Downloaded 12 times







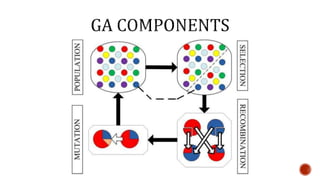










Genetic algorithms are a metaheuristic inspired by the process of natural selection that generates solutions to optimization and search problems. They use techniques like inheritance, mutation, selection, and crossover to evolve a population of solutions over multiple generations towards better solutions. Genetic algorithms represent potential solutions as chromosomes and evaluate their fitness to survive and reproduce, selecting the fittest to pass traits to the next generation.
























































