


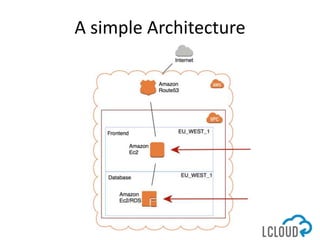
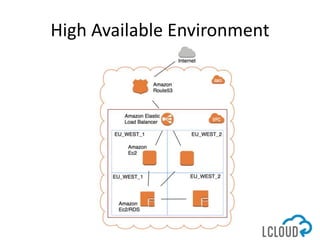









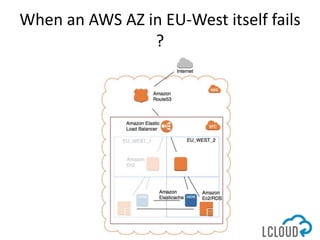
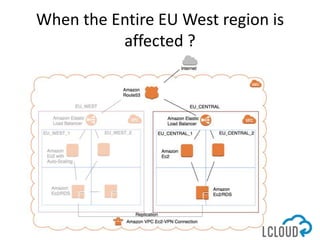






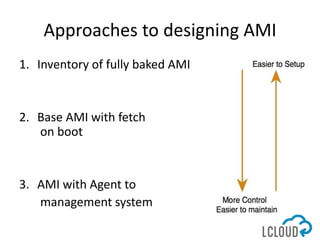
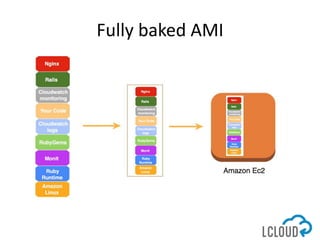

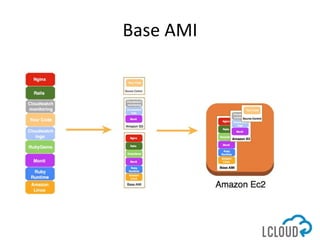


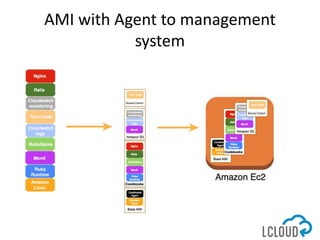


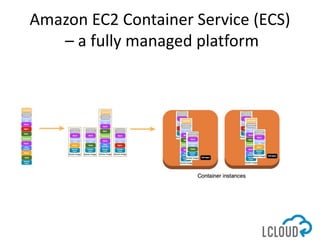


The document outlines best practices for designing and implementing IT architecture on AWS, emphasizing resilience against failures and the use of stateless solutions. It provides various strategies for ensuring high availability, including the configuration of backups and data replication across regions, distributed via CloudFormation templates. Additionally, it discusses automated deployment systems and the use of micro-services architecture to enhance flexibility and resource management.


































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)










