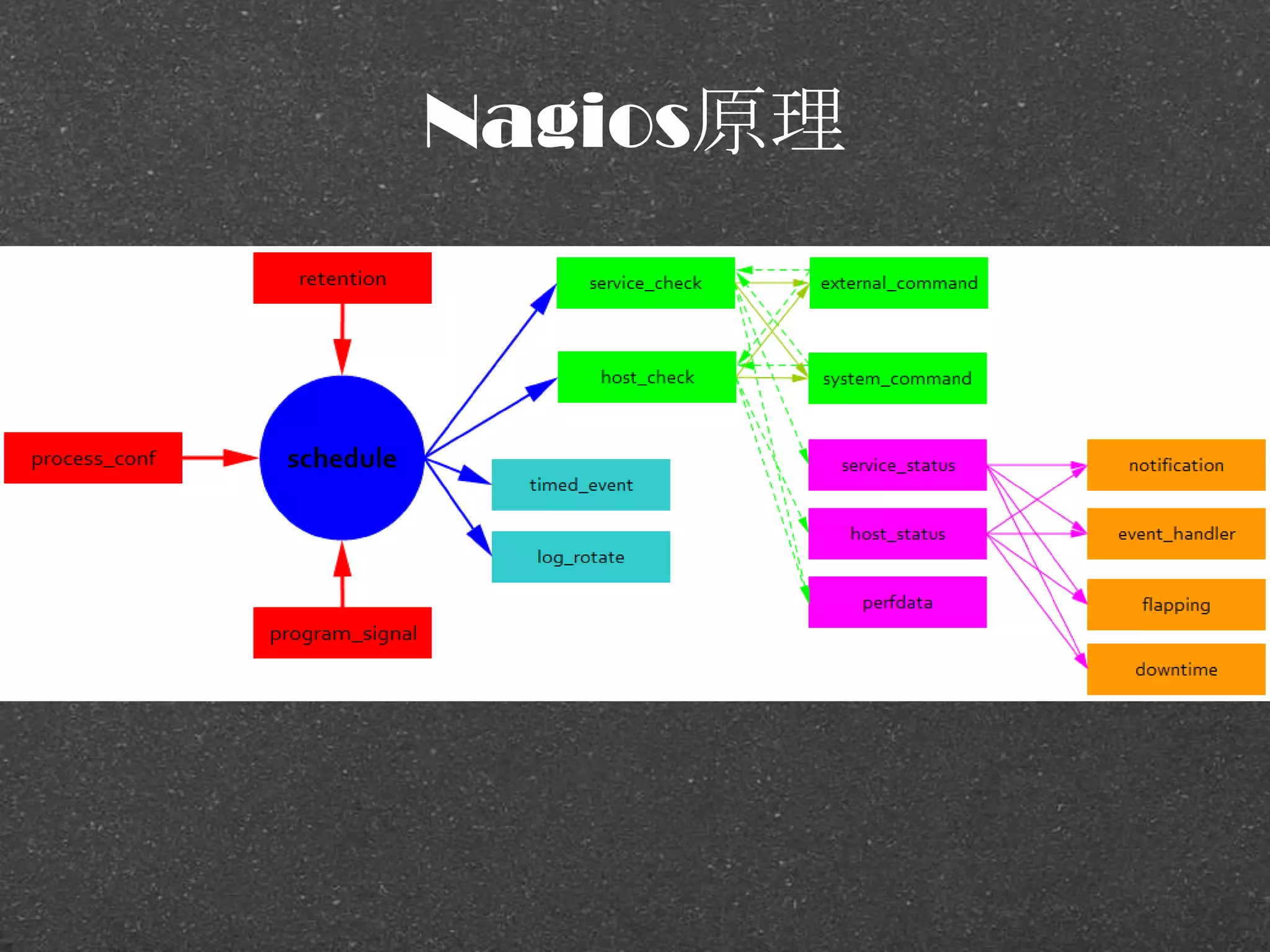
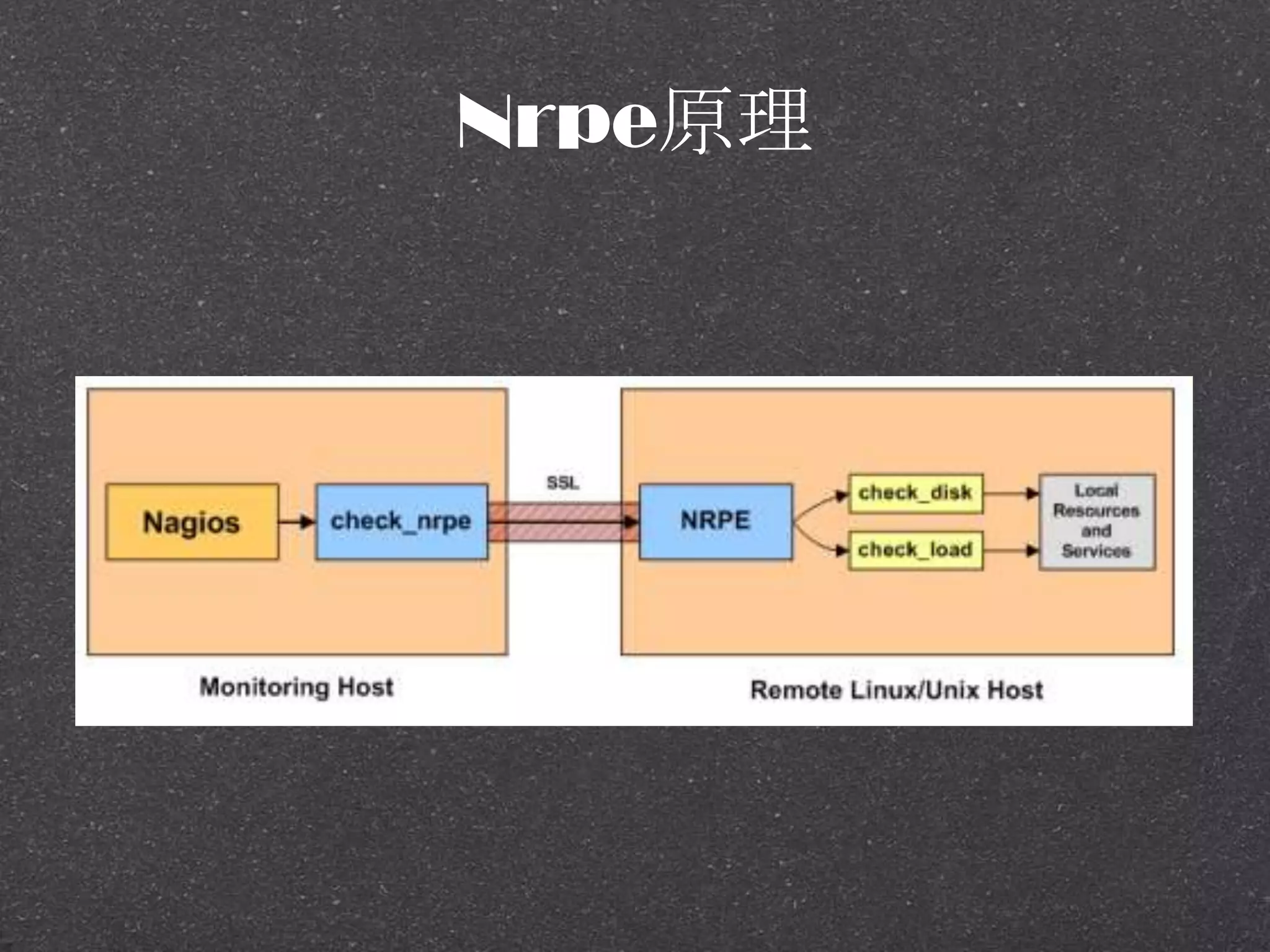



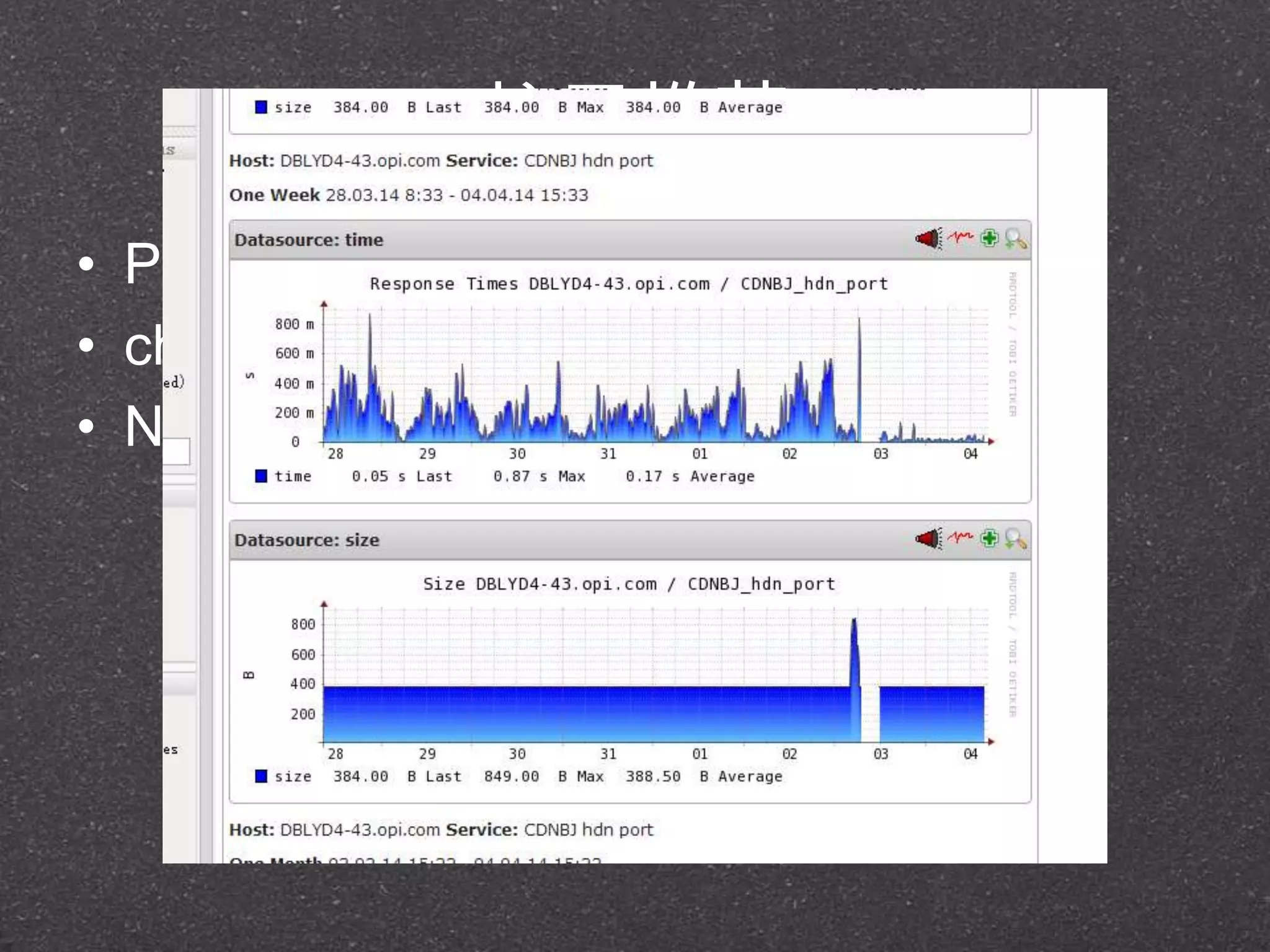
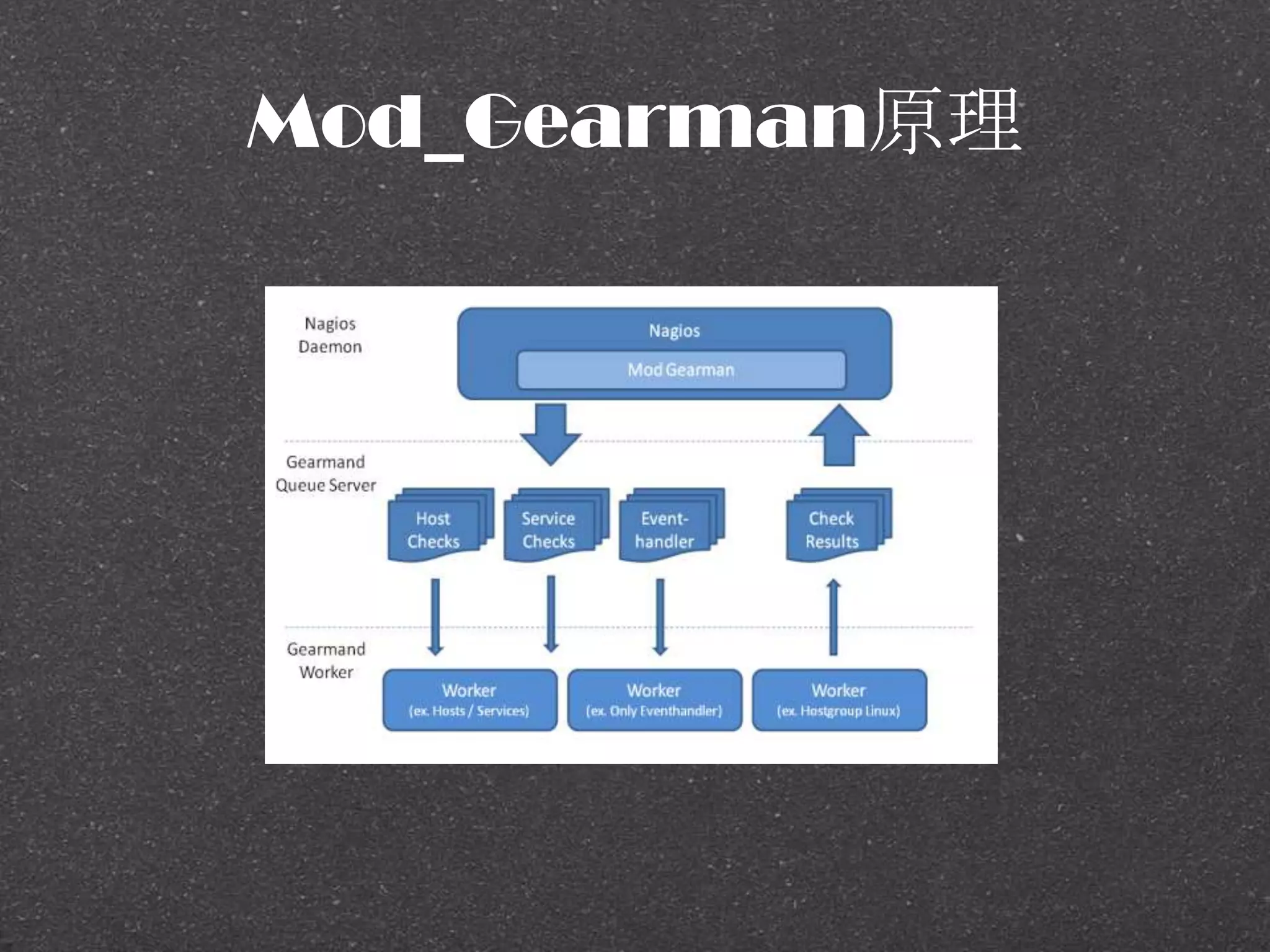
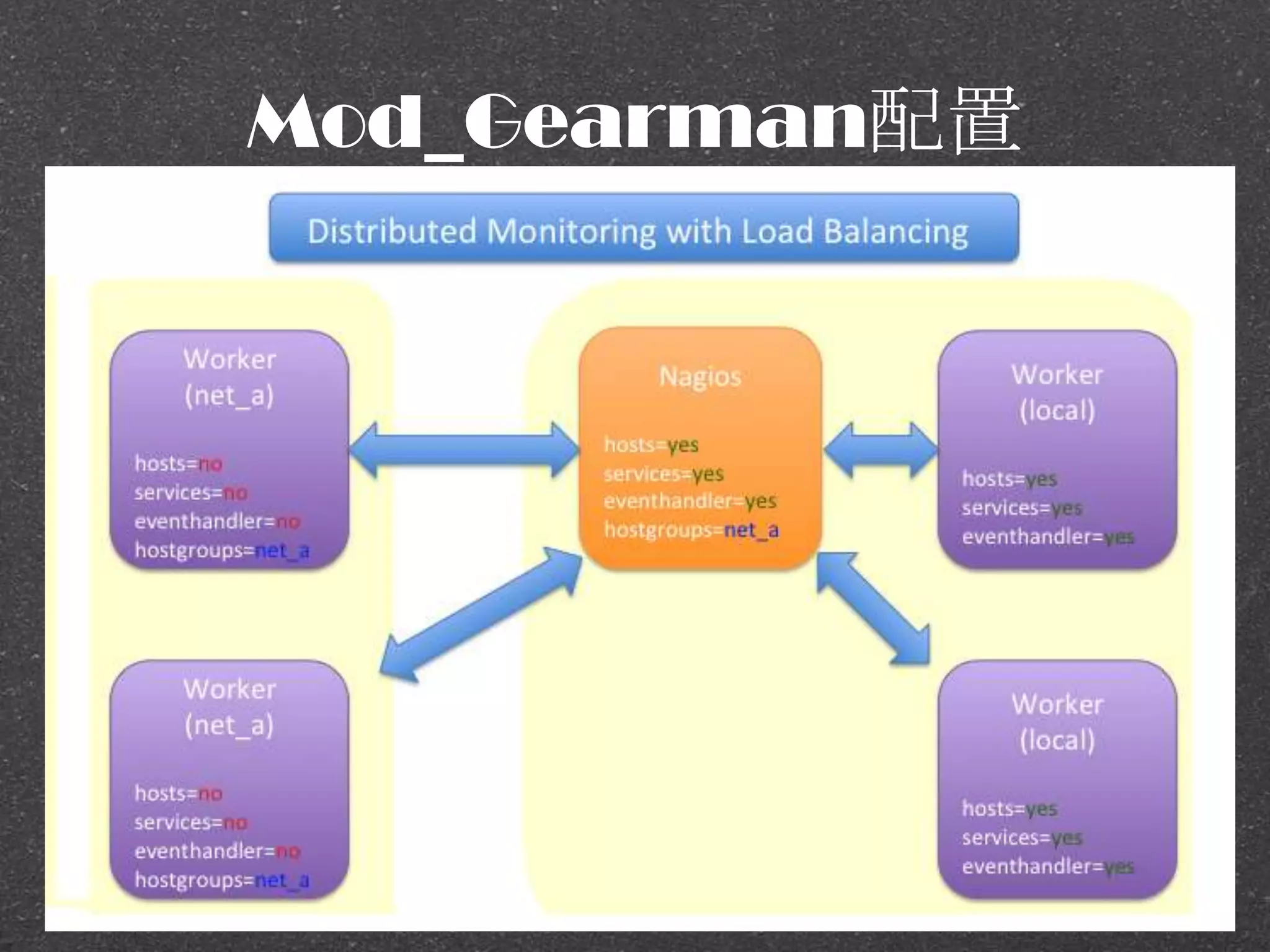

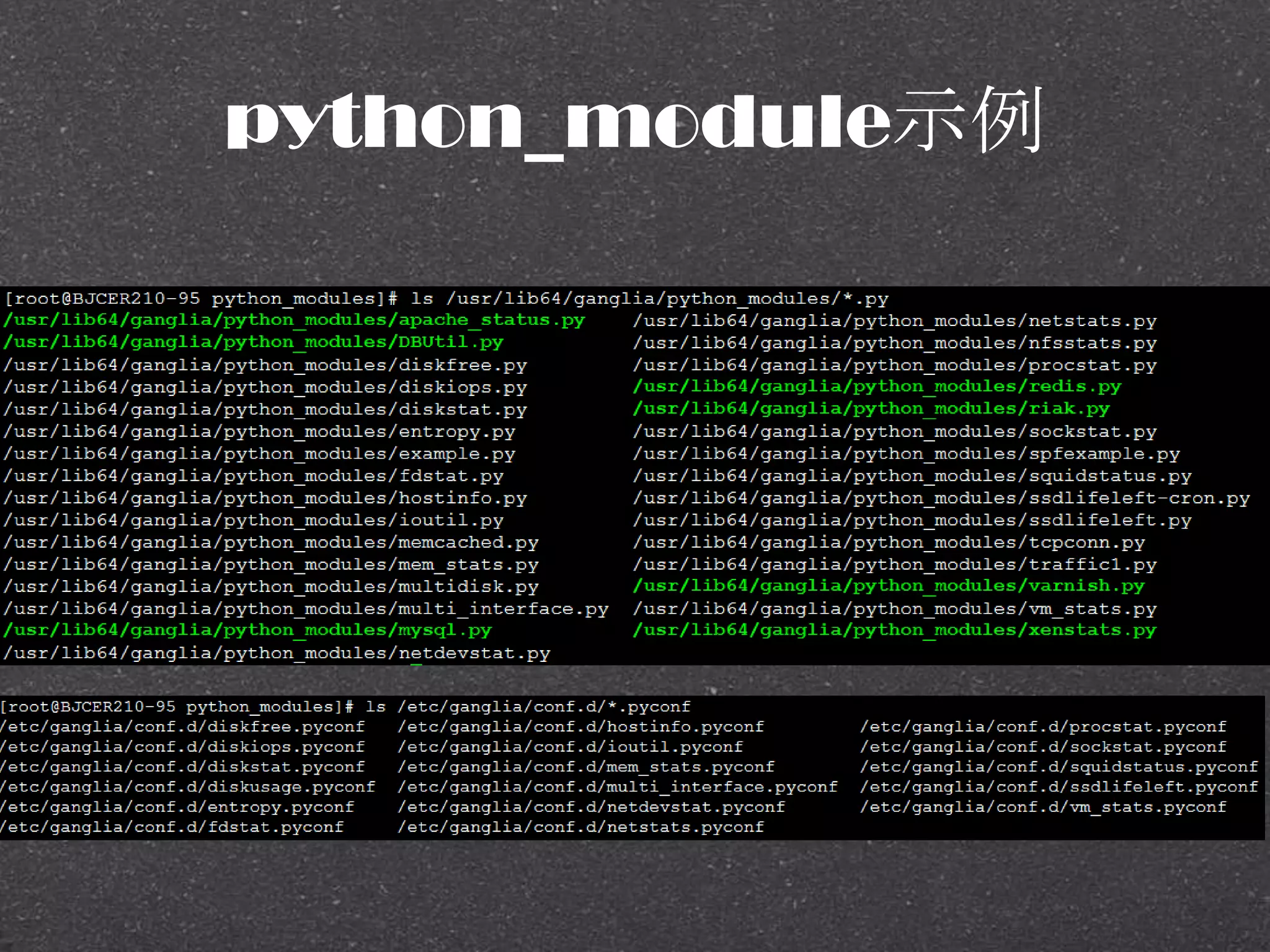
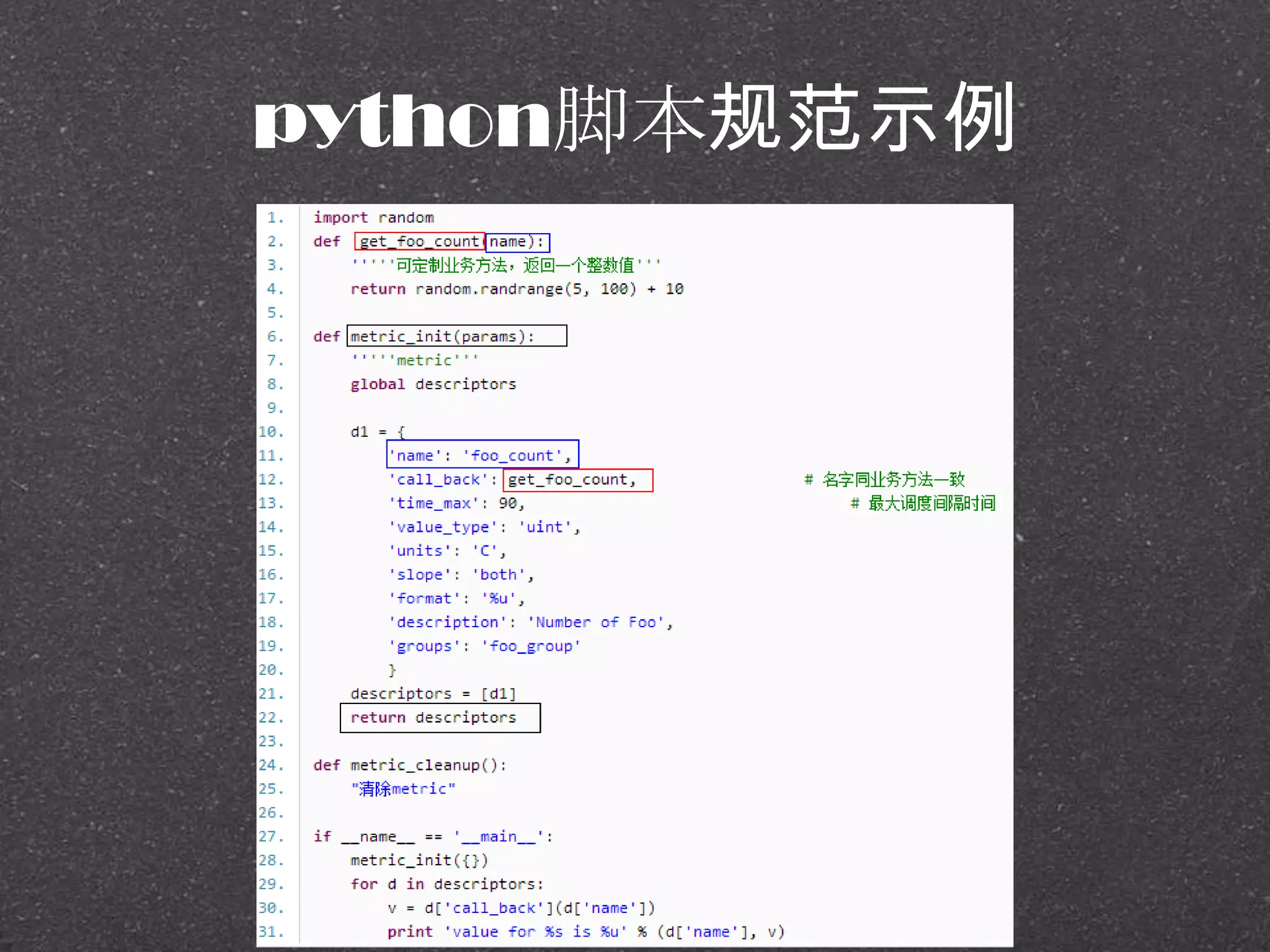
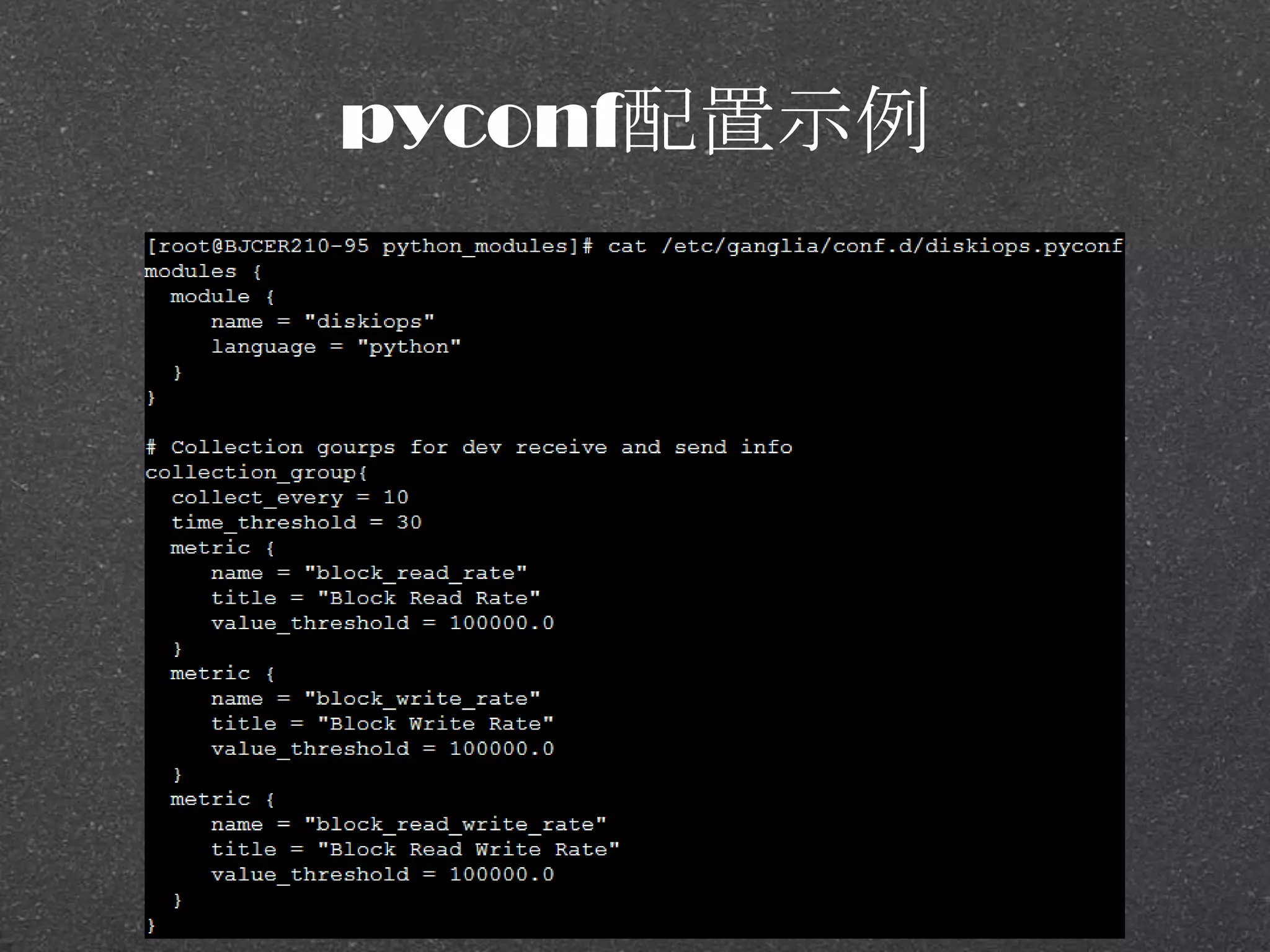






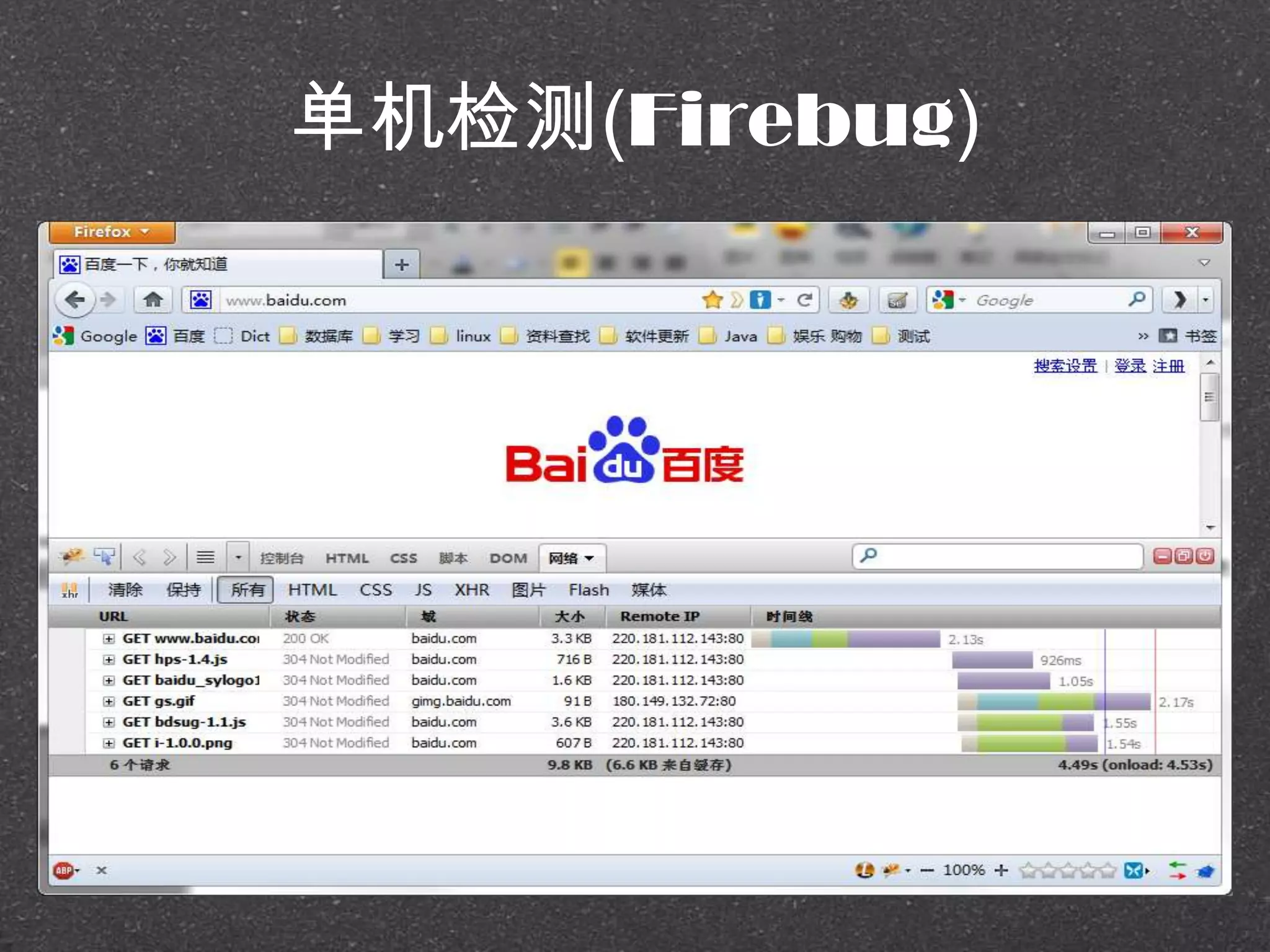
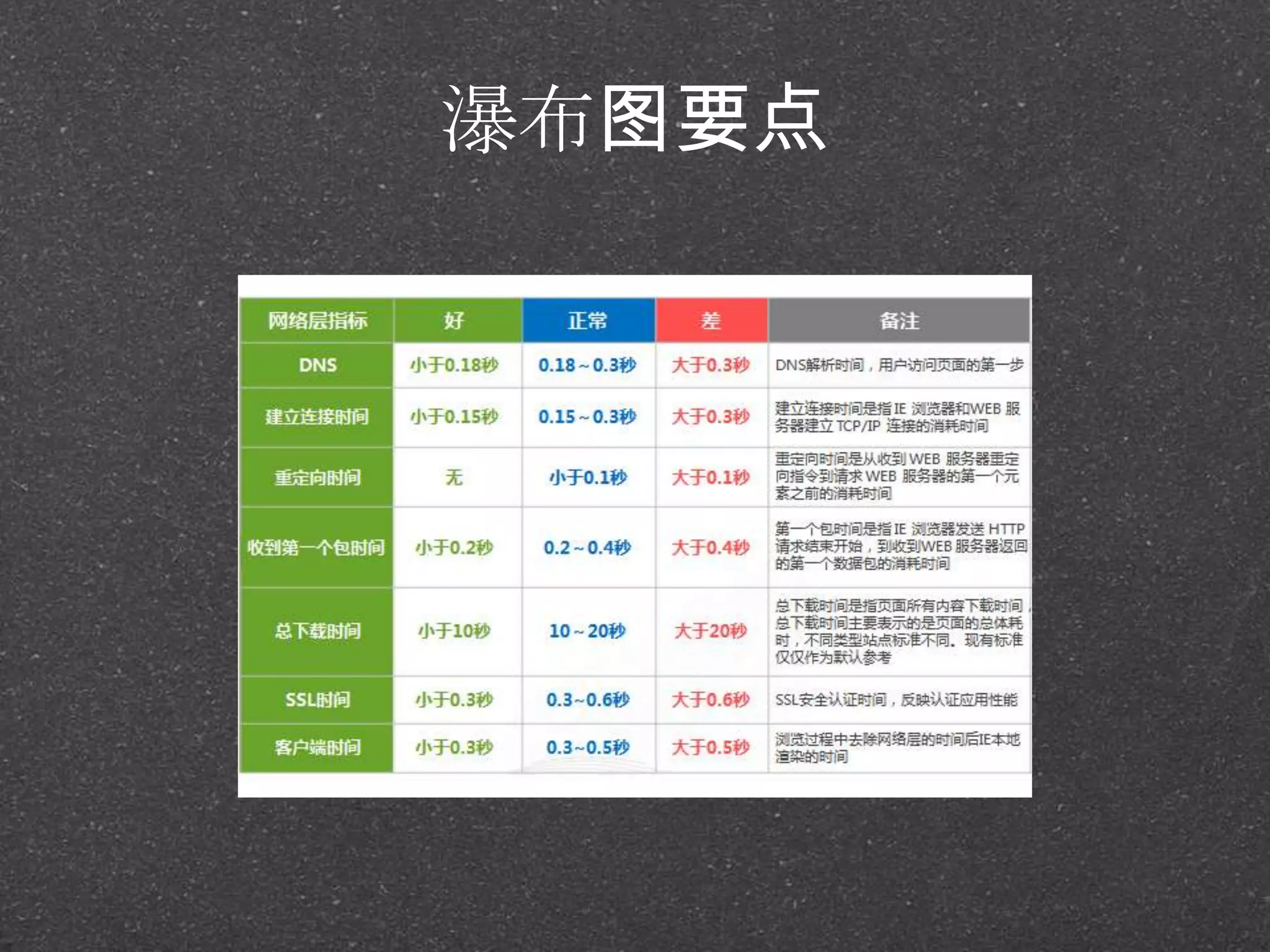


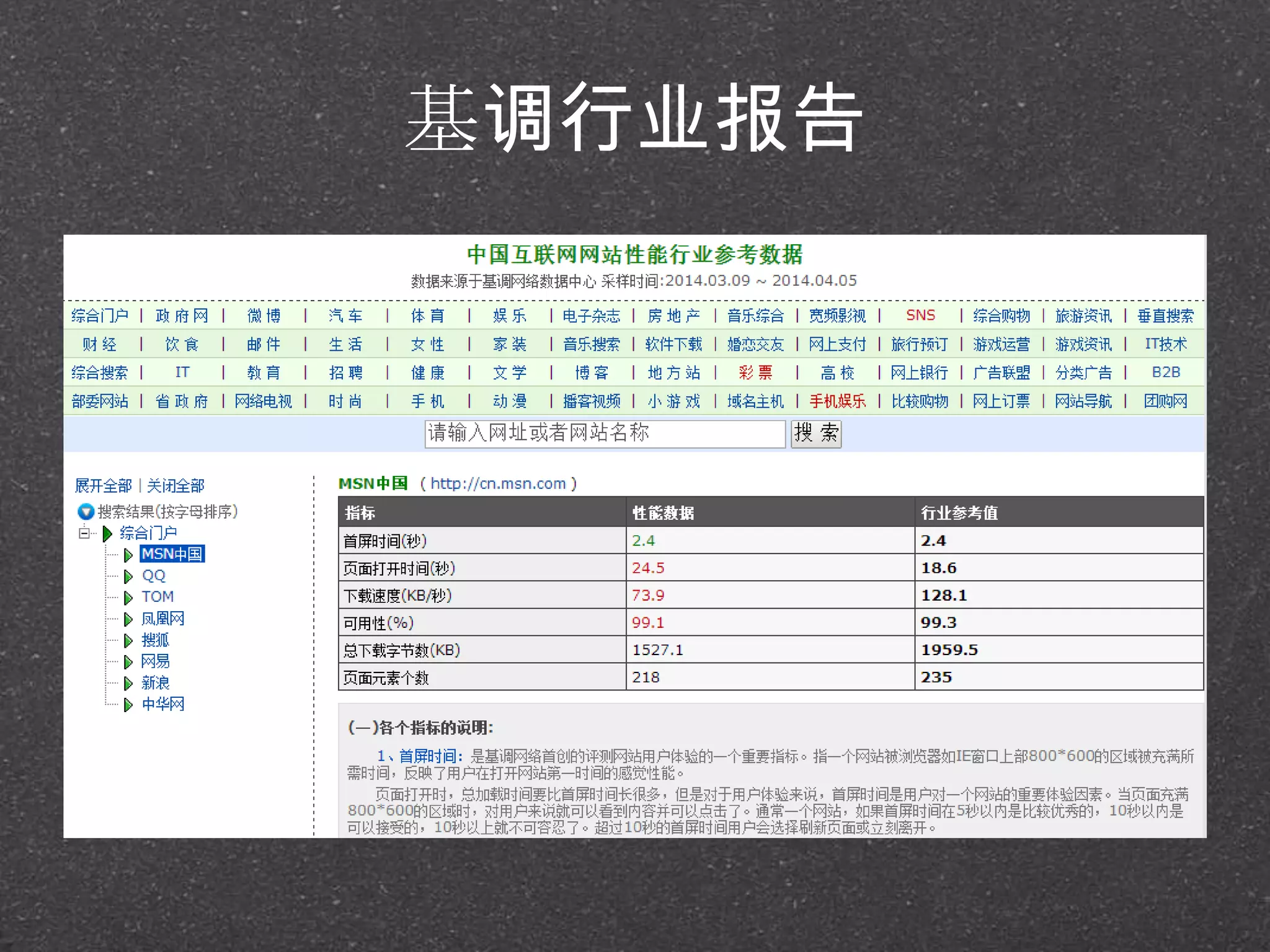
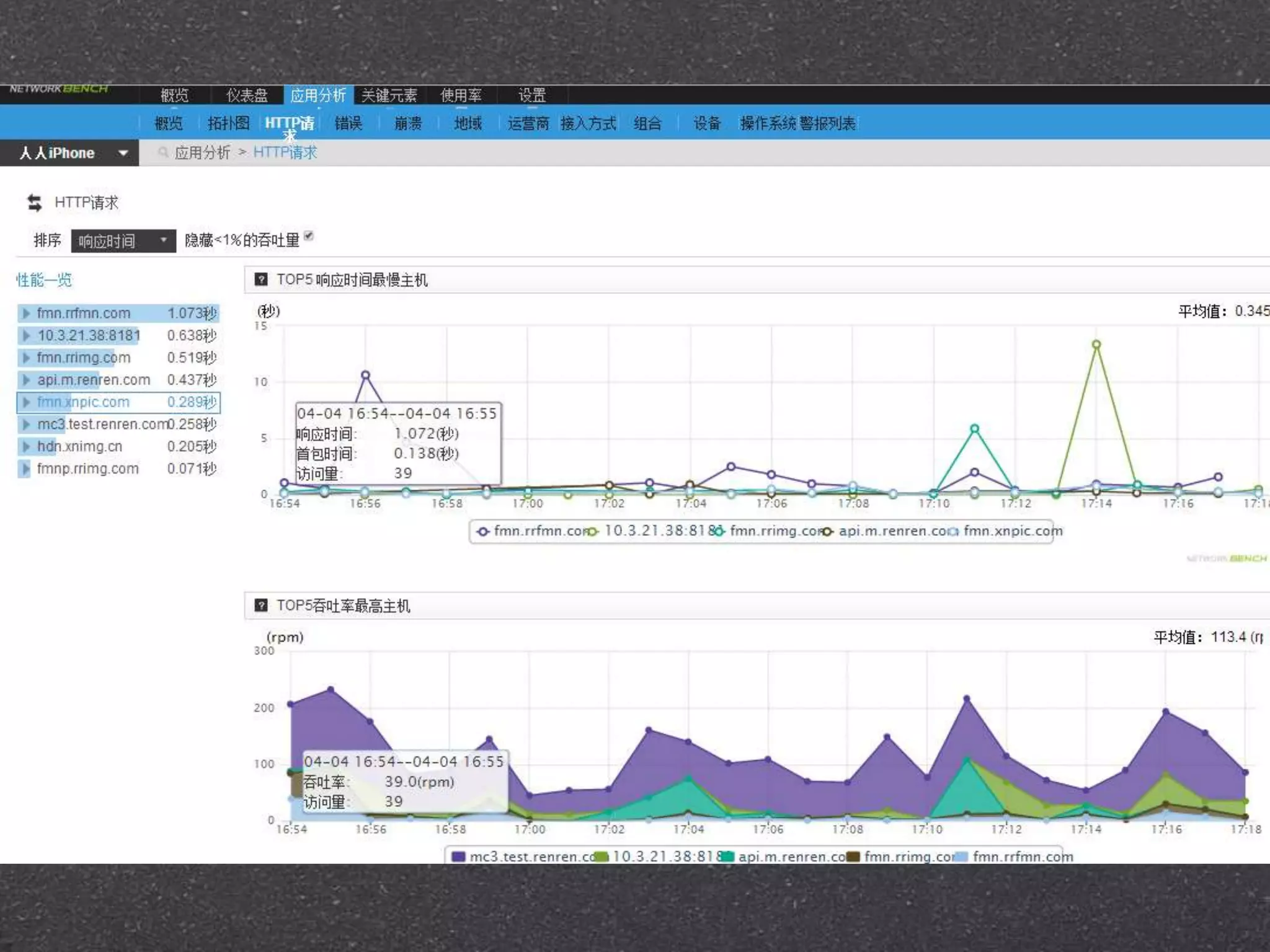


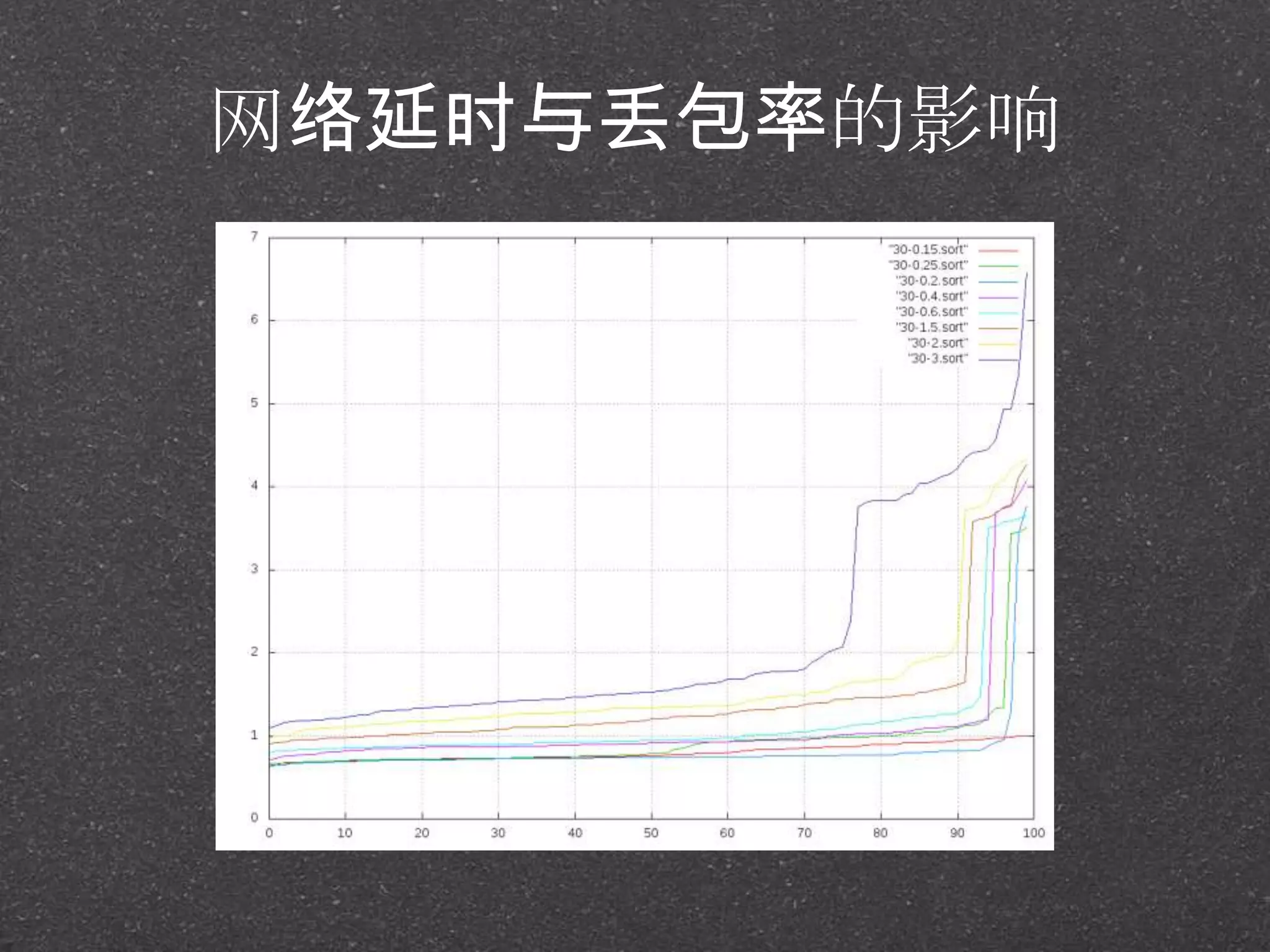


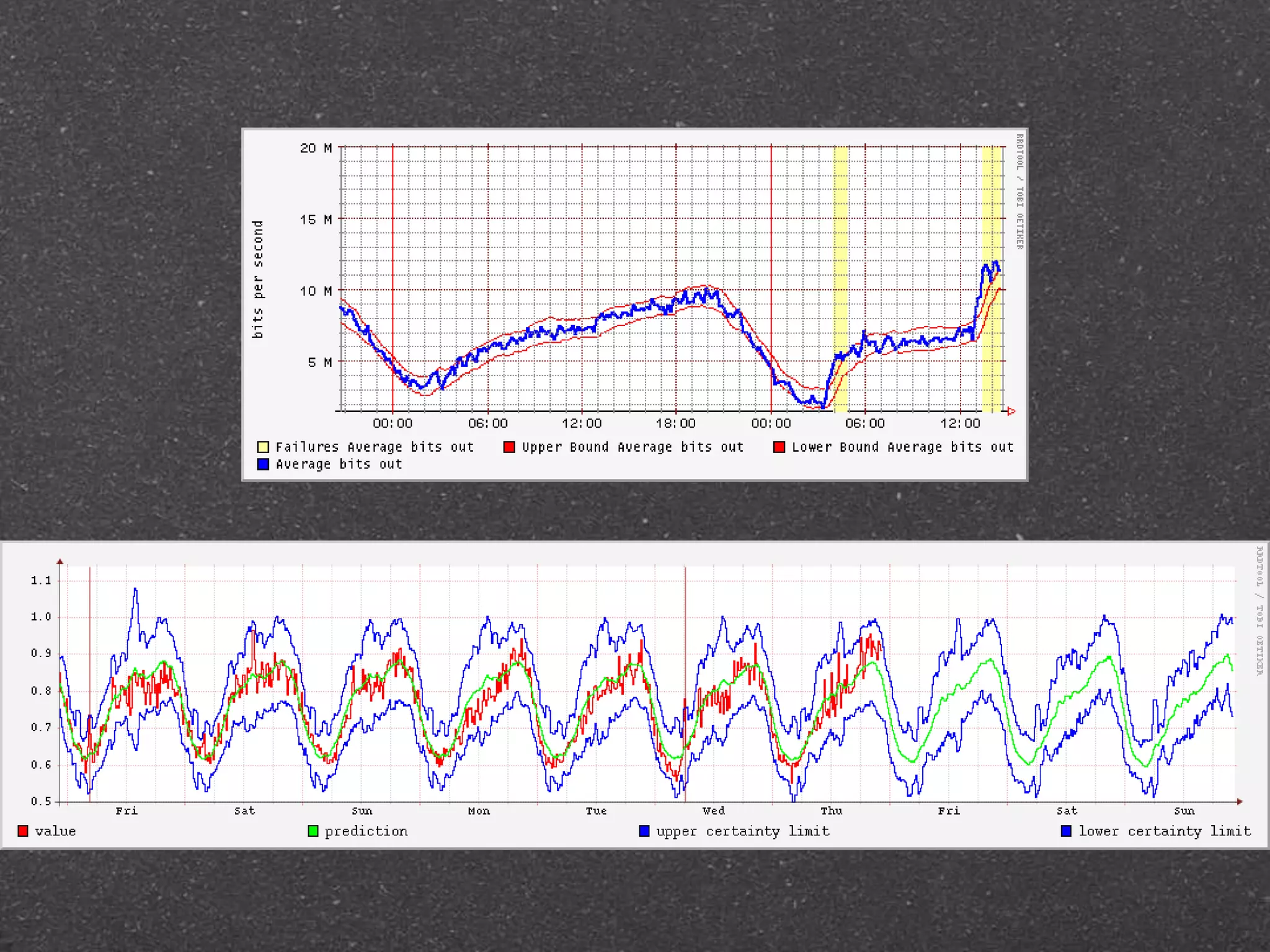
![RRDtool示例
# rrdtool graph - --alt-y-grid --rigid --color 'BACK#E0E0E0'
--color 'SHADEA#FFFFFF' --color 'SHADEB#FFFFFF'
--start '-1D' --end N --width 280 --height 200
--title '__SUMMARY__:__SUMMARY__[ last 1D]'
--vertical-label ' per secend'
DEF:value=requests.rrd:value:AVERAGE
DEF:seasonal=requests.rrd:value:SEASONAL
DEF:hwpredict=requests.rrd:value:HWPREDICT
DEF:devpredict=requests.rrd:value:DEVPREDICT
DEF:failures=requests.rrd:value:FAILURES
CDEF:predict_upper=hwpredict,devpredict,2,*,+
CDEF:predict_lowper=hwpredict,devpredict,2,*,-
TICK:failures#ffffa0:1.0:'Failures Average bits out'
LINE:value#0022e9: requests.rrd
GPRINT:value:LAST:' Predict:%8.2lf %s'
GPRINT:value:MAX:' Max:%8.2lf %s'
GPRINT:value:AVERAGE:' Average:%8.2lf %s'
LINE:seasonal#2266ee:SEASONAL_requests.rrd
LINE:predict_upper#229900:PREDICT_UP_requests.rrd
LINE:predict_lowper#992200:PREDICT_LOW_requests.rrd](https://image.slidesharecdn.com/monitor-140423011609-phpapp01/75/Monitor-is-all-for-ops-94-2048.jpg)
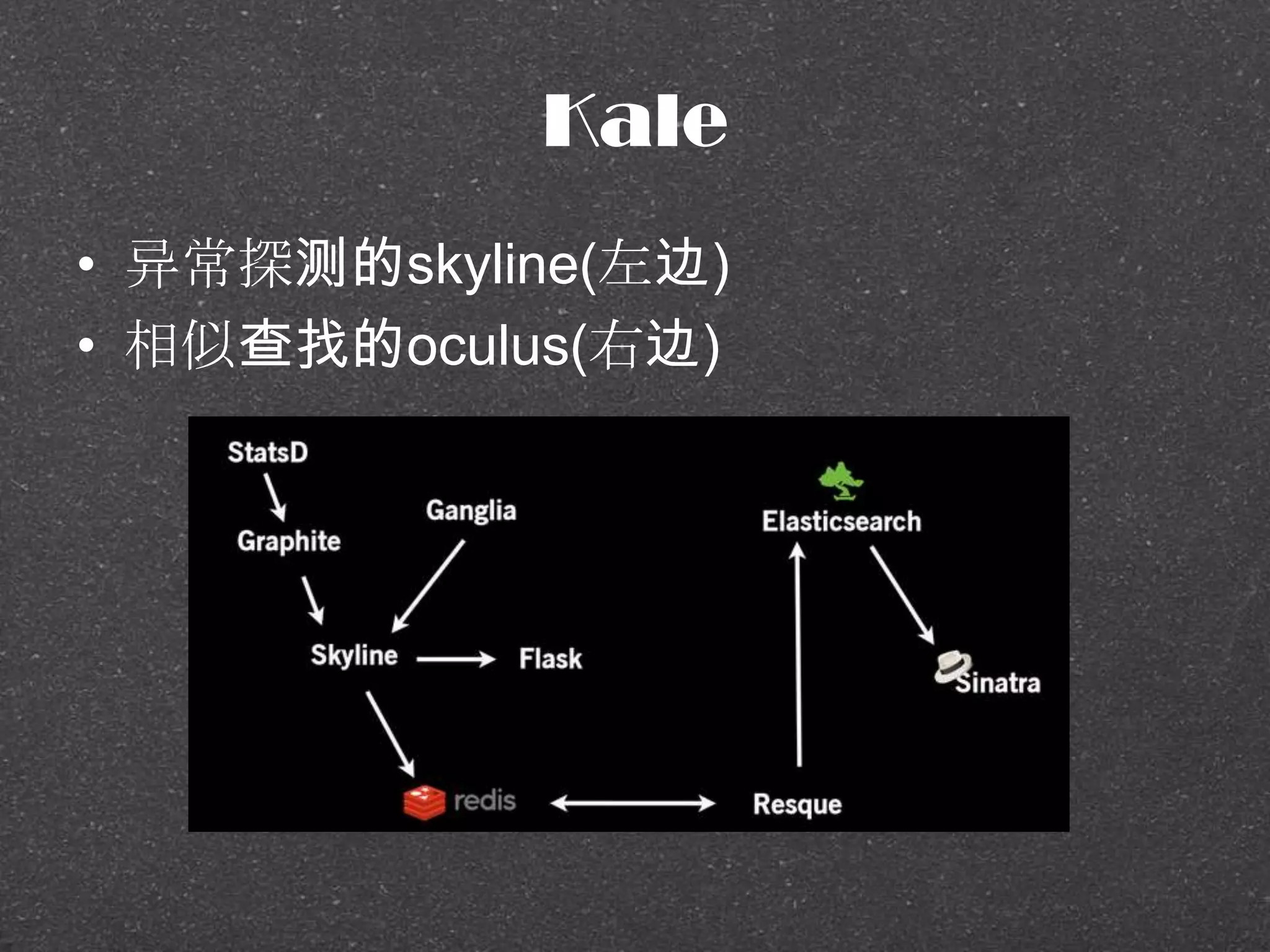
















![[Crypto Course] Block Cipher Mode](https://cdn.slidesharecdn.com/ss_thumbnails/block-cipher-mode-201031064606-thumbnail.jpg?width=640&height=640&fit=bounds)








































