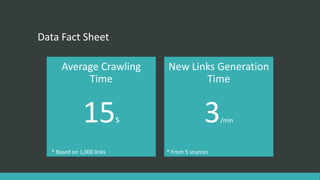
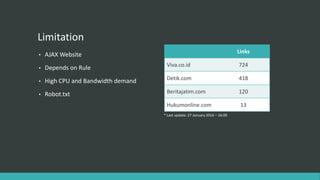
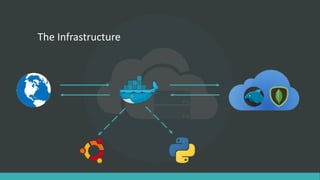
The document describes a generic crawler that can crawl websites without APIs by using rules to extract data. It discusses the crawler's infrastructure, introduction to crawler rules using XPATH and CSS expressions, the crawl procedure of generating links, crawling based on links and saving data to a local DB, and limitations such as not working on AJAX sites. The goal is to build a multipurpose crawler powered by cloud computing that can extract information from various websites.




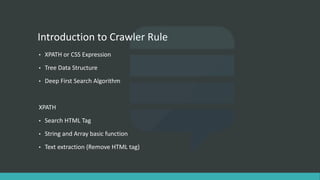
![Introduction to Crawler Rule
XPATH: //div[@class=‘detail_content]](https://image.slidesharecdn.com/2e43d69f-38ef-4609-b557-e838081039da-160324055309/85/Generic-Crawler-6-320.jpg)