Downloaded 11 times
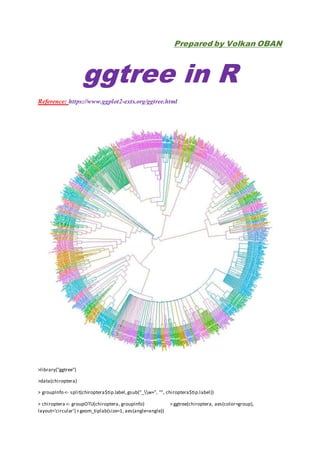


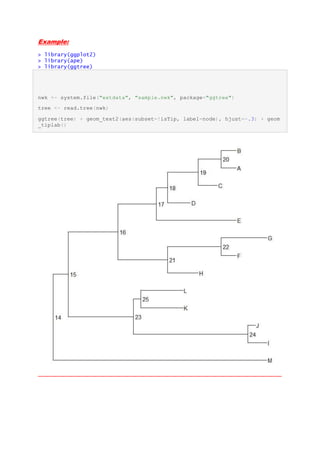

The document provides a guide on using the 'ggtree' package in R for visualizing phylogenetic trees. It includes examples of how to read and plot tree data from different formats, including BEAST and Newick files. Key functions such as 'ggtree()', 'geom_tiplab()', and 'geom_text()' are demonstrated to customize tree layouts and aesthetics.







![Some R Examples[R table and Graphics] -Advanced Data Visualization in R (Some...](https://cdn.slidesharecdn.com/ss_thumbnails/exampless-160922204223-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)













