Downloaded 114 times










![Data Consistency with replicas
Node 1
{ "name": "Barbie Computer",
"price": 15.50,
"tags" : [
"doll",
"barbie" Node 2
]}
write to all Node 3
Node 1
read from one Node 2
Node 3](https://image.slidesharecdn.com/geecon-nosqldatagrid-110516163434-phpapp02/75/GeeCon-2011-NoSQL-and-In-Memory-Data-Grids-from-a-developer-perspective-22-2048.jpg)
![Data Consistency with replicas
{ "name": "Barbie Computer", Node 1
"price": 15.50,
"tags" : [
"doll",
"barbie"
]}
Node 2
write to one
Node 3
Node 1
Node 2
read from all Node 3](https://image.slidesharecdn.com/geecon-nosqldatagrid-110516163434-phpapp02/75/GeeCon-2011-NoSQL-and-In-Memory-Data-Grids-from-a-developer-perspective-23-2048.jpg)

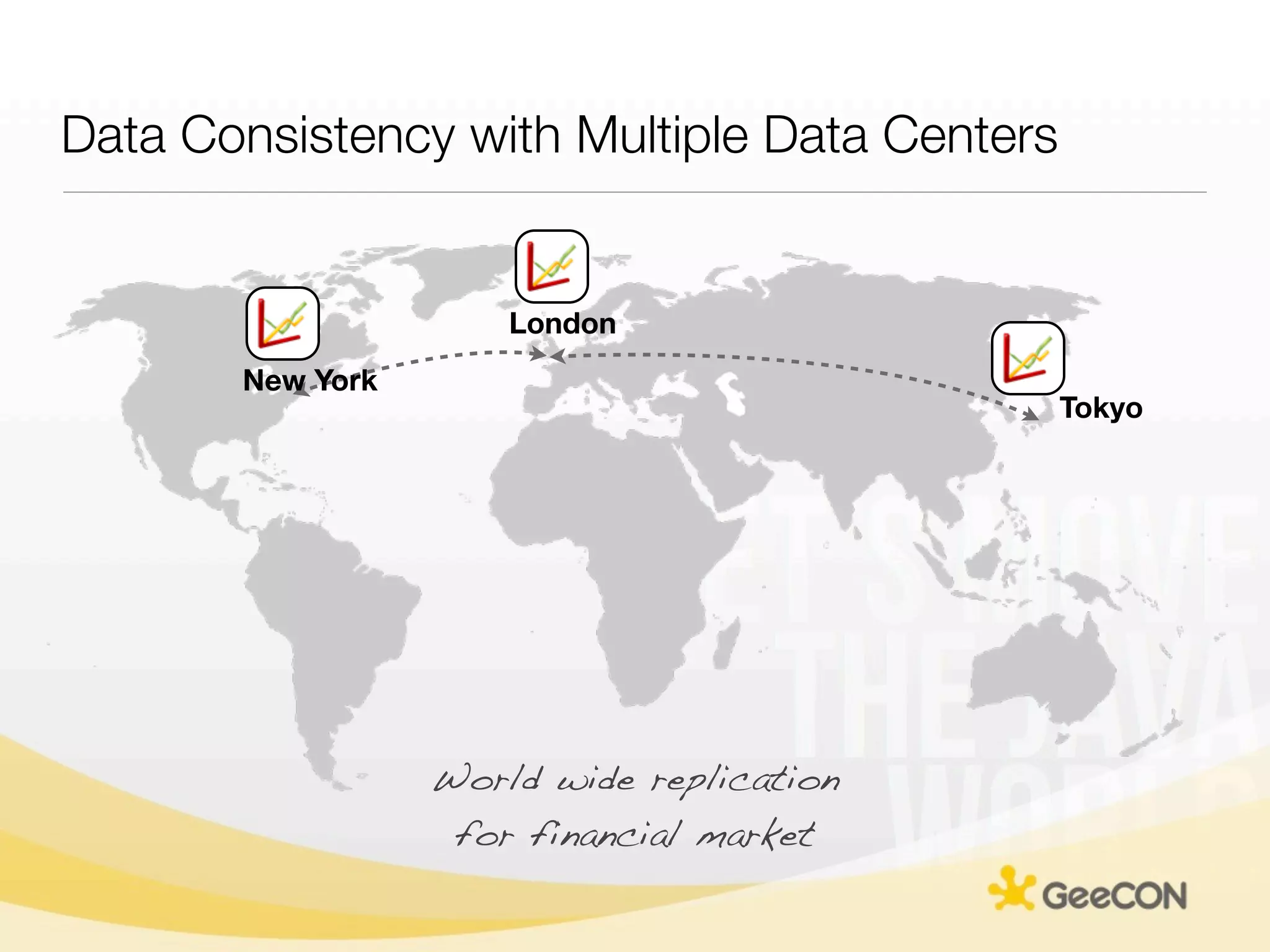
![Data Consistency with Multiple Data Centers
{ "name": "Barbie Computer",
"price": 15.50,
"tags" : [
"doll",
"barbie"
]}
{ "name": "Barbie Computer",
"price": 15.50,
"tags" : [
West Coast "doll",
"barbie"
]}
East Coast](https://image.slidesharecdn.com/geecon-nosqldatagrid-110516163434-phpapp02/75/GeeCon-2011-NoSQL-and-In-Memory-Data-Grids-from-a-developer-perspective-25-2048.jpg)
![Data Consistency with Multiple Data Centers
set price to $ 20.00
{ "name": "Barbie Computer",
"price": 20.00,
"tags" : [
"doll",
"barbie"
]}
{ "name": "Barbie Computer",
"price": 15.50,
West Coast "tags" : [
"doll",
"barbie"
]}
East Coast
propagation delay !](https://image.slidesharecdn.com/geecon-nosqldatagrid-110516163434-phpapp02/75/GeeCon-2011-NoSQL-and-In-Memory-Data-Grids-from-a-developer-perspective-26-2048.jpg)
![Data Consistency with Multiple Data Centers
set price to $ 20.00
{ "name": "Barbie Computer",
"price": 20.00,
"tags" : [
"doll",
"barbie"
]} { "name": "Barbie Computer",
"price": 15.50,
West Coast "tags" : [
"doll",
"barbie",
“girl”
]}
East Coast
add tag “girl”
reconciliation API needed !](https://image.slidesharecdn.com/geecon-nosqldatagrid-110516163434-phpapp02/75/GeeCon-2011-NoSQL-and-In-Memory-Data-Grids-from-a-developer-perspective-27-2048.jpg)
![Data Consistency with Multiple Data Centers
set price to $ 20.00
{ "name": "Barbie Computer",
"price": 20.00,
"tags" : [
"doll",
"barbie"
]} { "name": "Barbie Computer",
"price": 15.50,
West Coast "tags" : [
"doll",
"barbie",
“girl”
]}
East Coast
add tag “girl”
Network partitioning](https://image.slidesharecdn.com/geecon-nosqldatagrid-110516163434-phpapp02/75/GeeCon-2011-NoSQL-and-In-Memory-Data-Grids-from-a-developer-perspective-28-2048.jpg)



![Example with a user profile
johndoe User profile as byte[]
Similar to a Java
HashMap](https://image.slidesharecdn.com/geecon-nosqldatagrid-110516163434-phpapp02/75/GeeCon-2011-NoSQL-and-In-Memory-Data-Grids-from-a-developer-perspective-35-2048.jpg)







![Example with an item of a catalog
{
"name": "Iphone",
"price": 559.0,
item_1 "vendor": "Apple",
"rating": 4.6,
"tags": [ "phone", "touch" ]
}
The database is aware of
document’s fields and
can offers complex
queries](https://image.slidesharecdn.com/geecon-nosqldatagrid-110516163434-phpapp02/75/GeeCon-2011-NoSQL-and-In-Memory-Data-Grids-from-a-developer-perspective-44-2048.jpg)



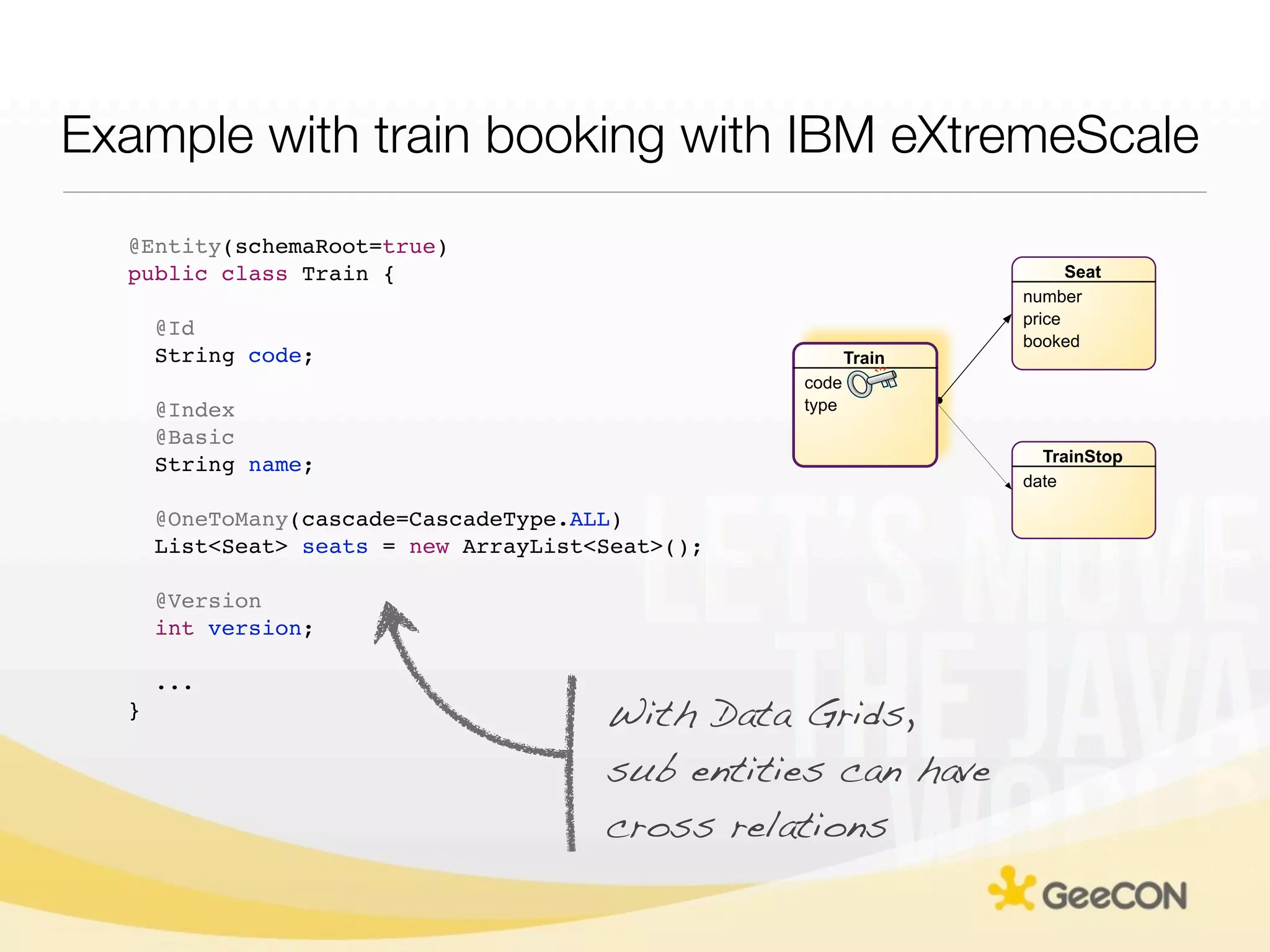




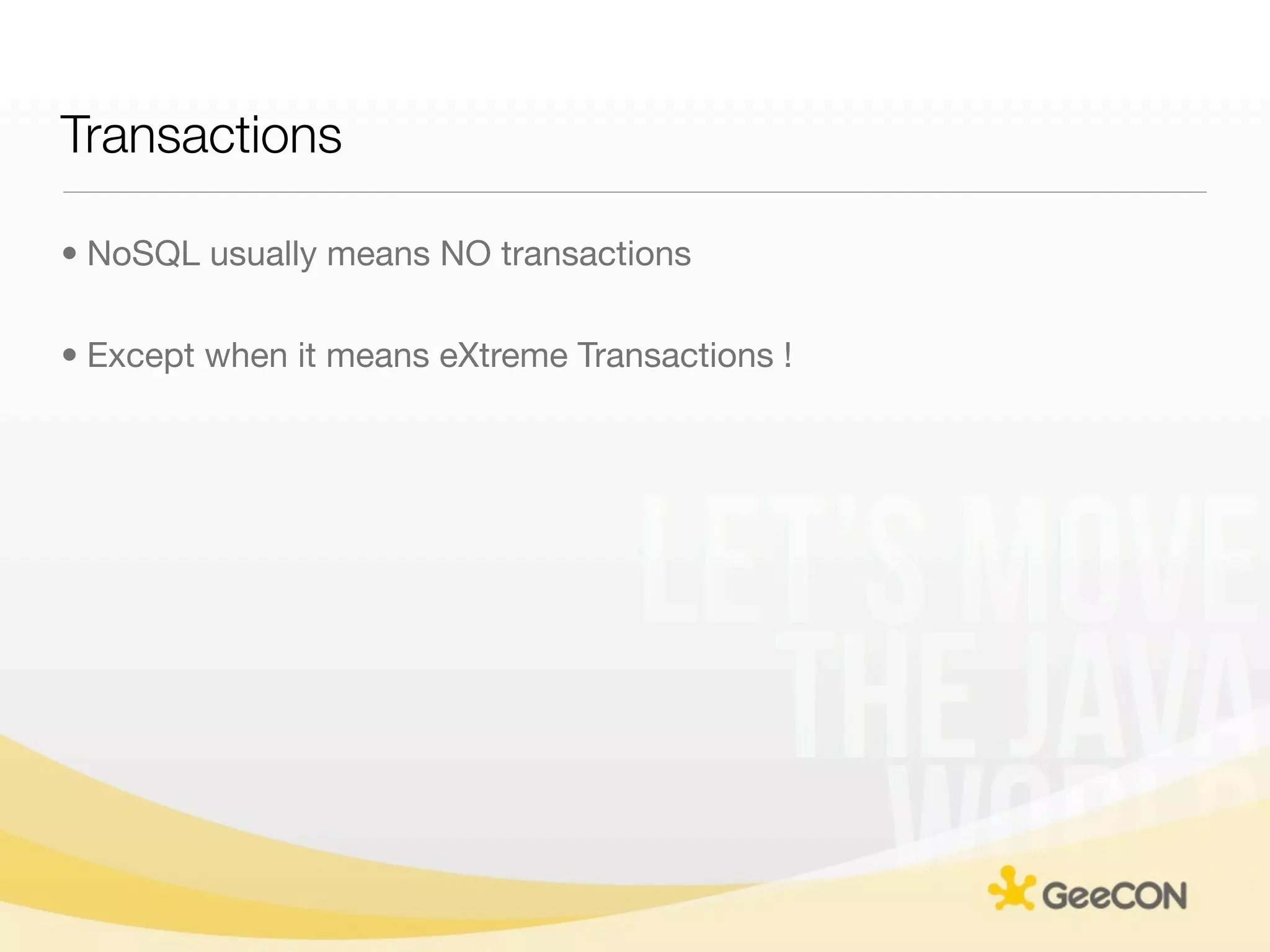
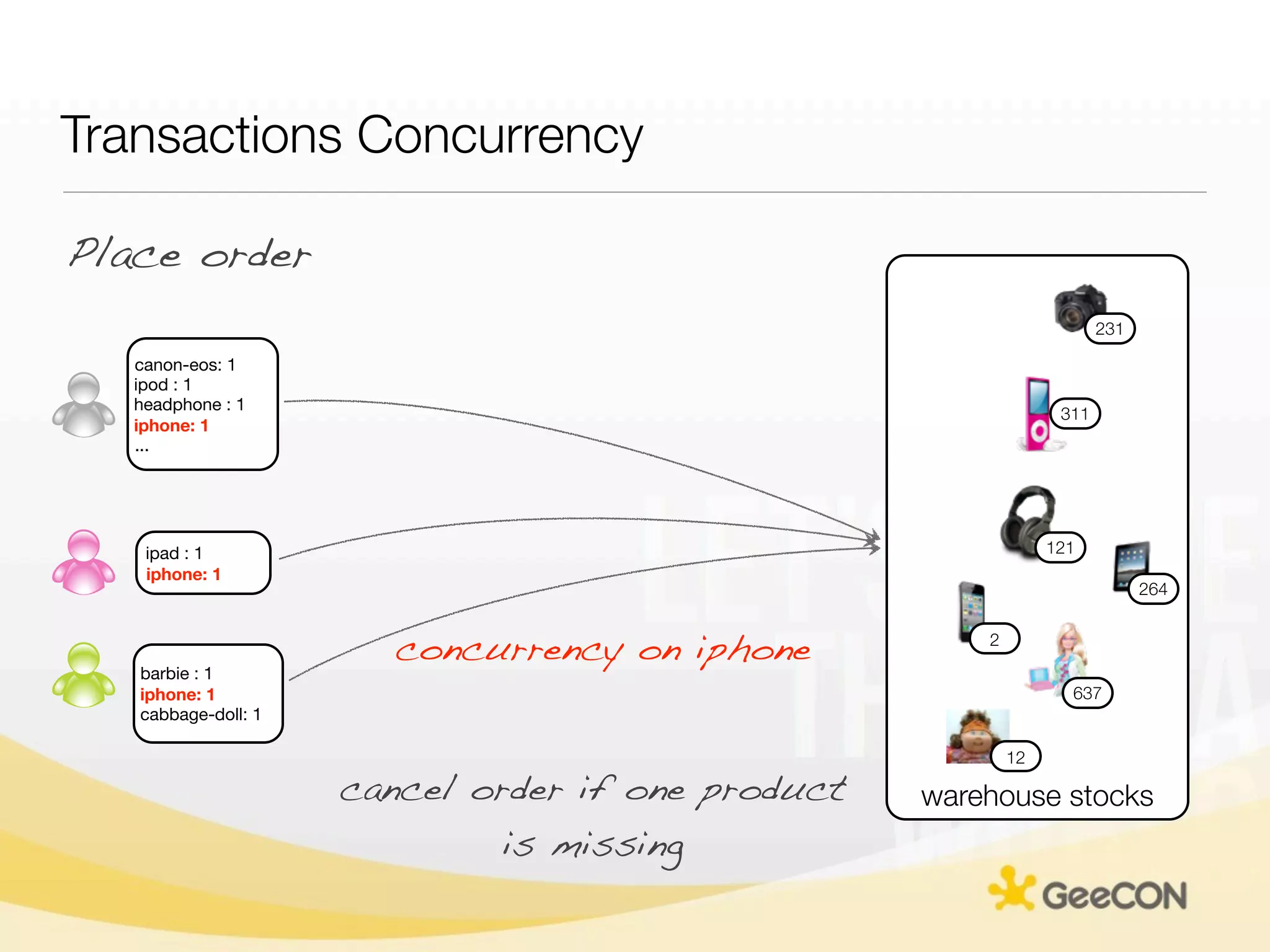
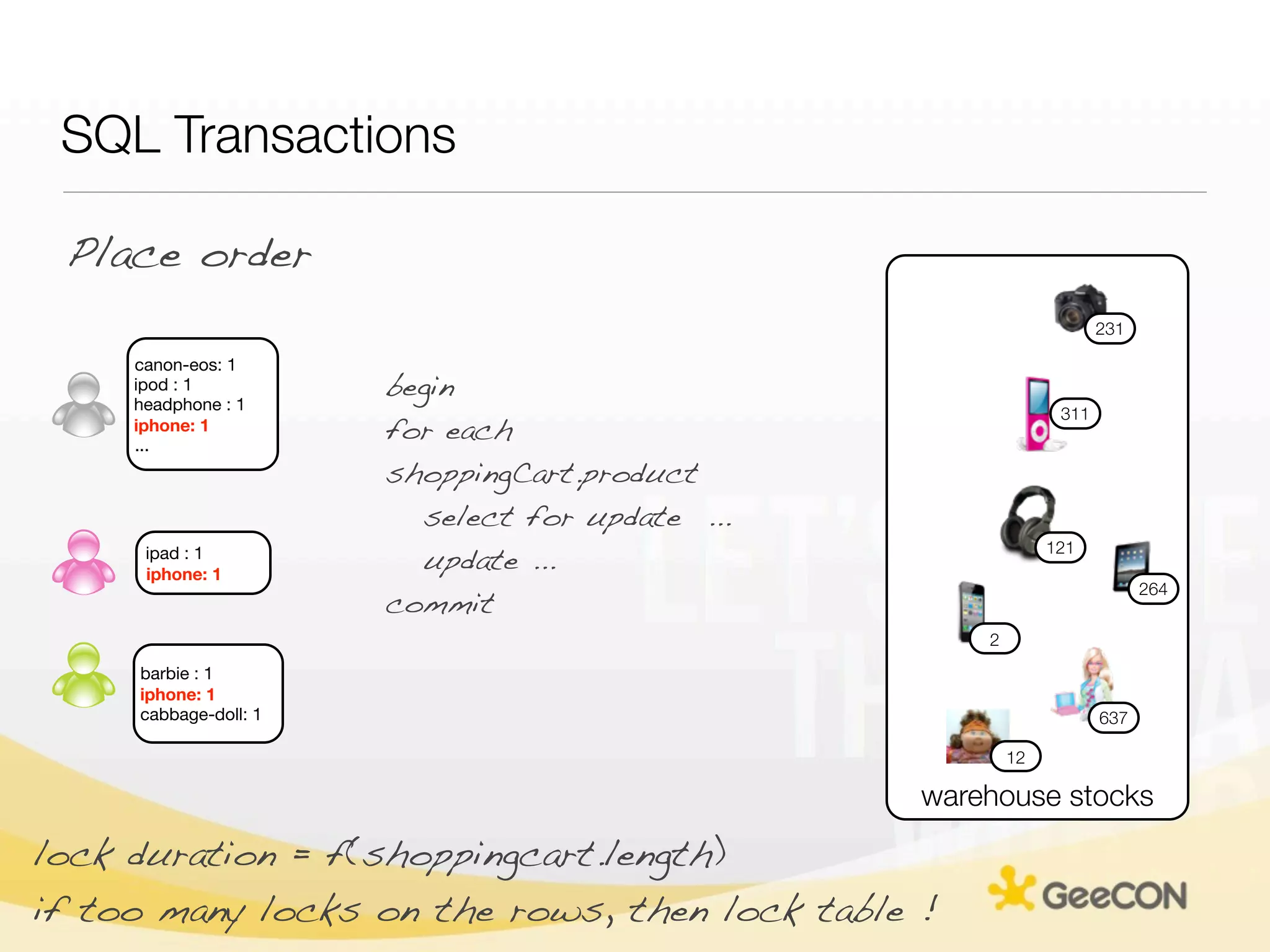
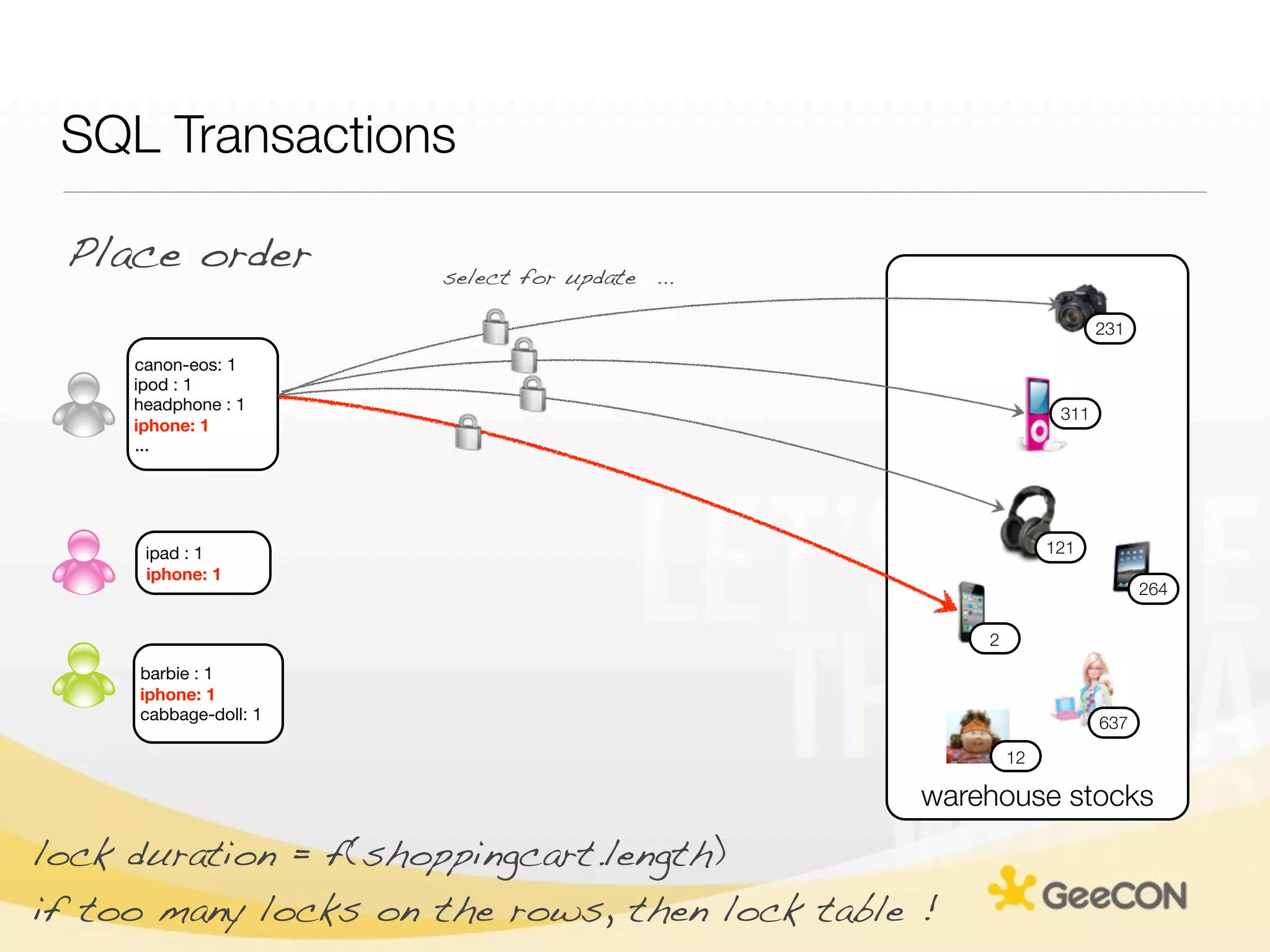
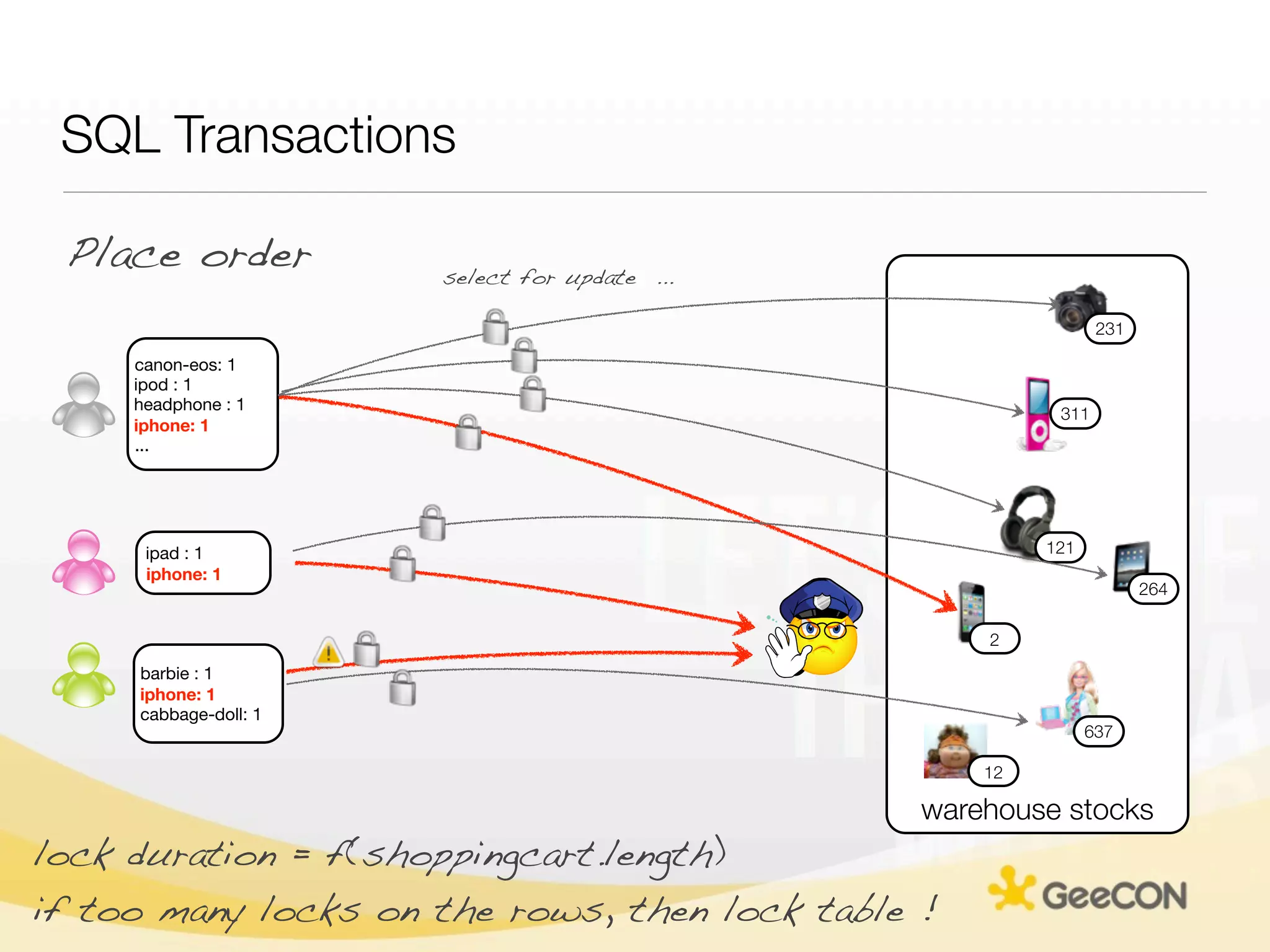
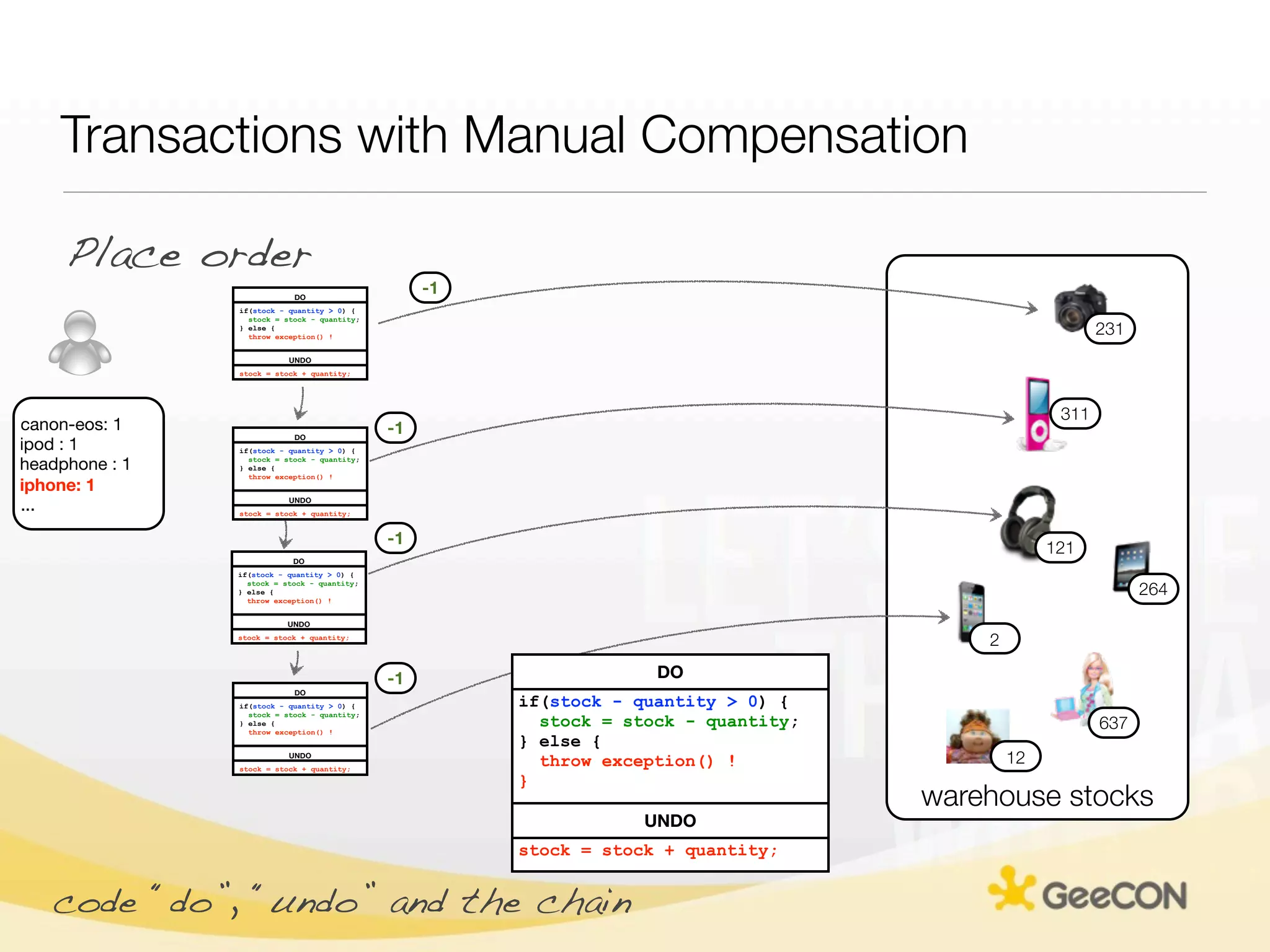
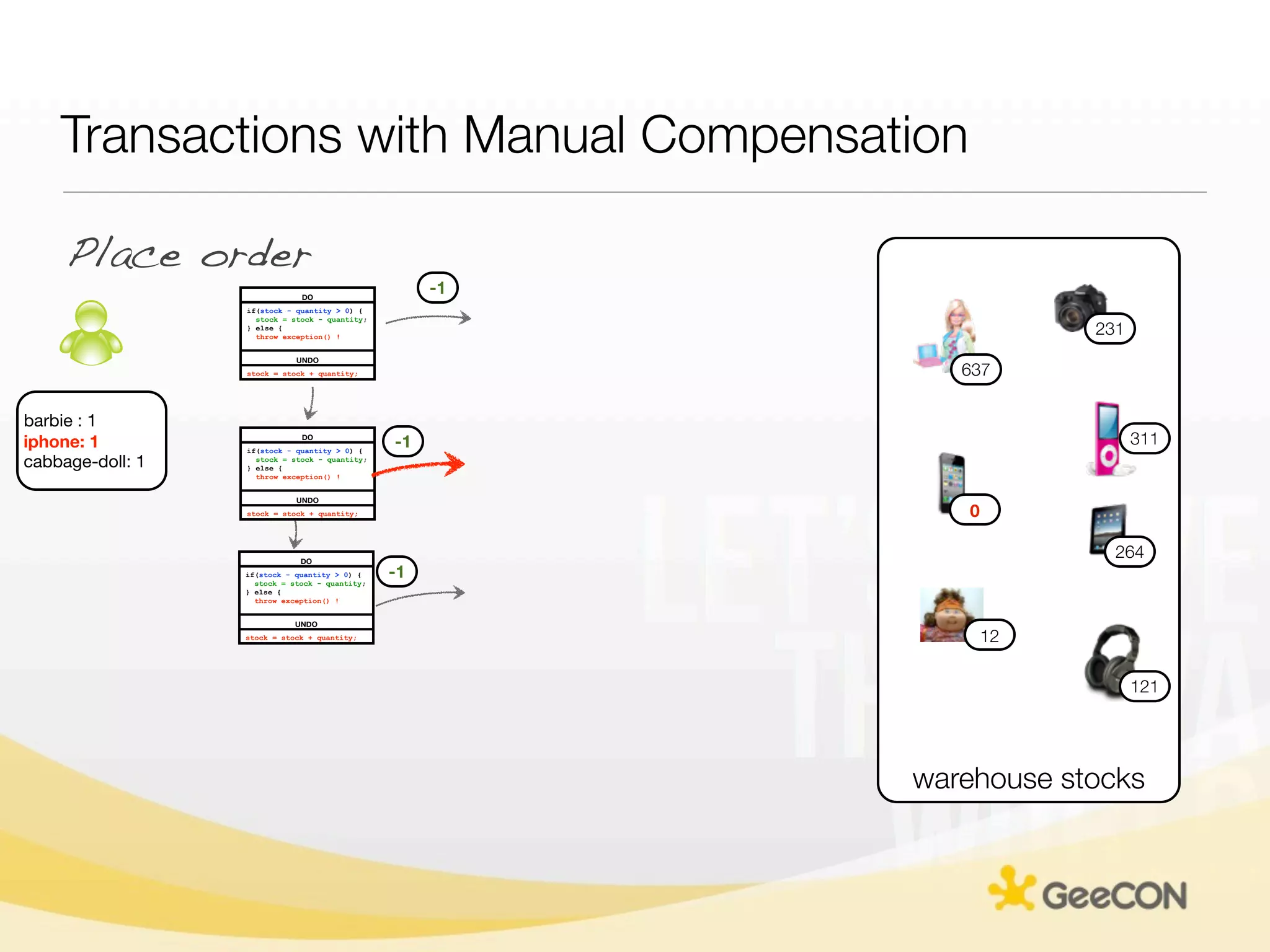
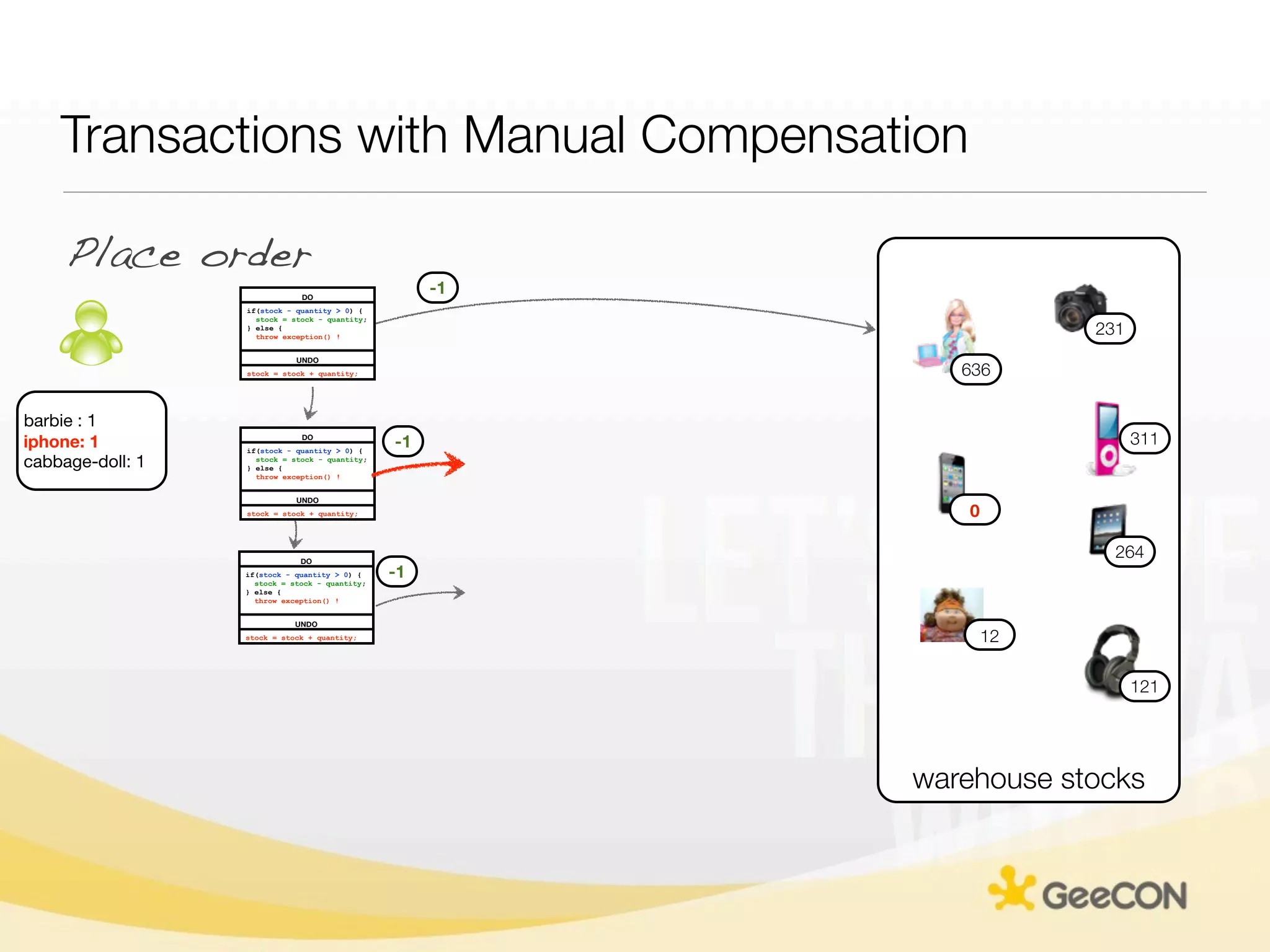
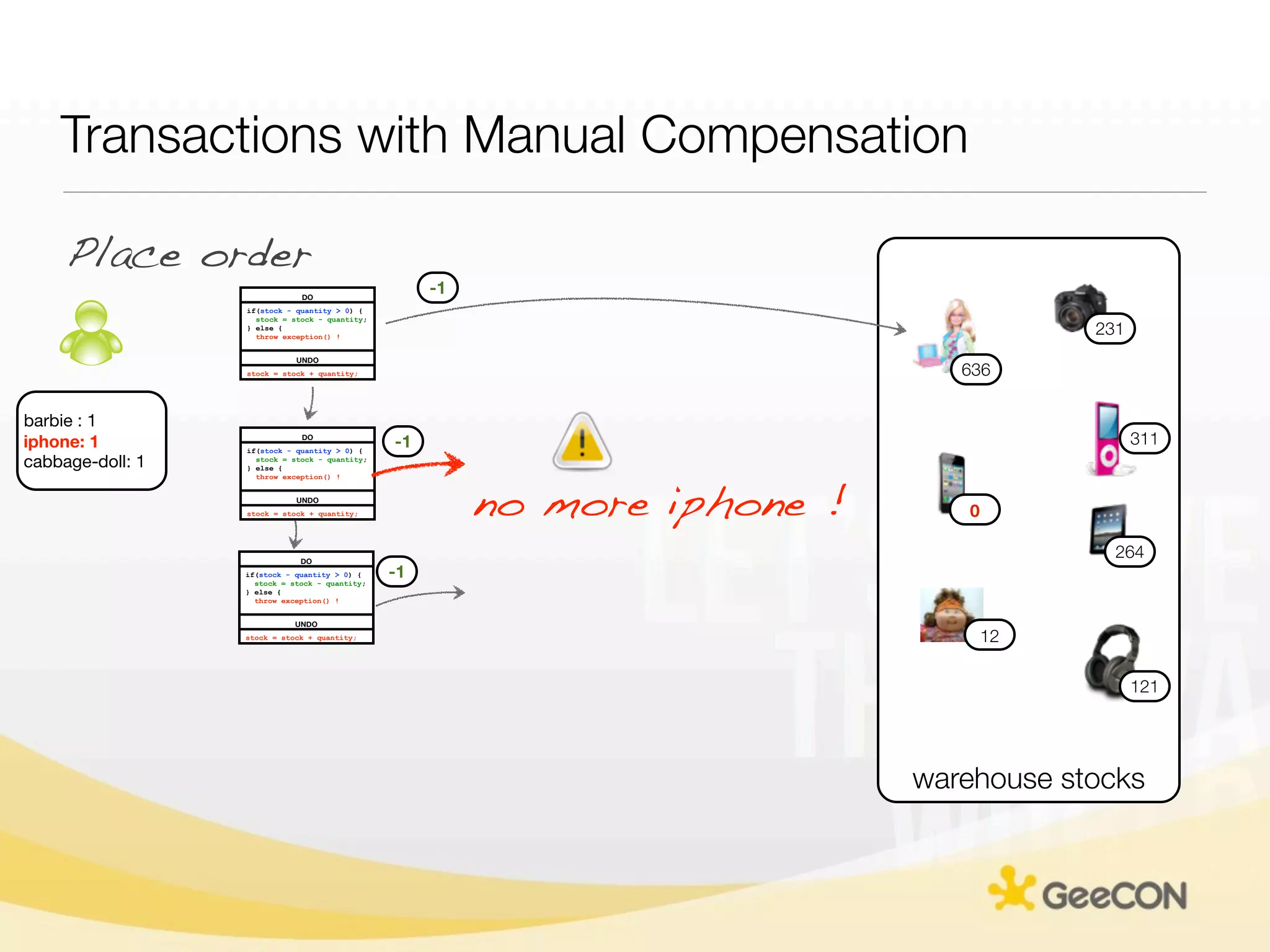
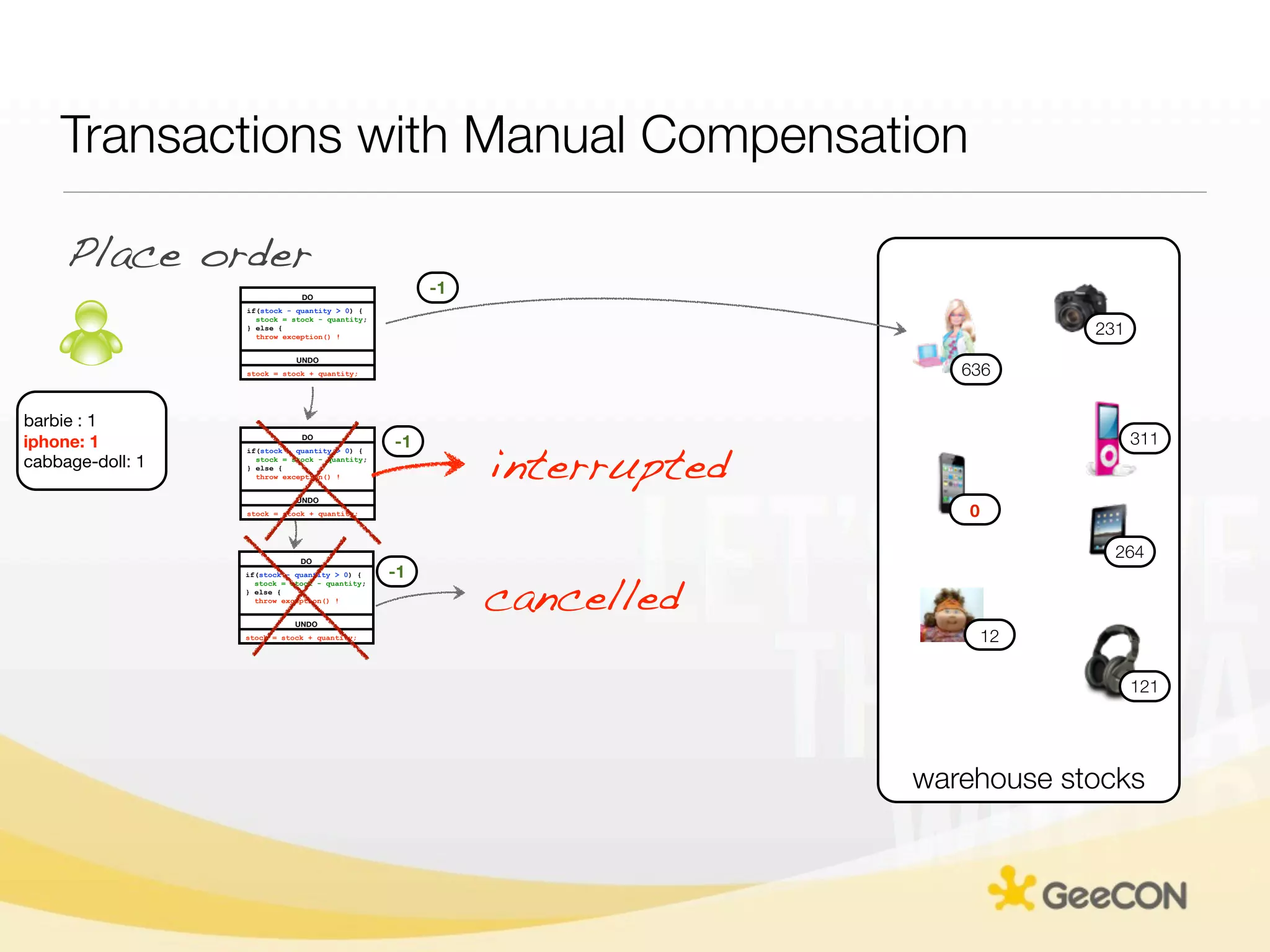
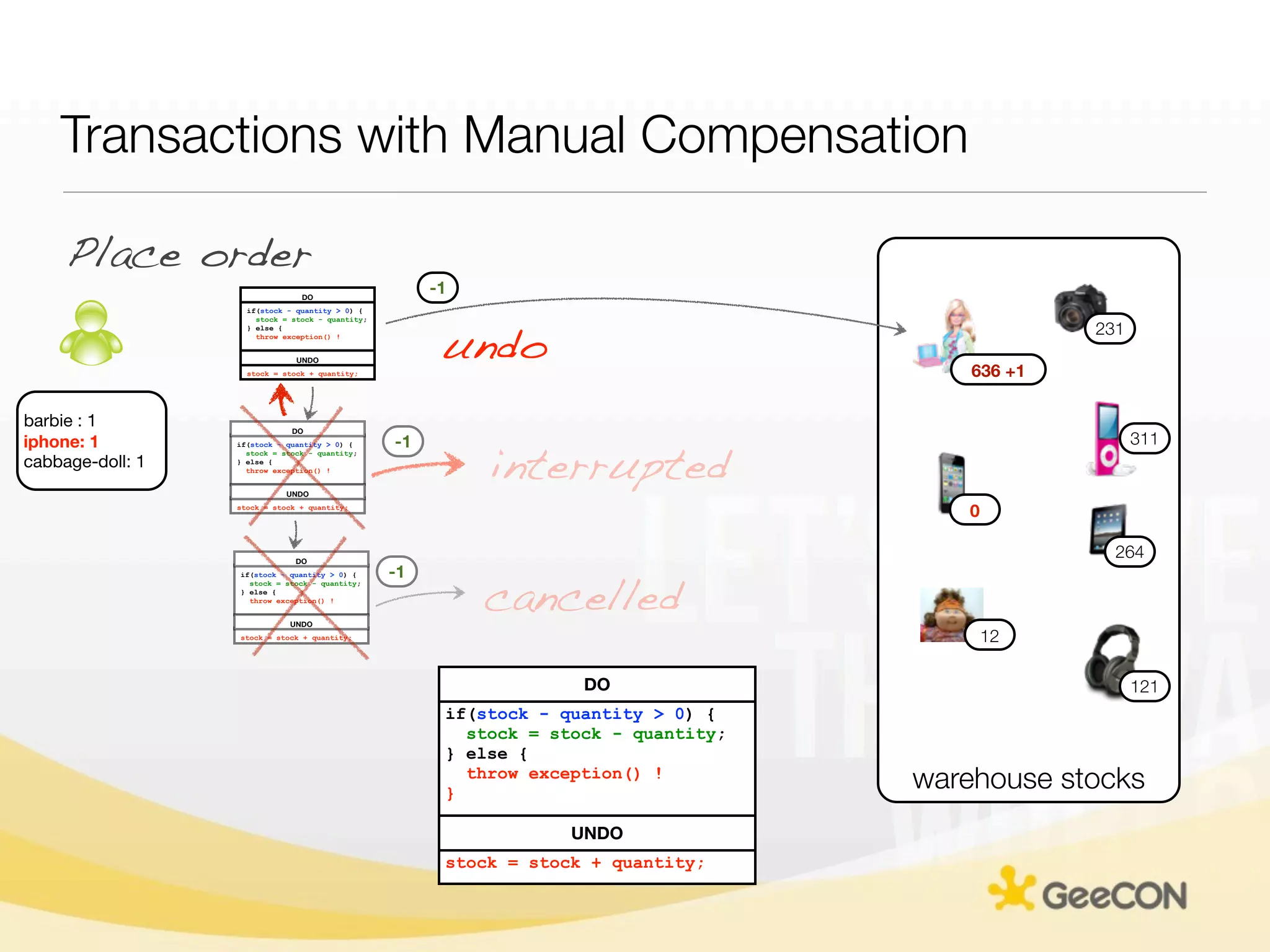







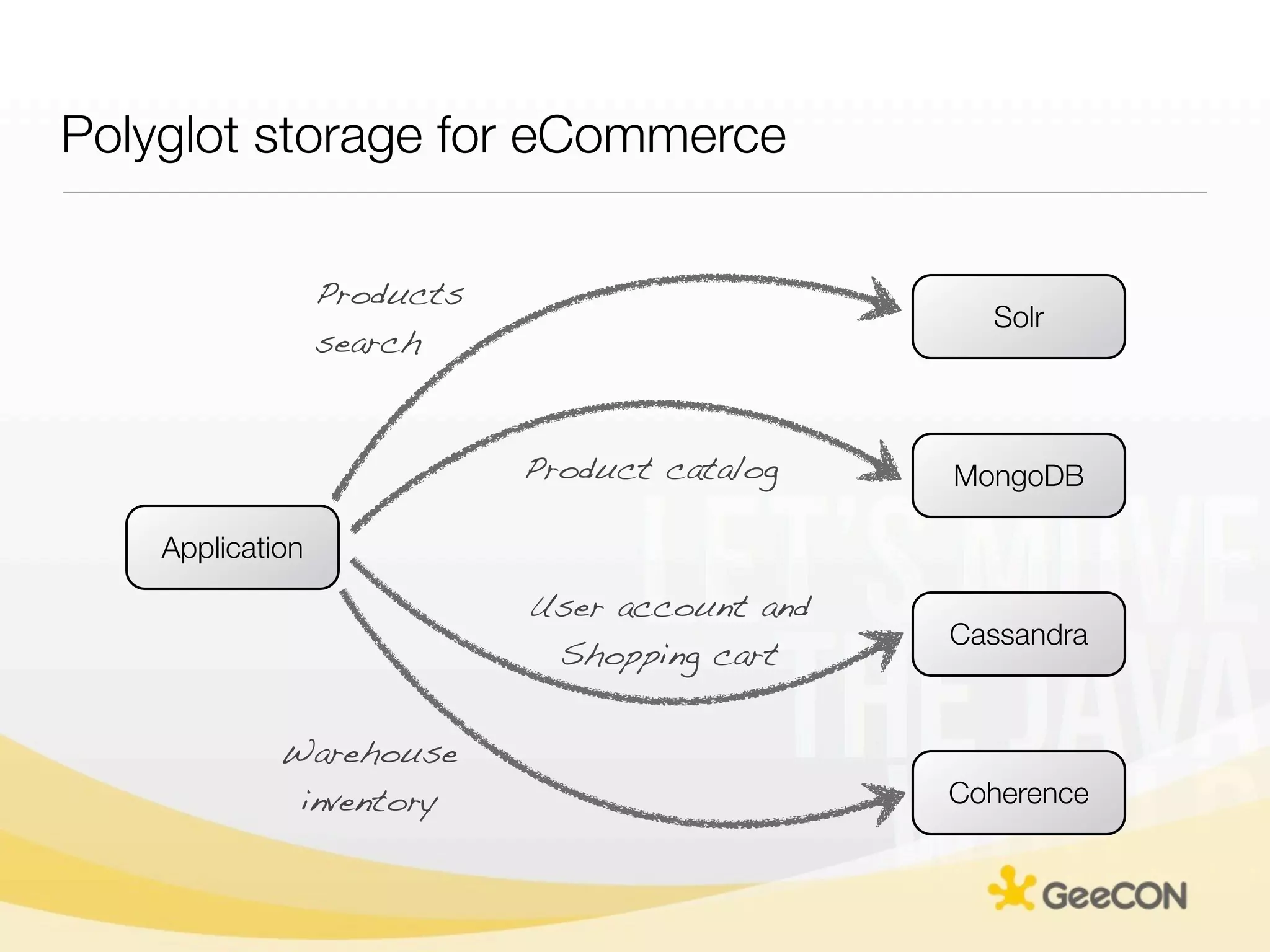


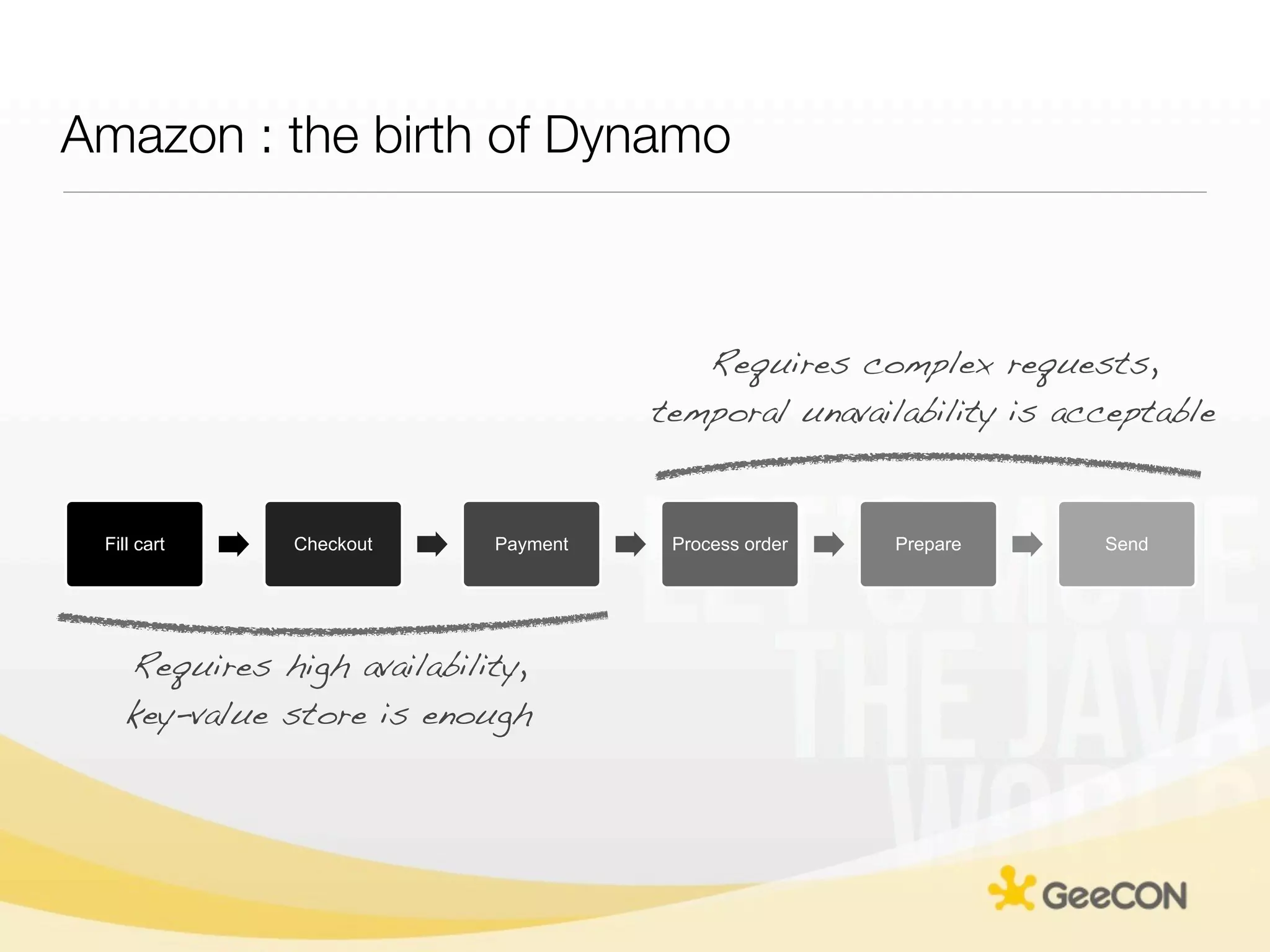
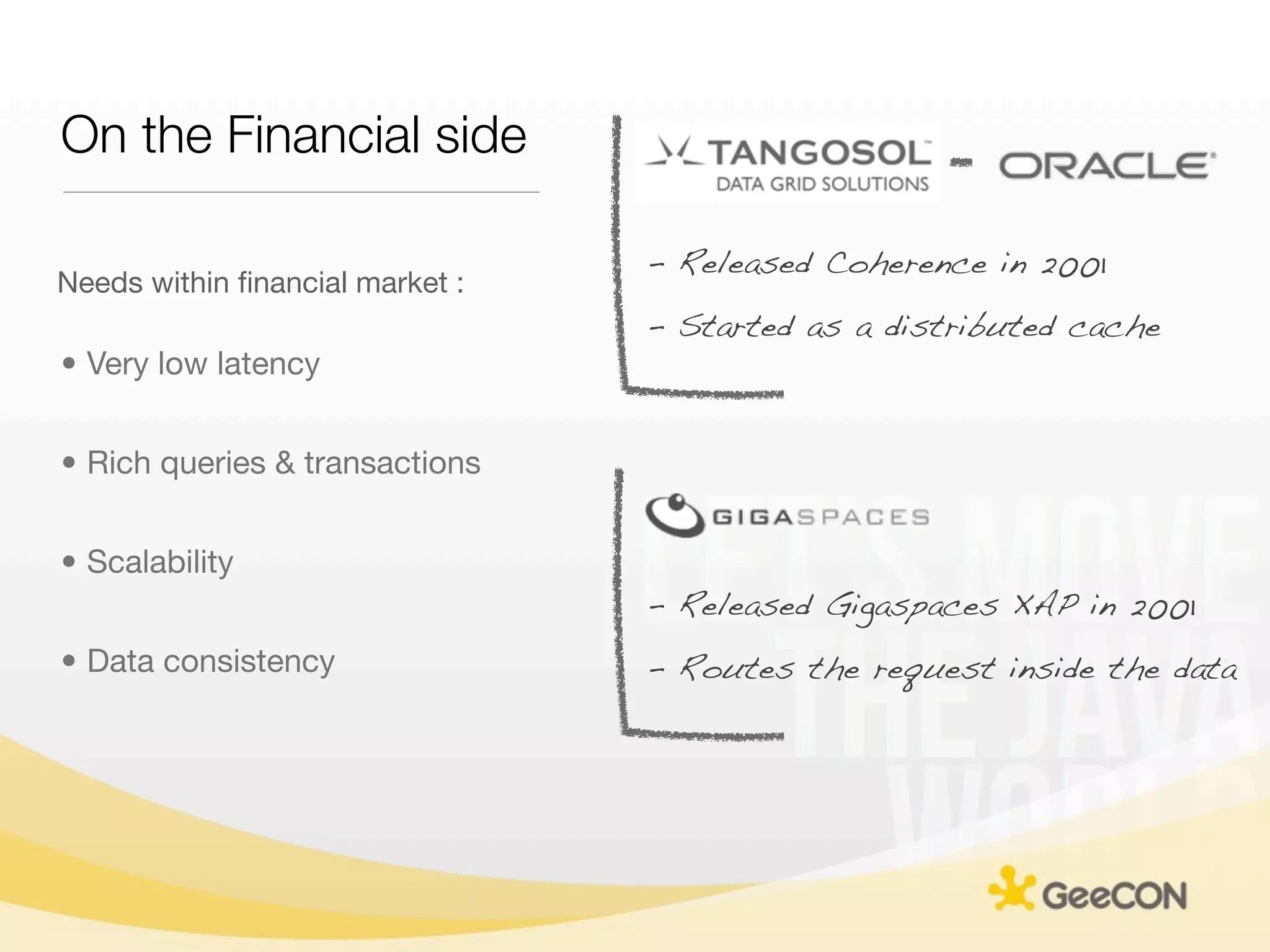
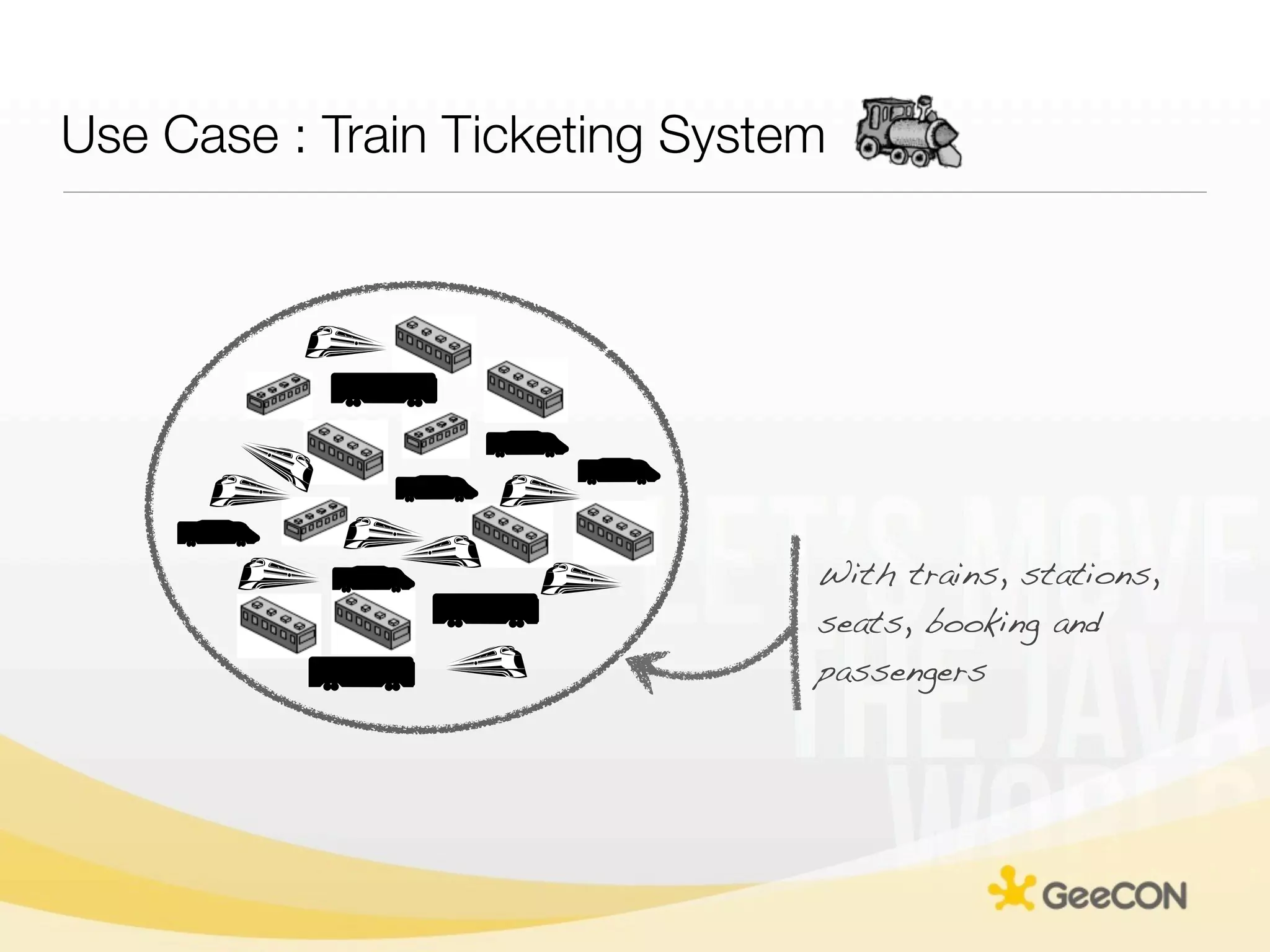
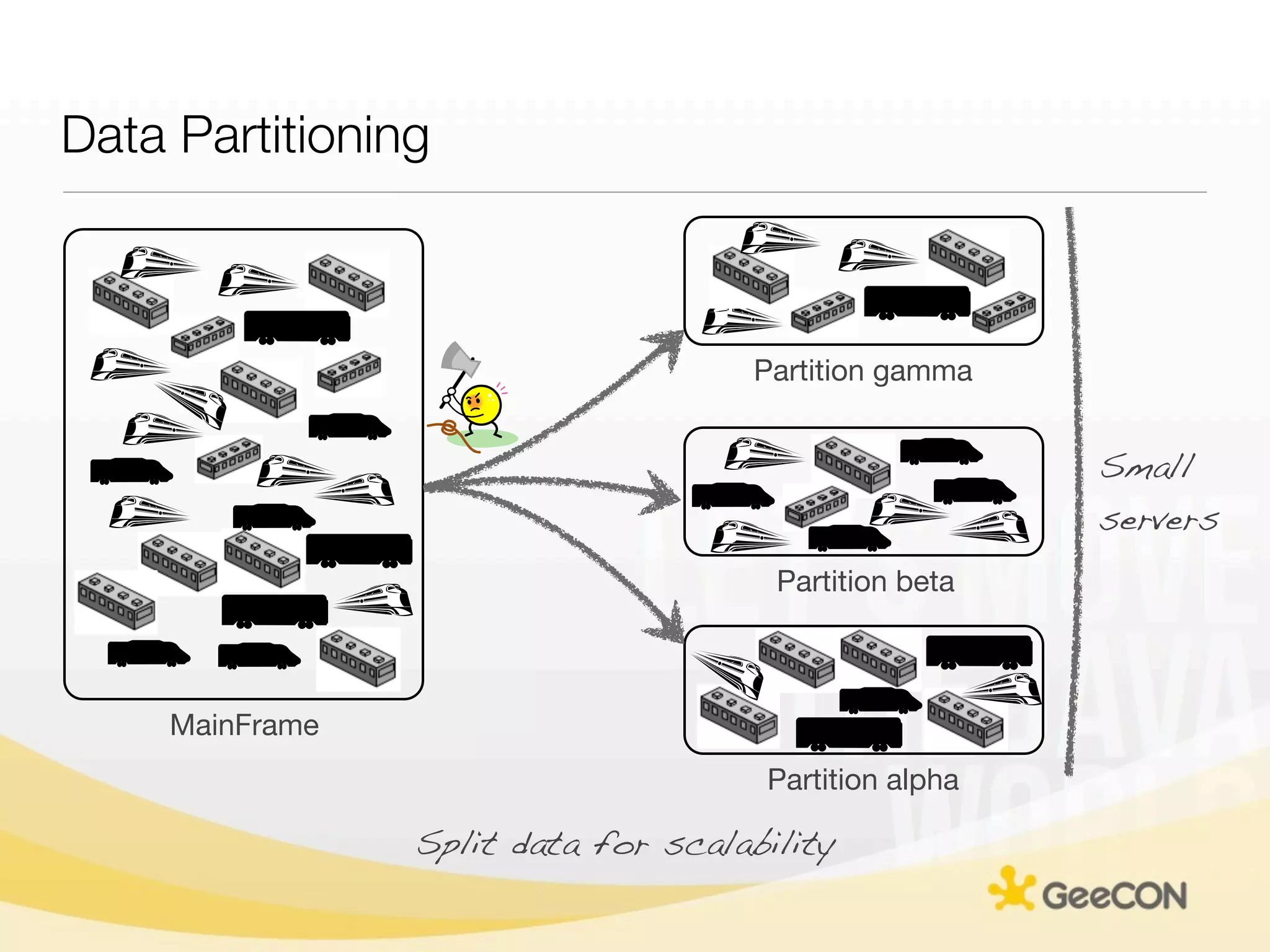
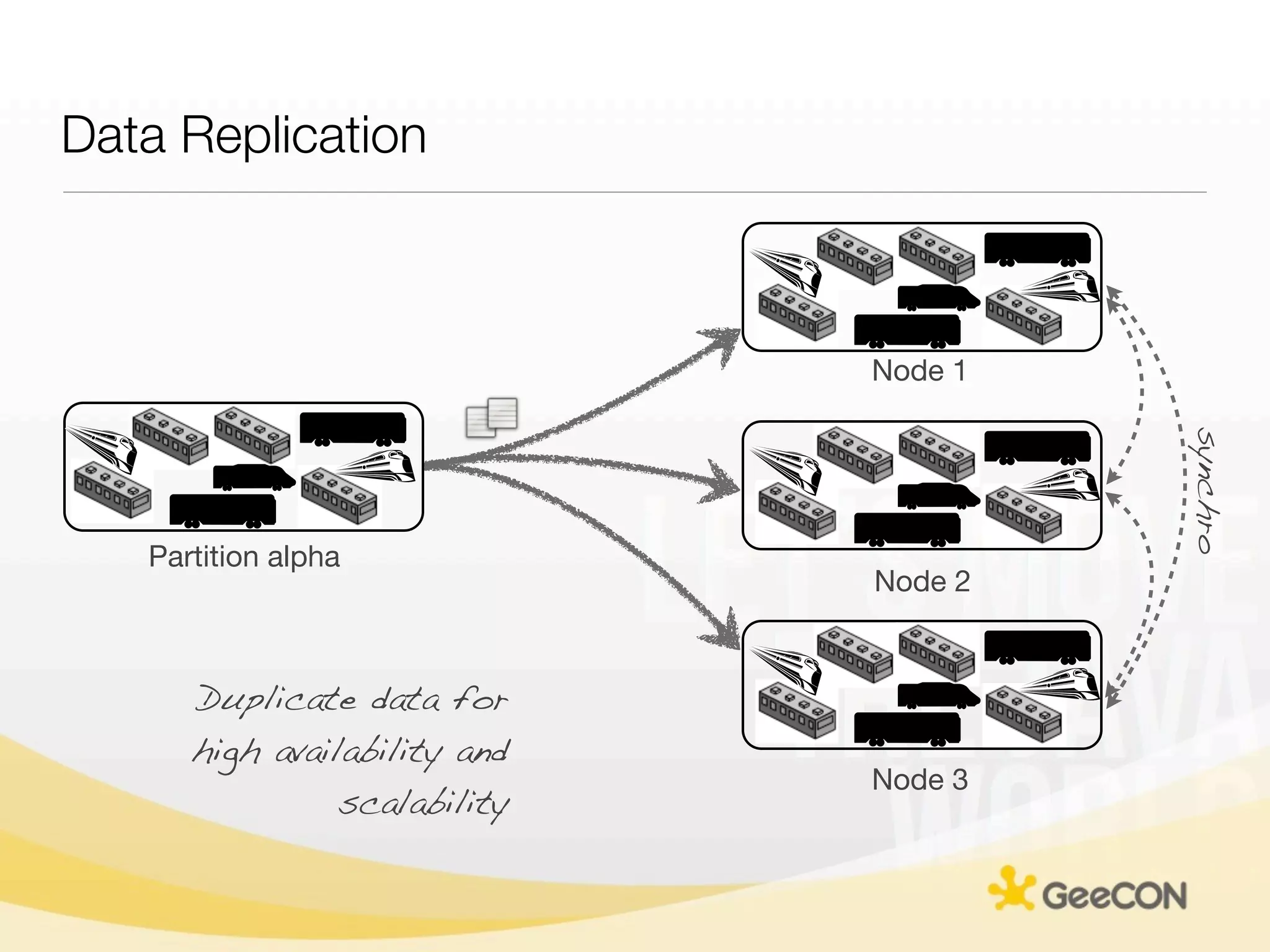
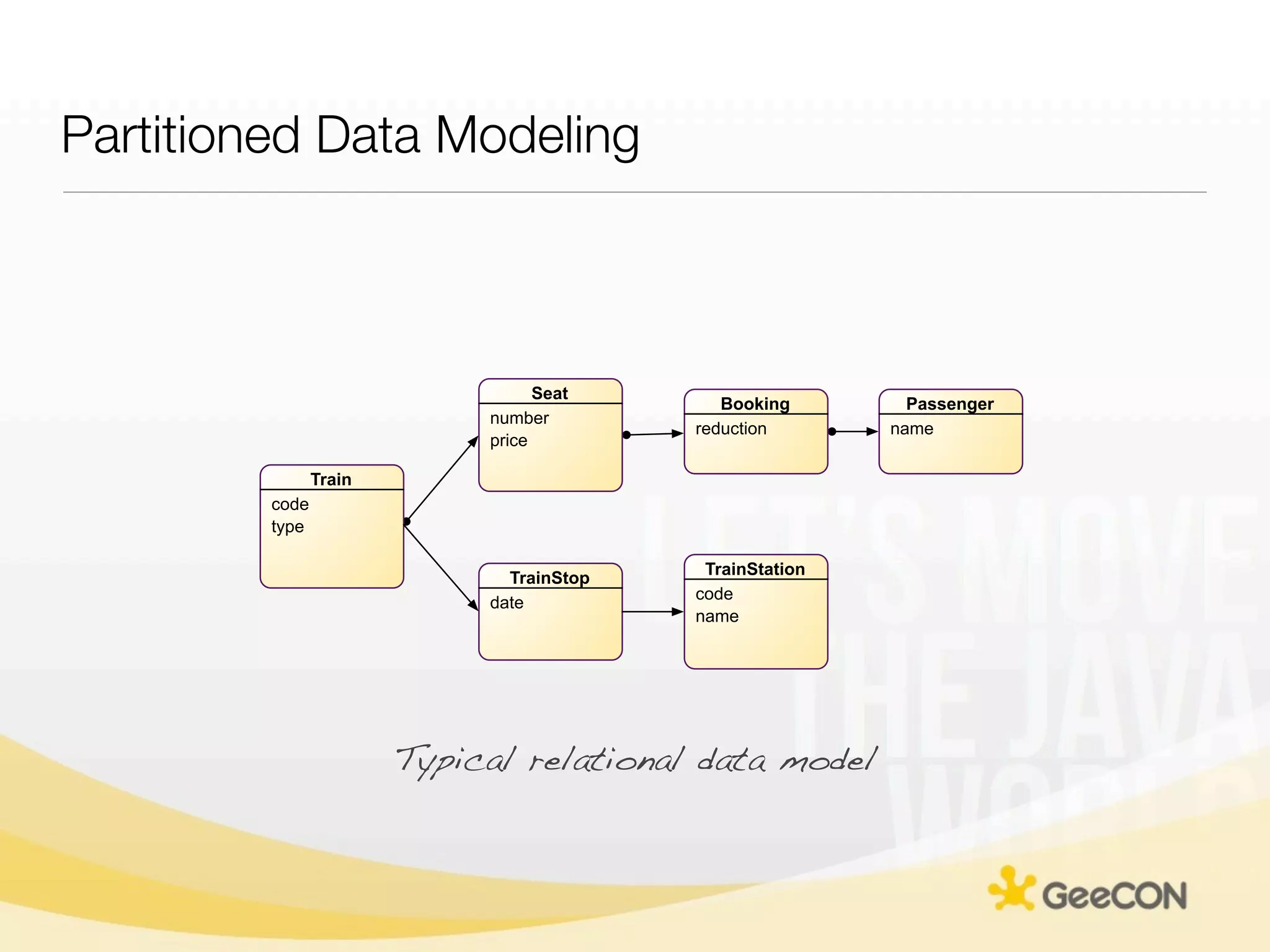
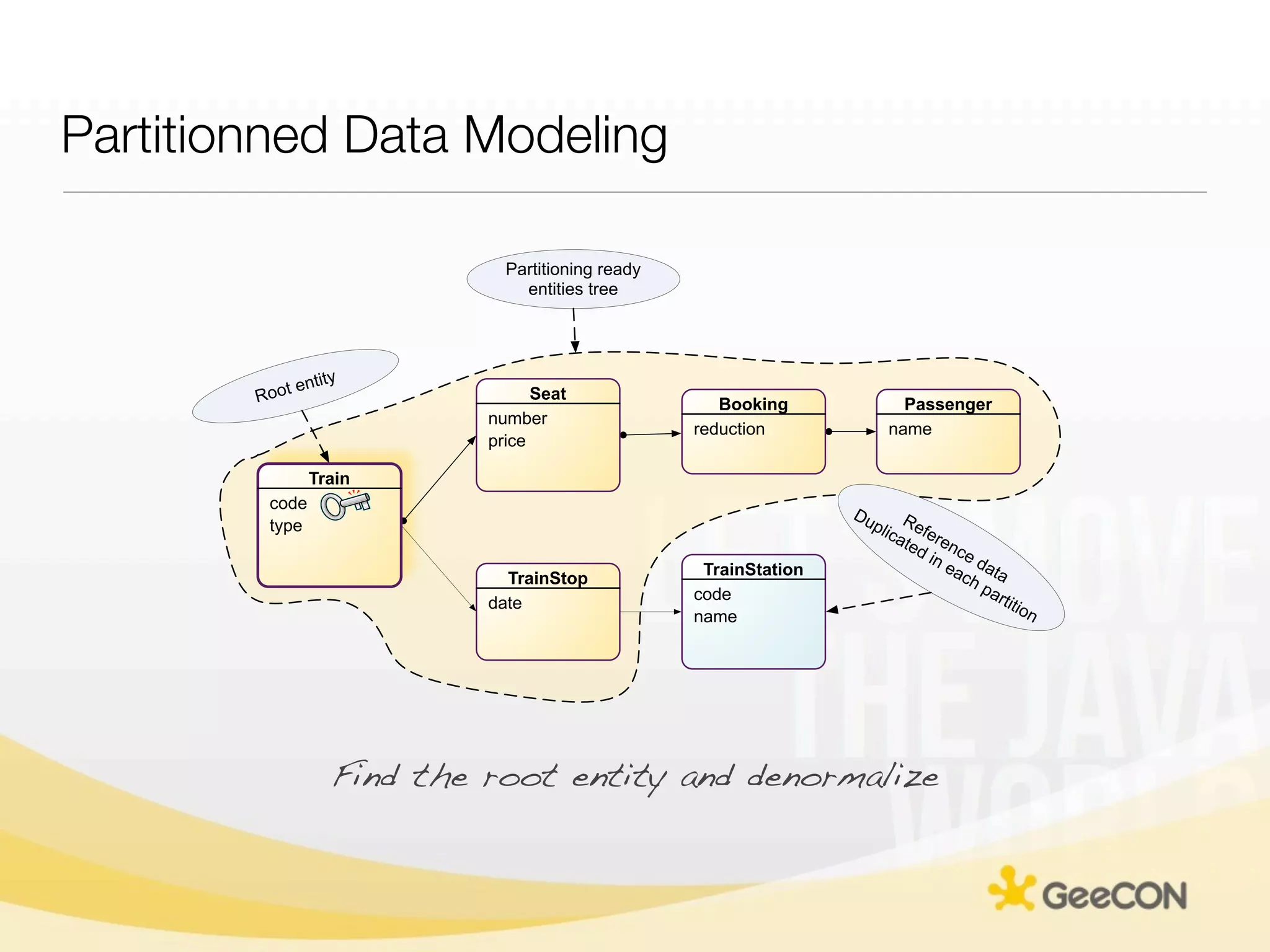
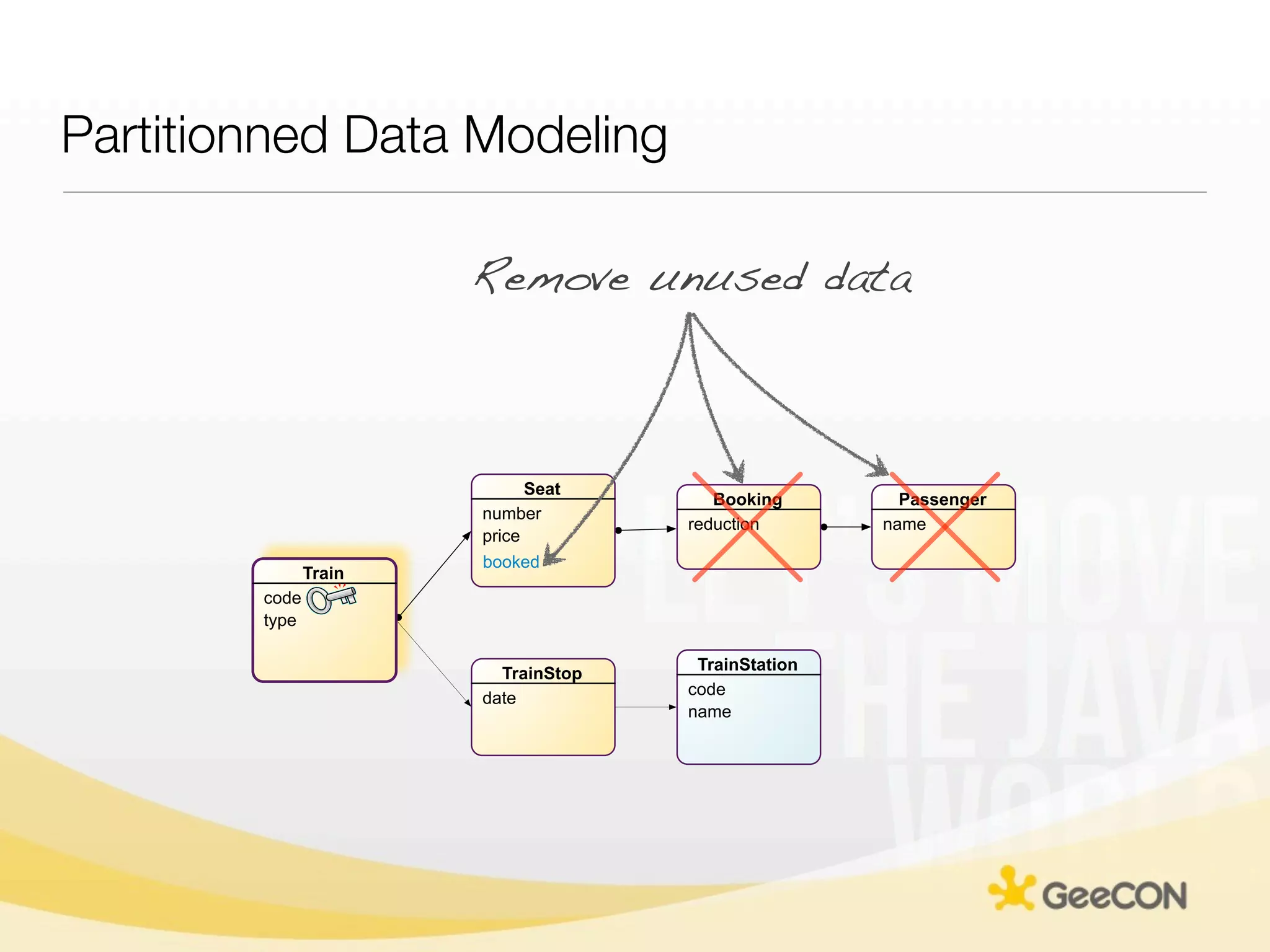
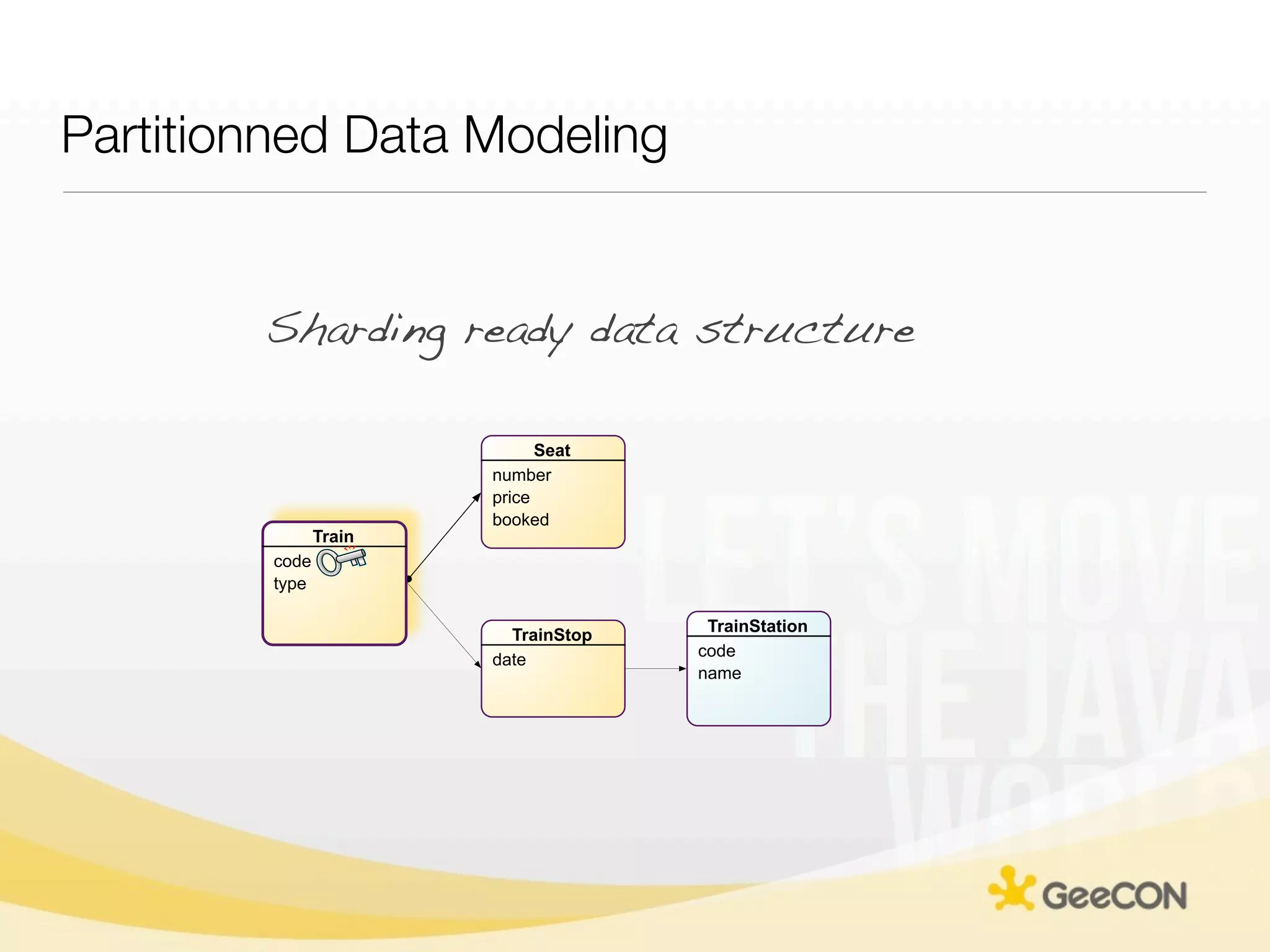
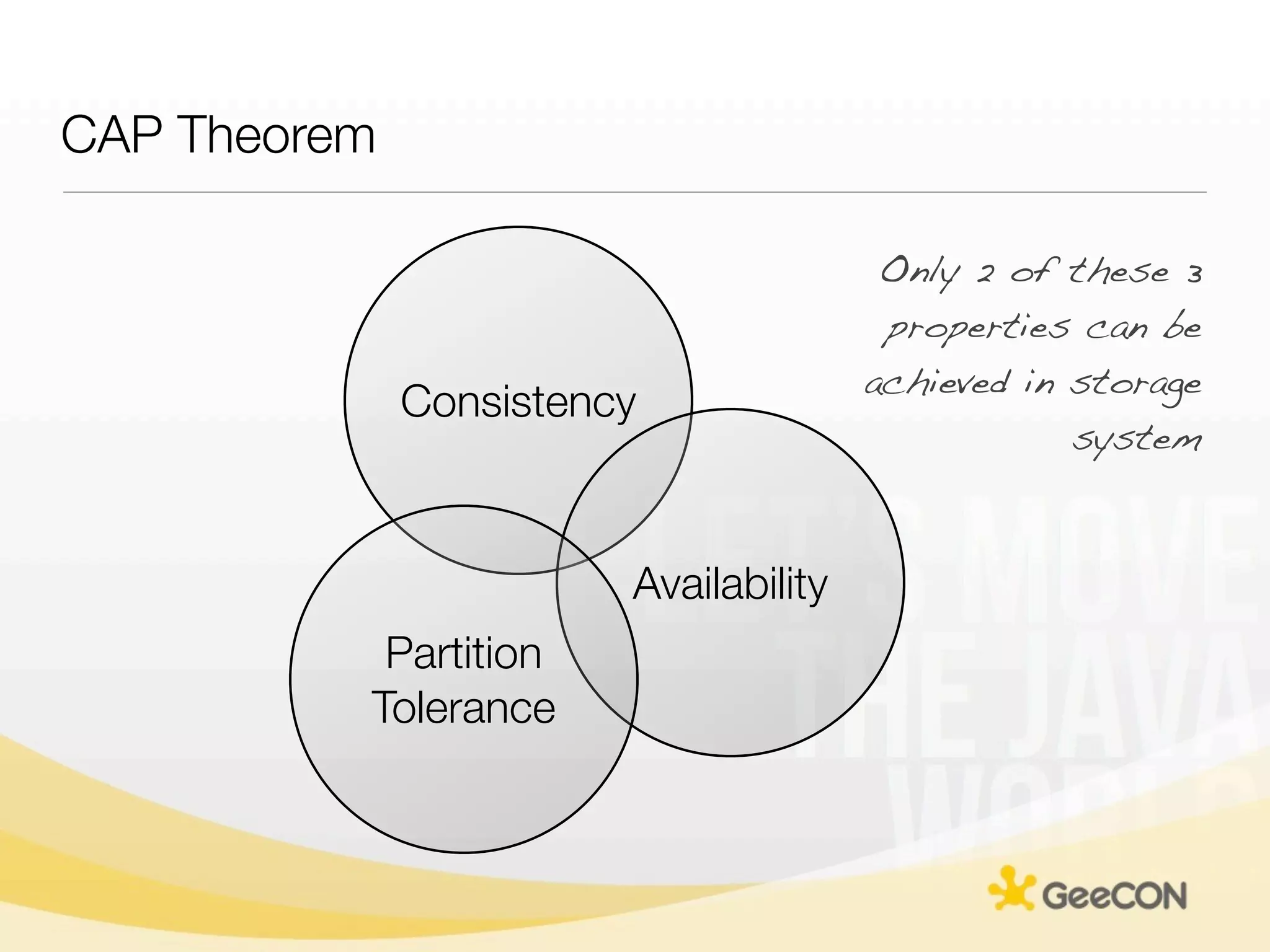
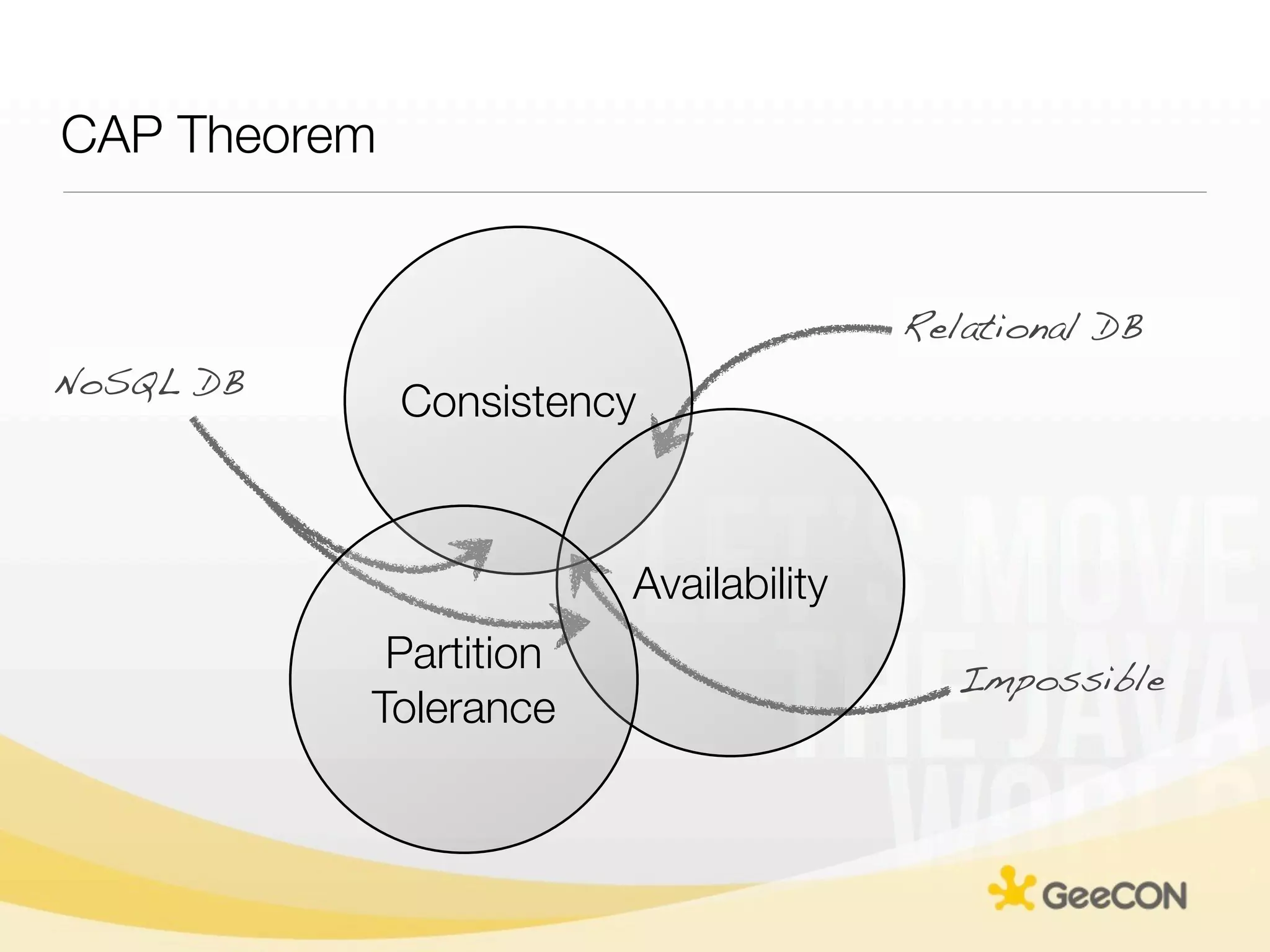
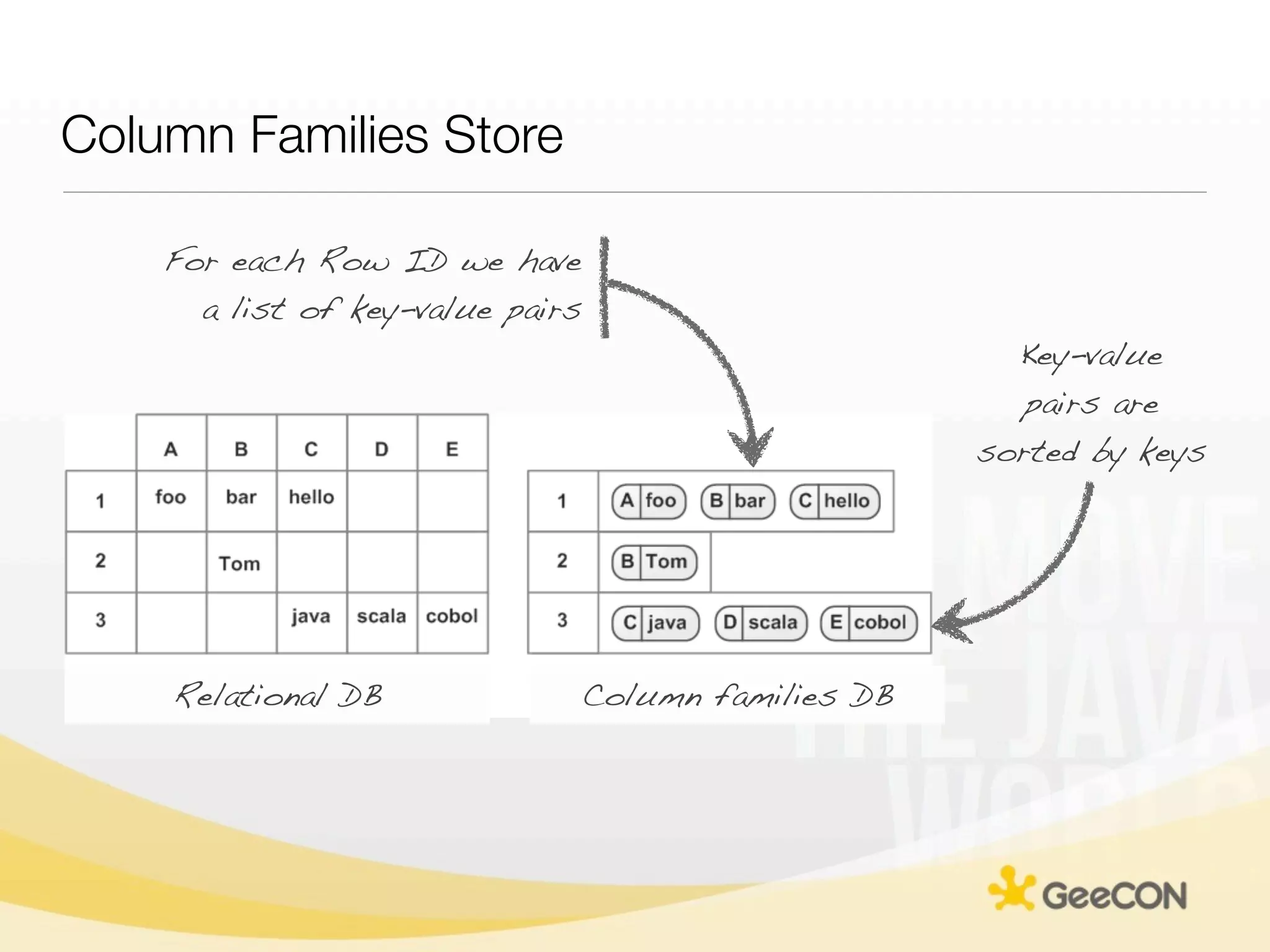
The document discusses NoSQL databases and data grids from a developer's perspective, highlighting their use in large-scale applications and varying data requirements. It covers the evolution and capabilities of different NoSQL solutions, such as key-value stores, document stores, and column-family databases, emphasizing their scalability, performance, and data modeling approaches. The content also touches on the trade-offs between consistency, availability, and partition tolerance, while presenting various real-world use cases like financial systems and e-commerce applications.






















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










