Download as PDF, PPTX



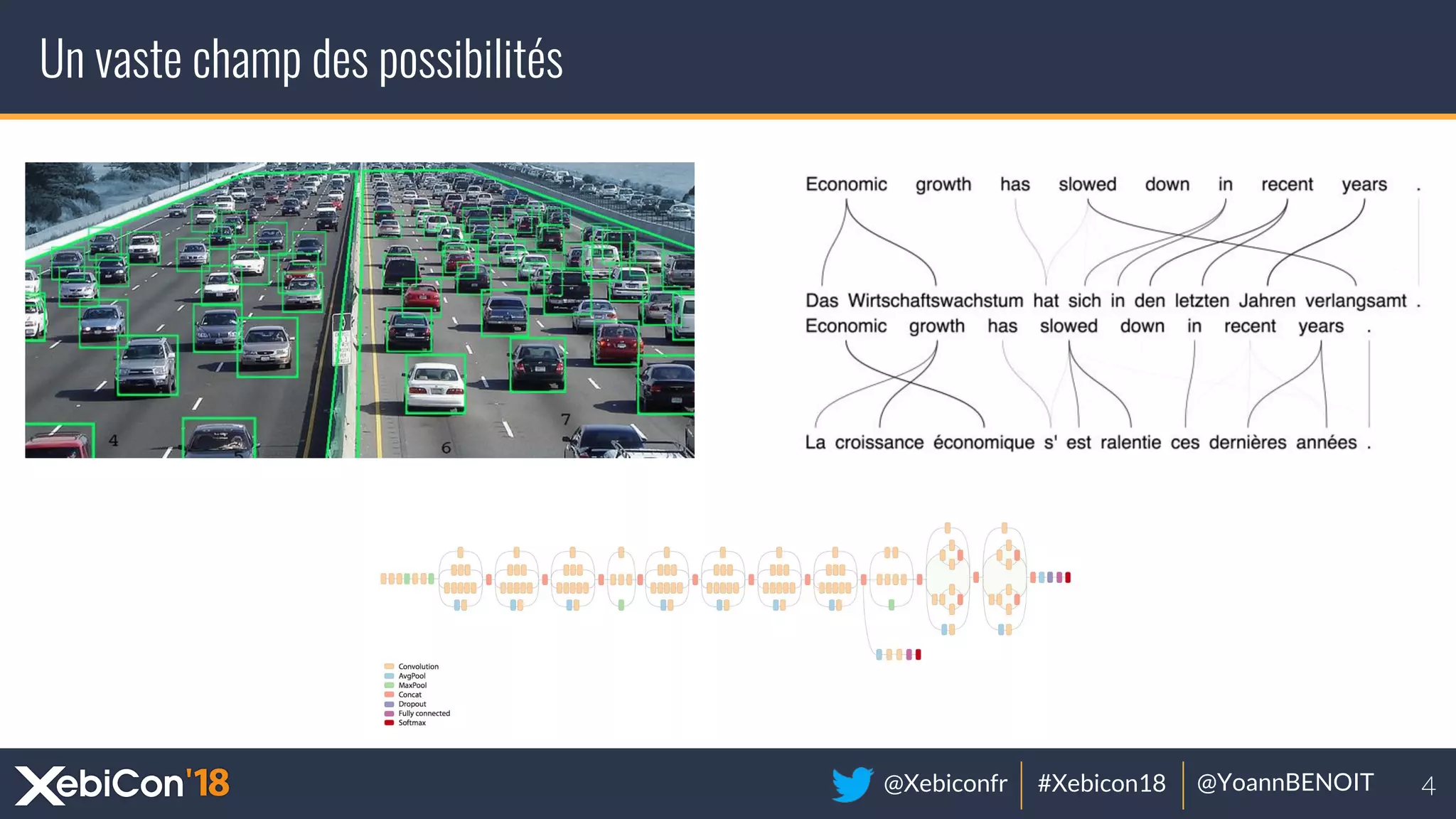
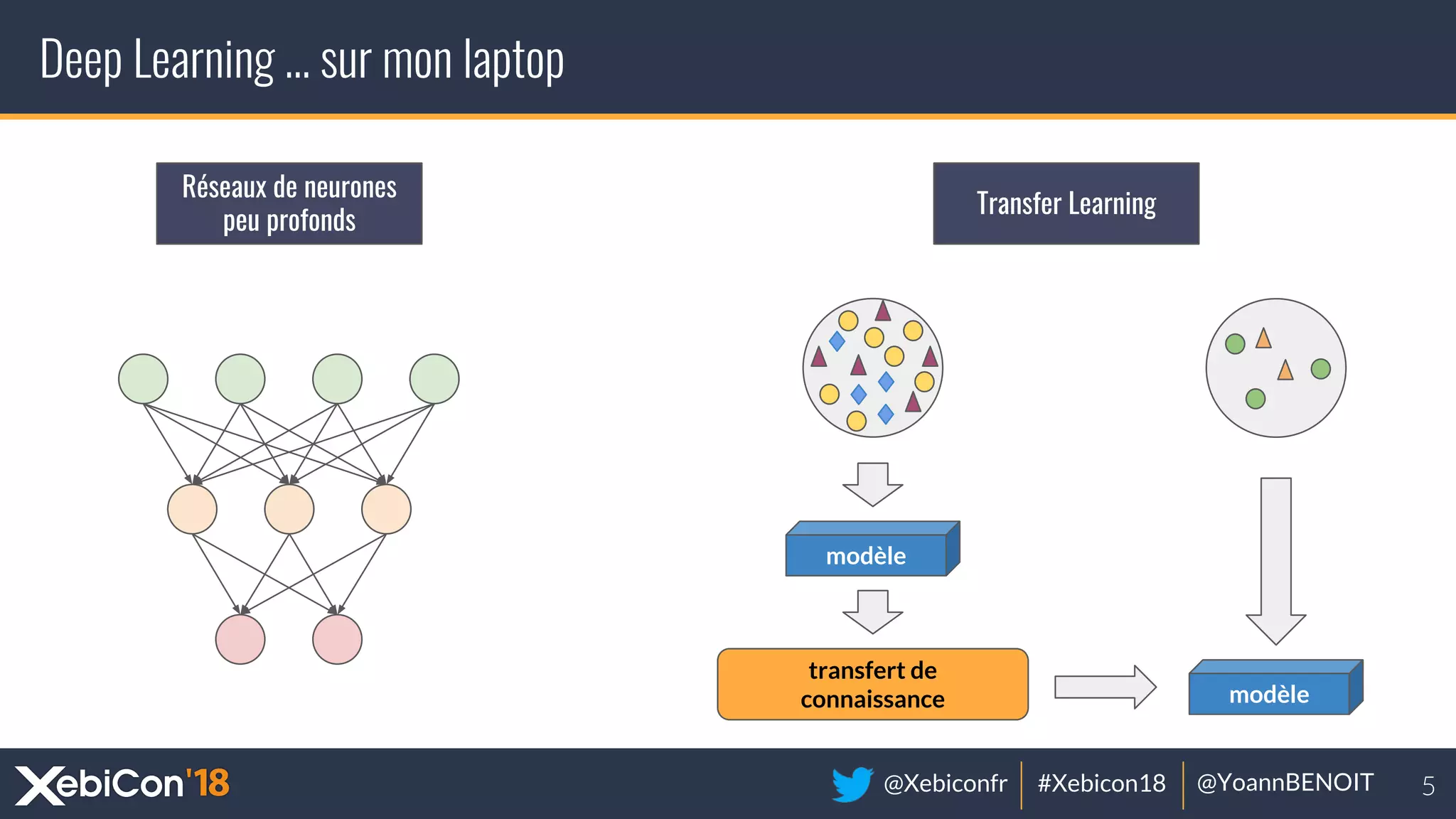






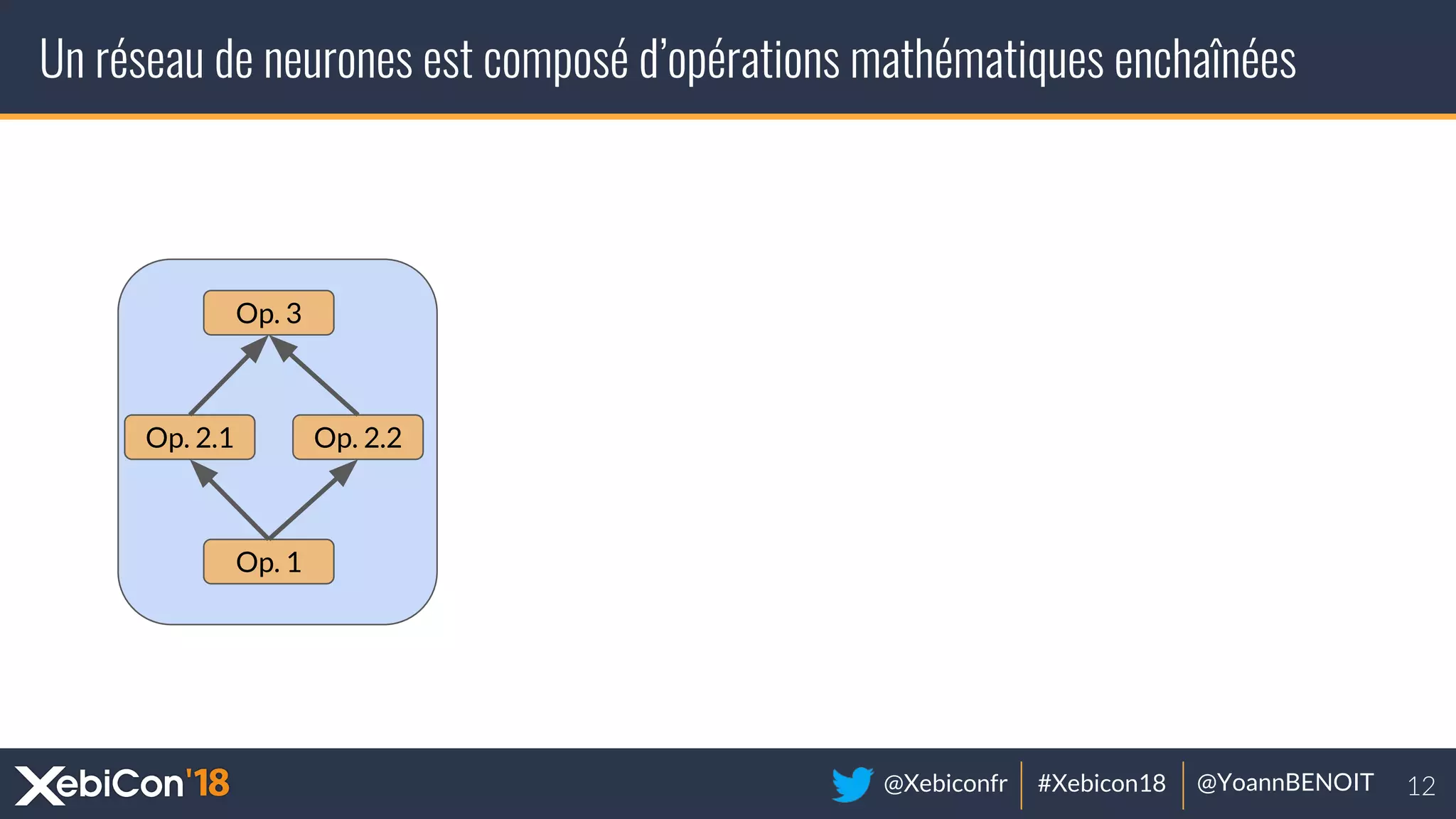
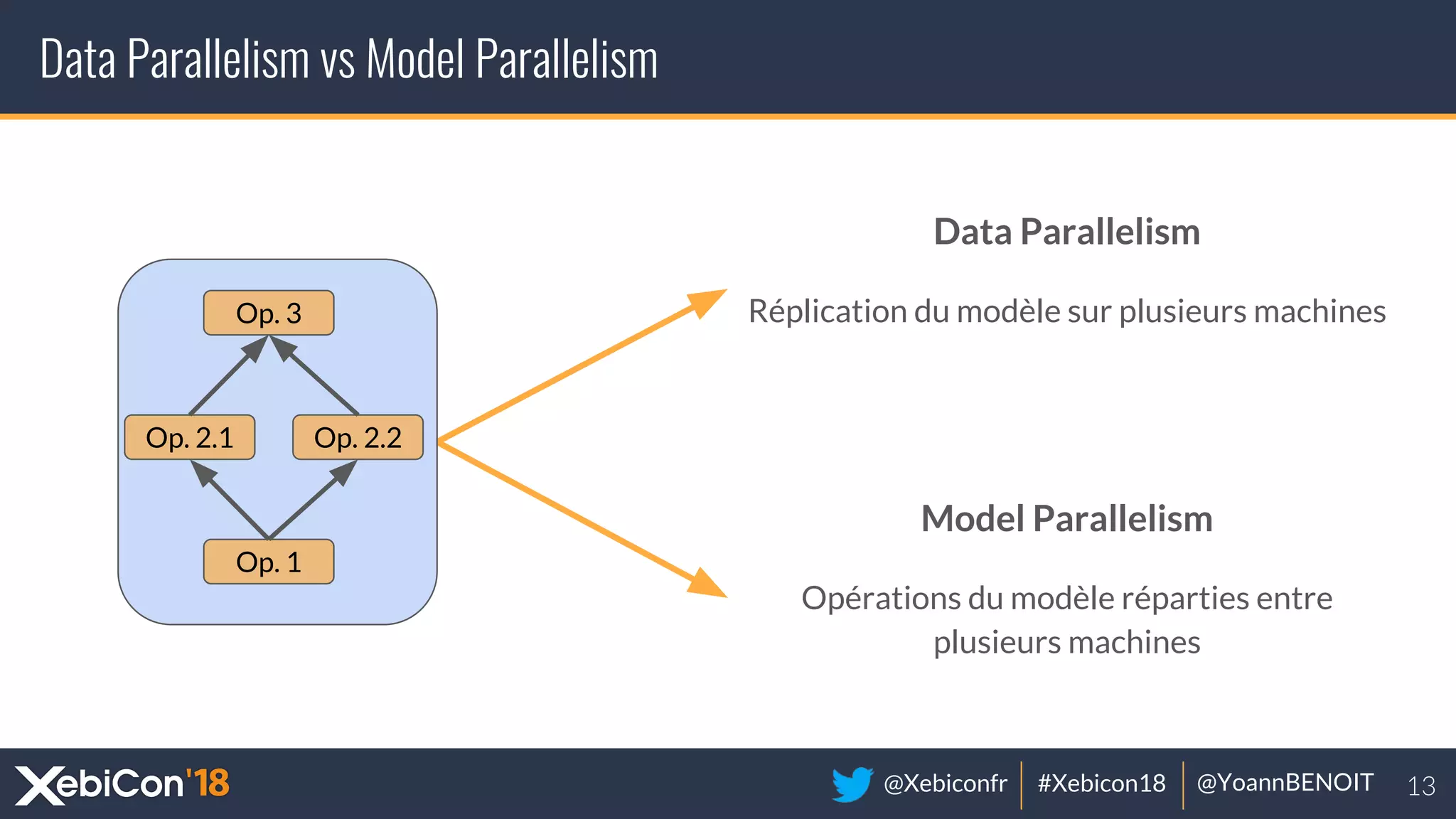

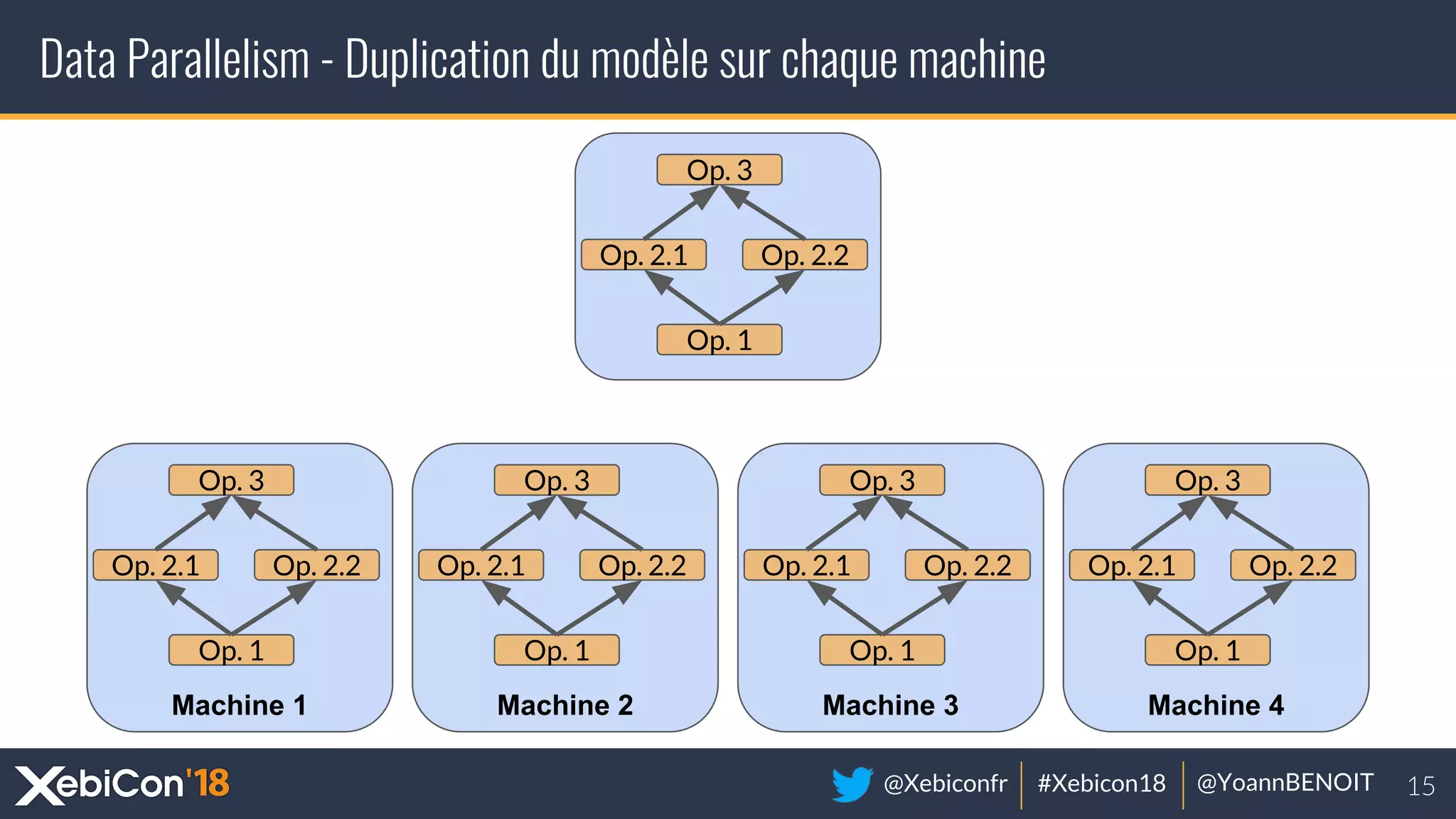
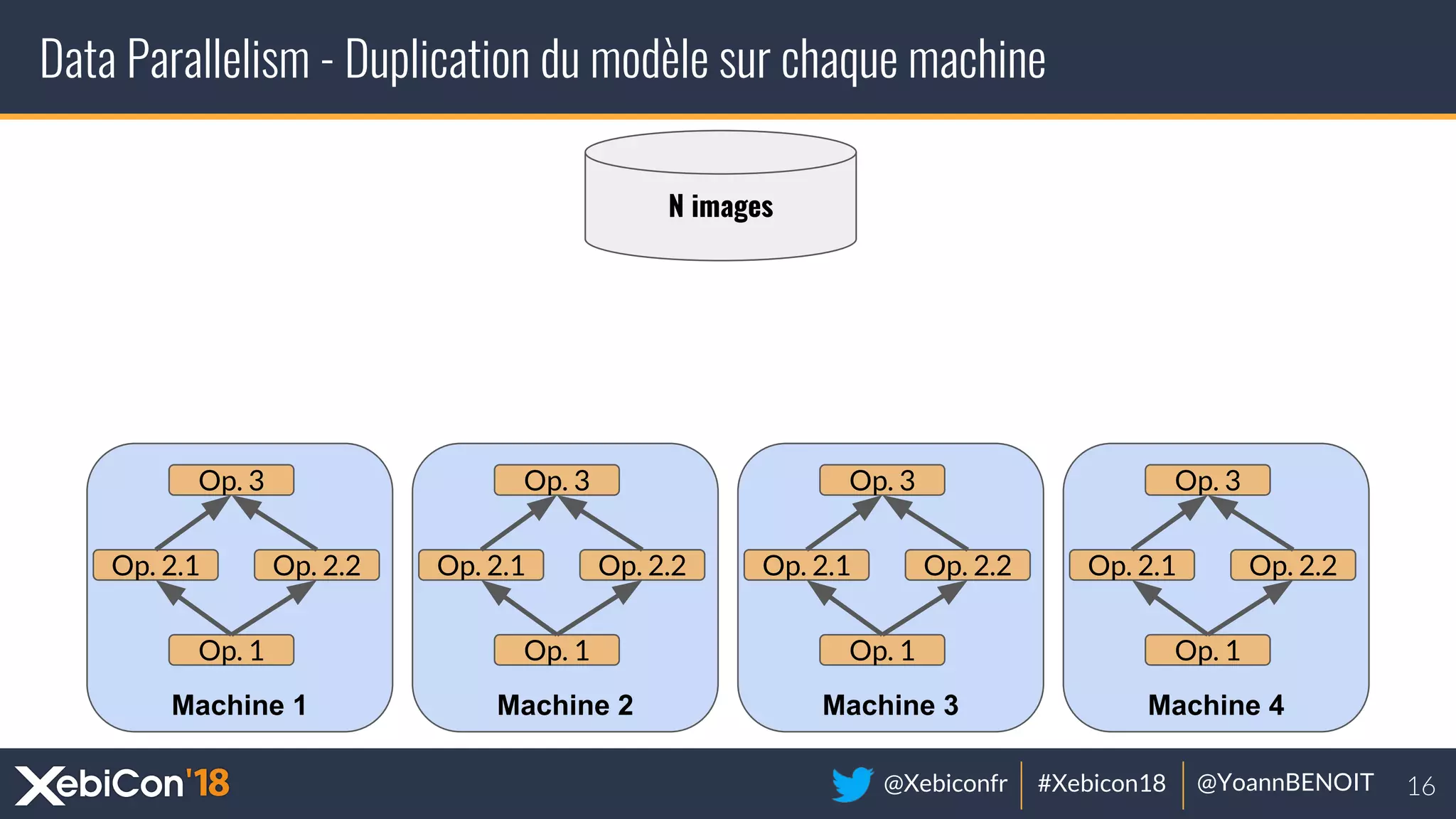
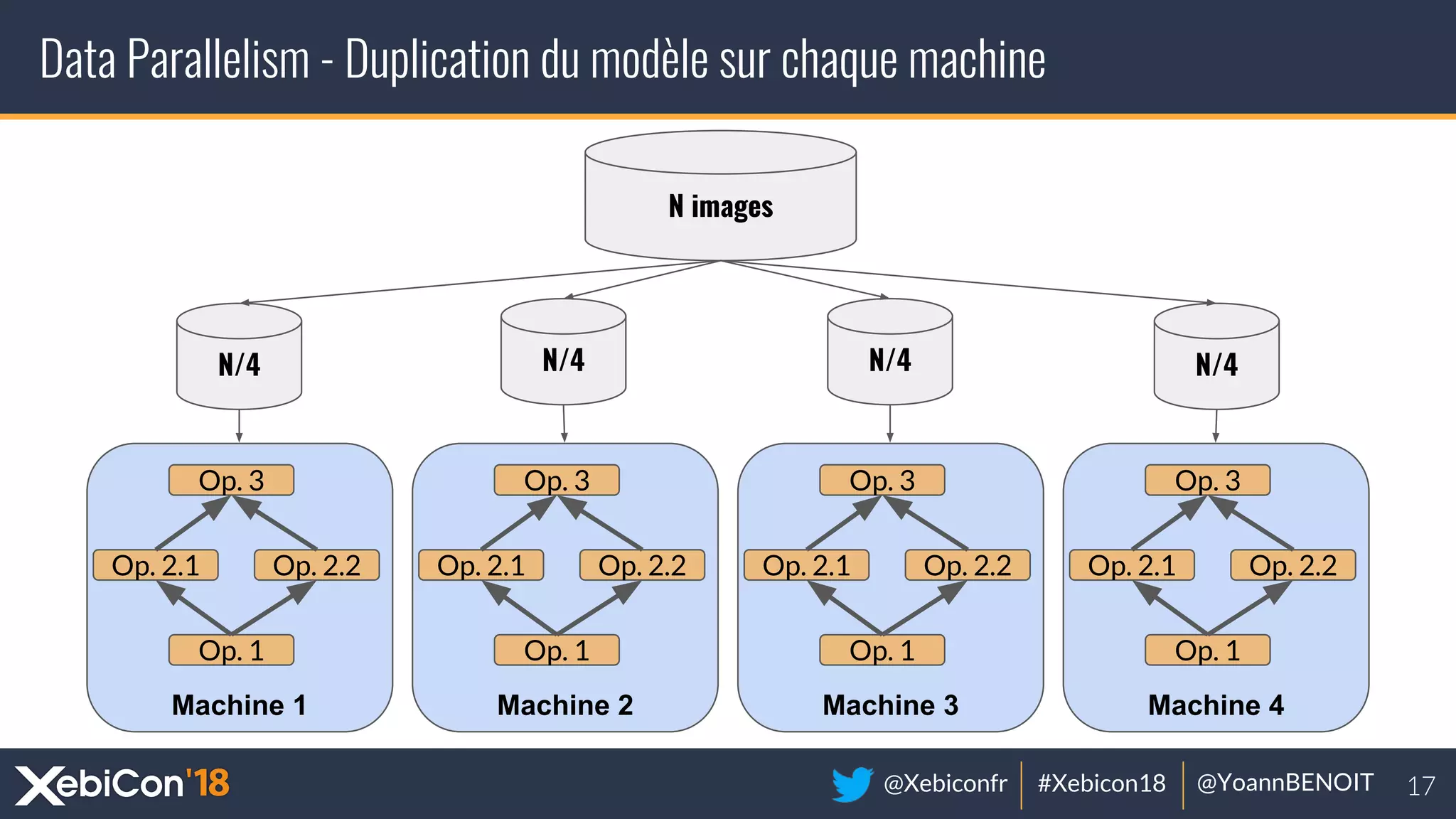


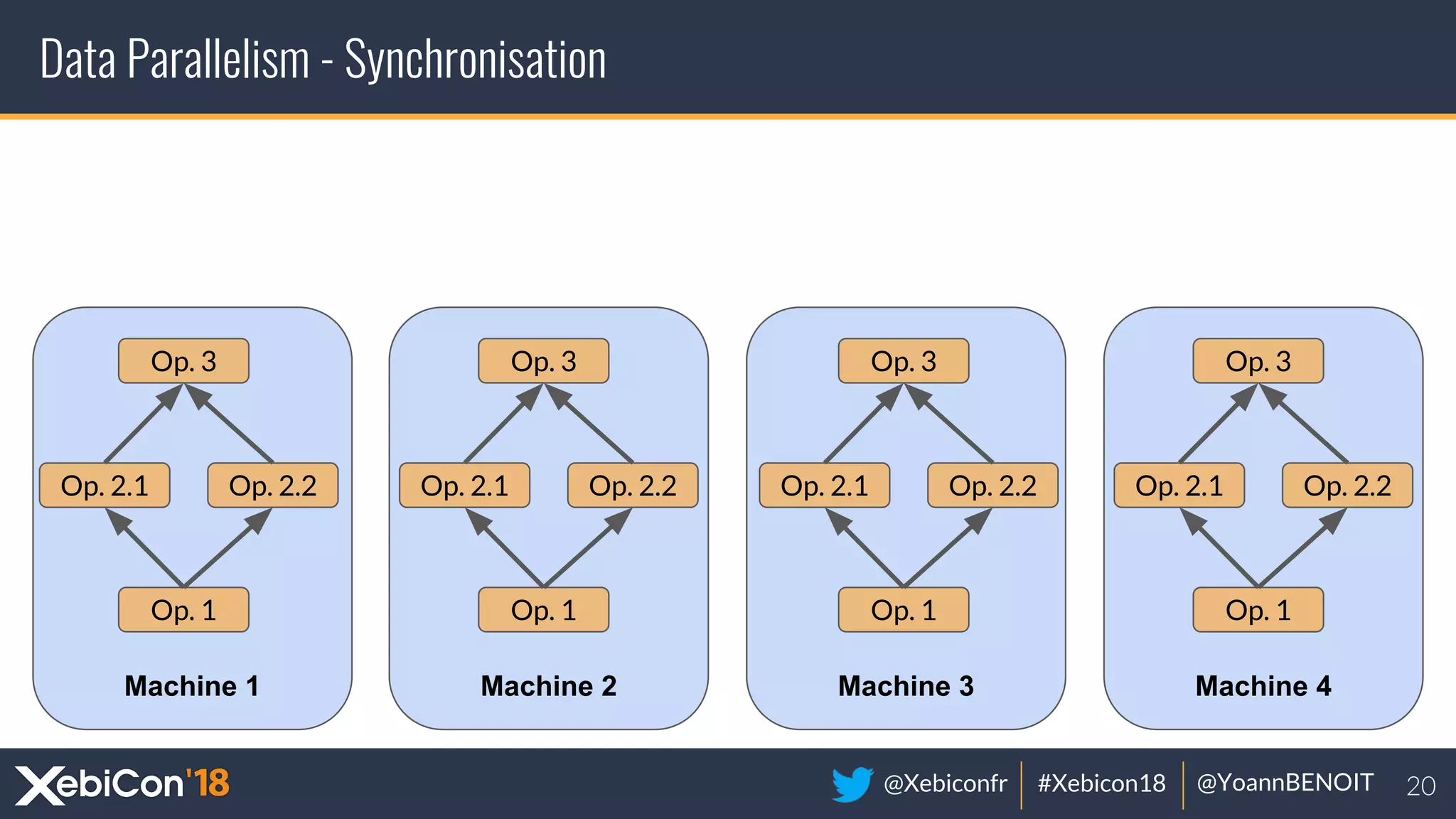
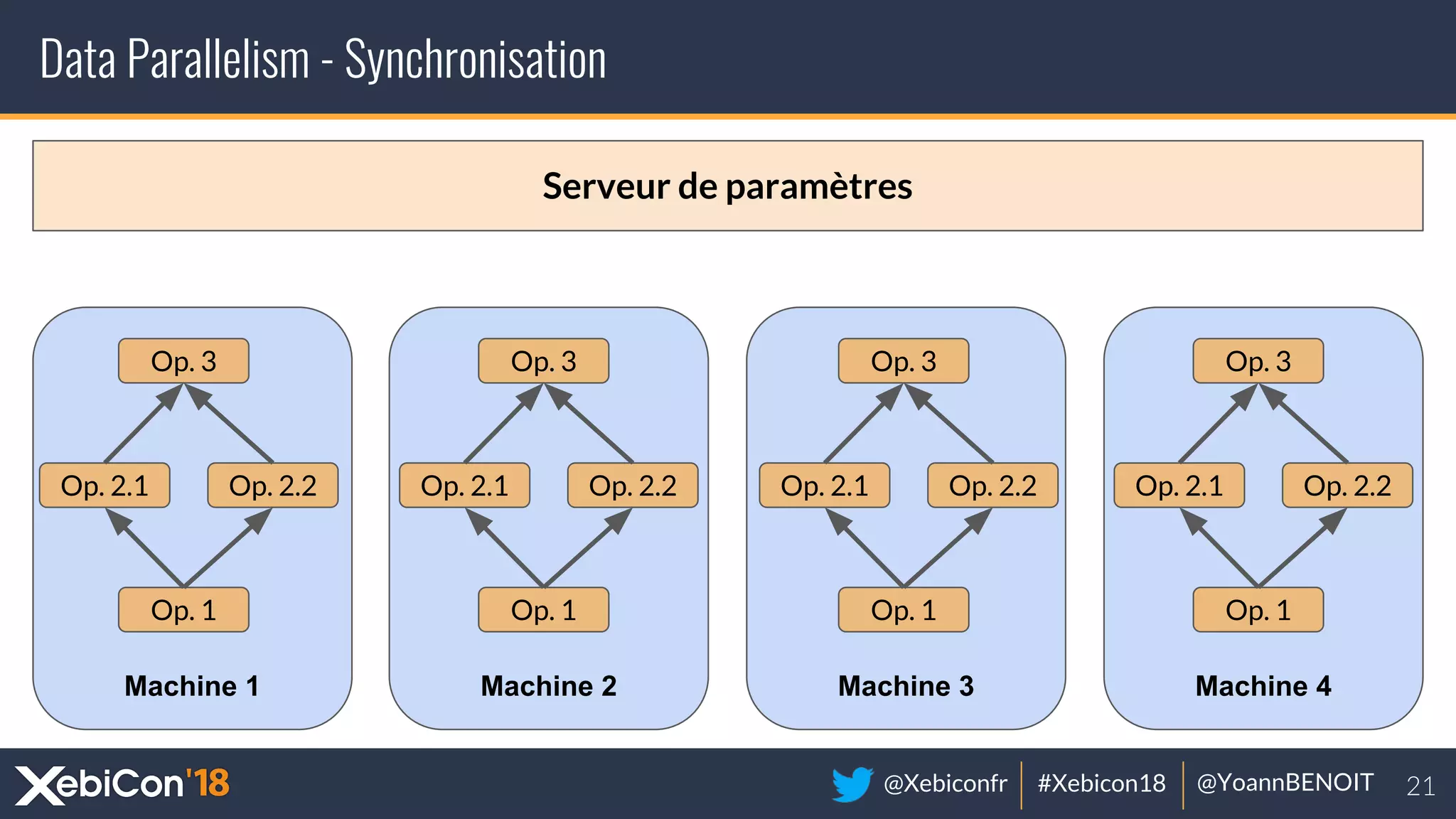
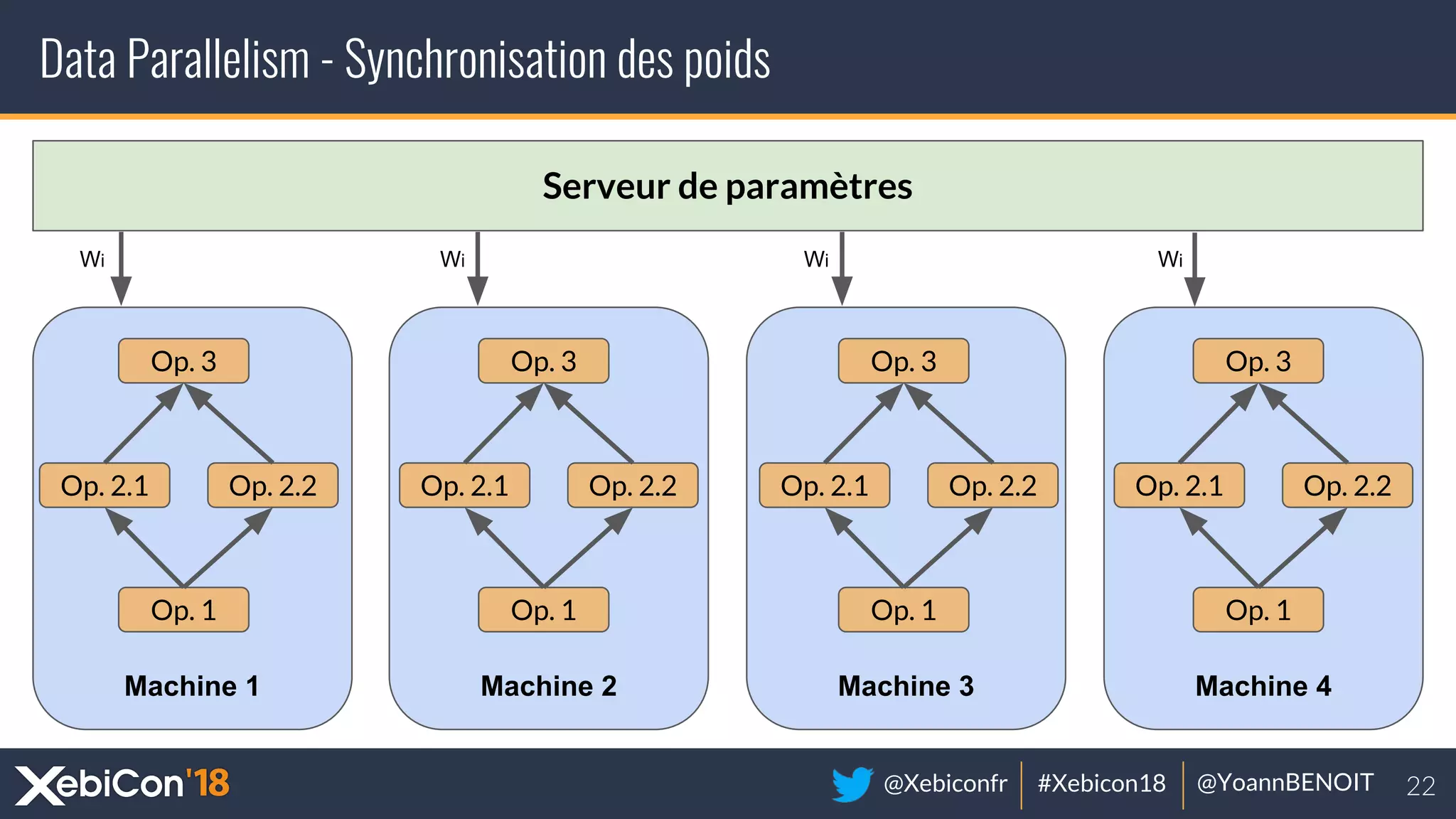
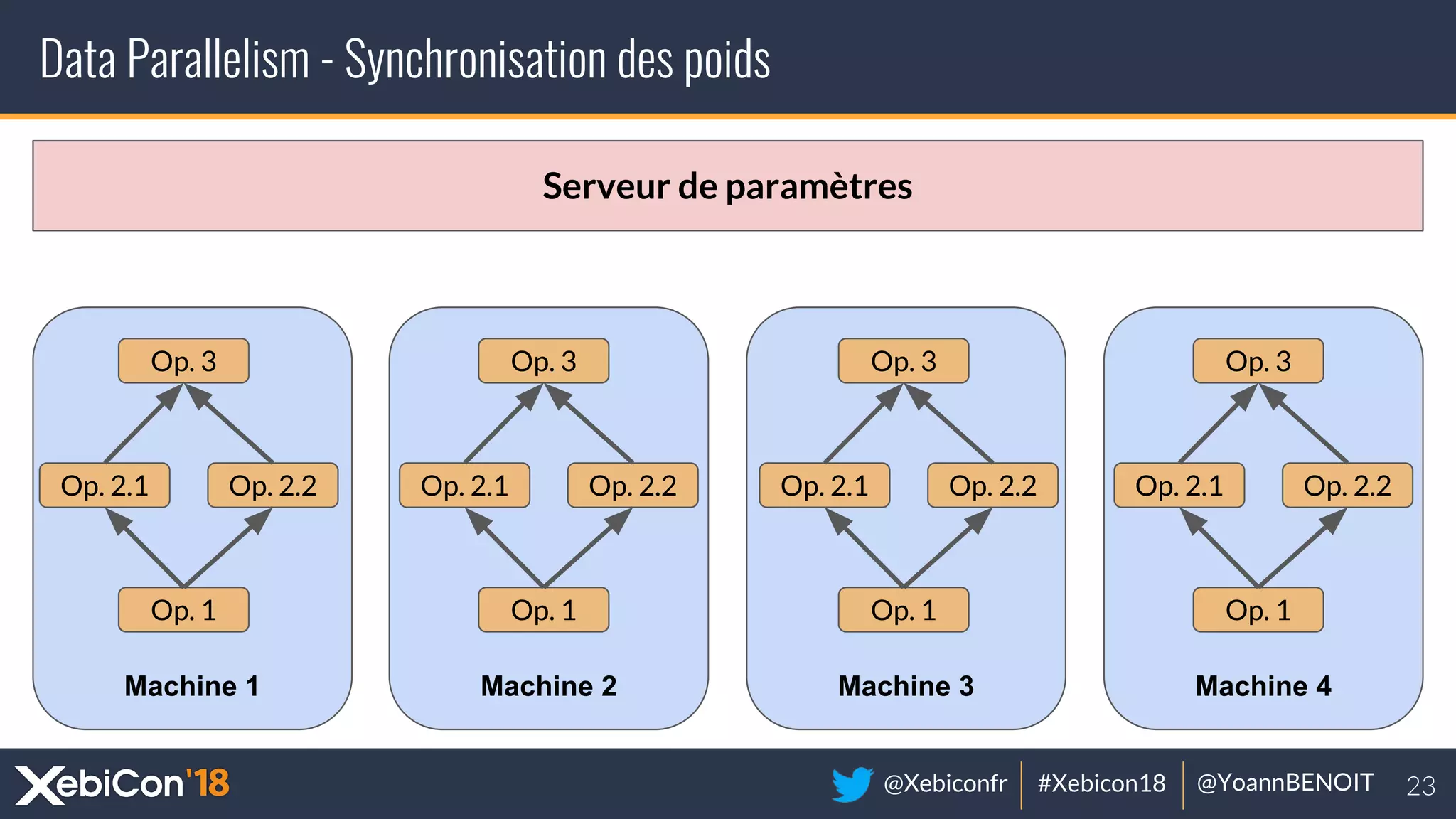
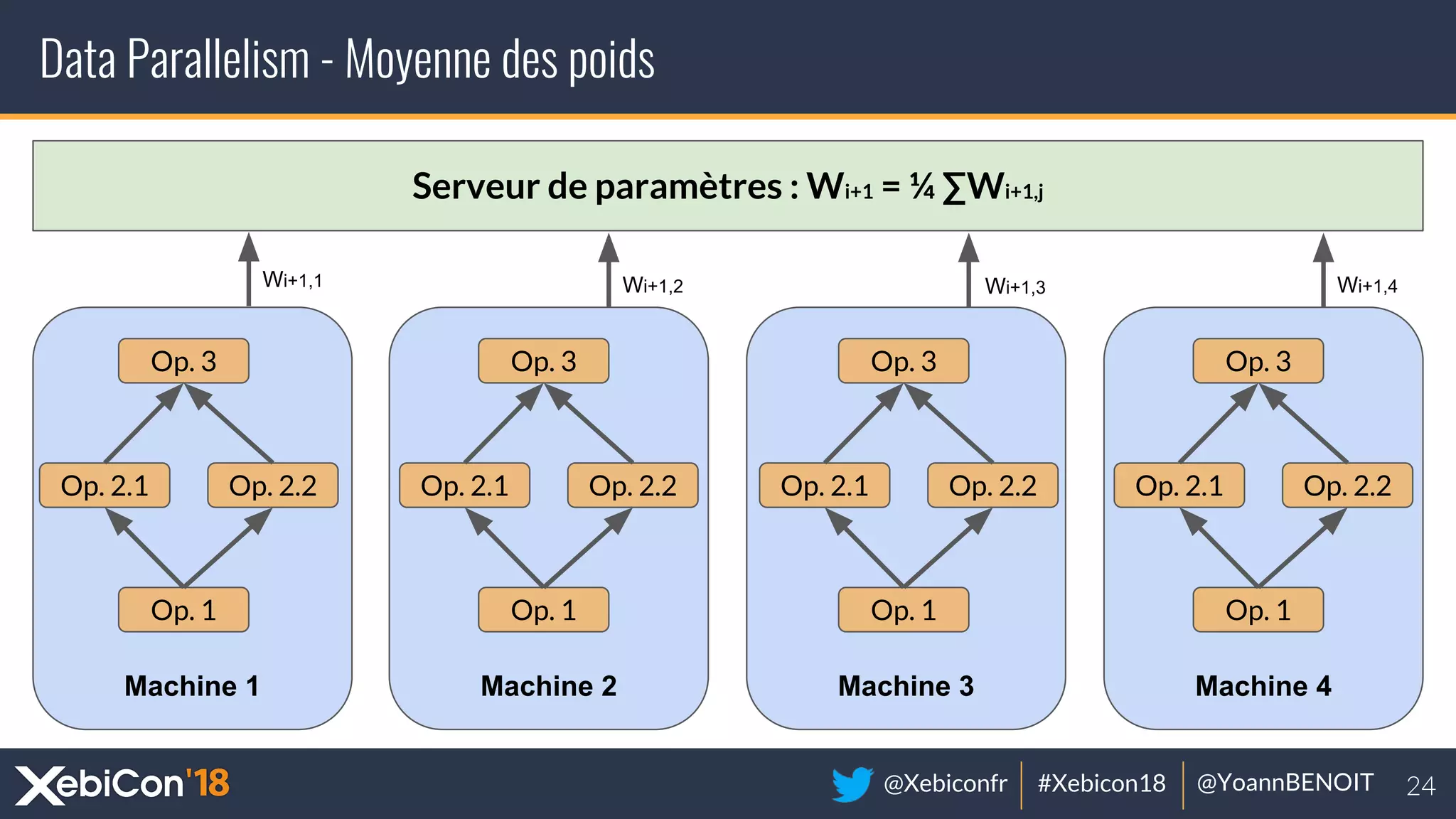
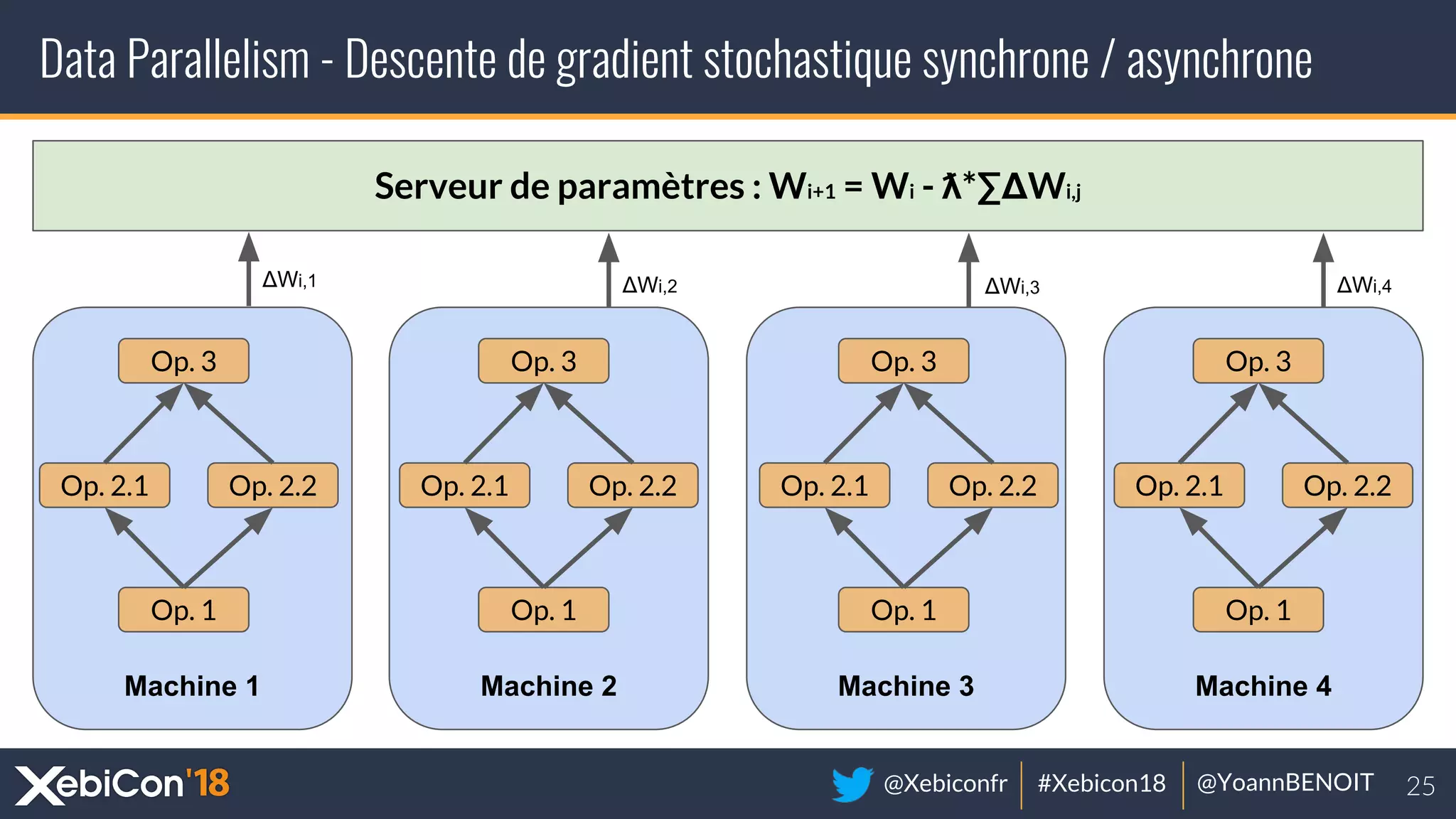


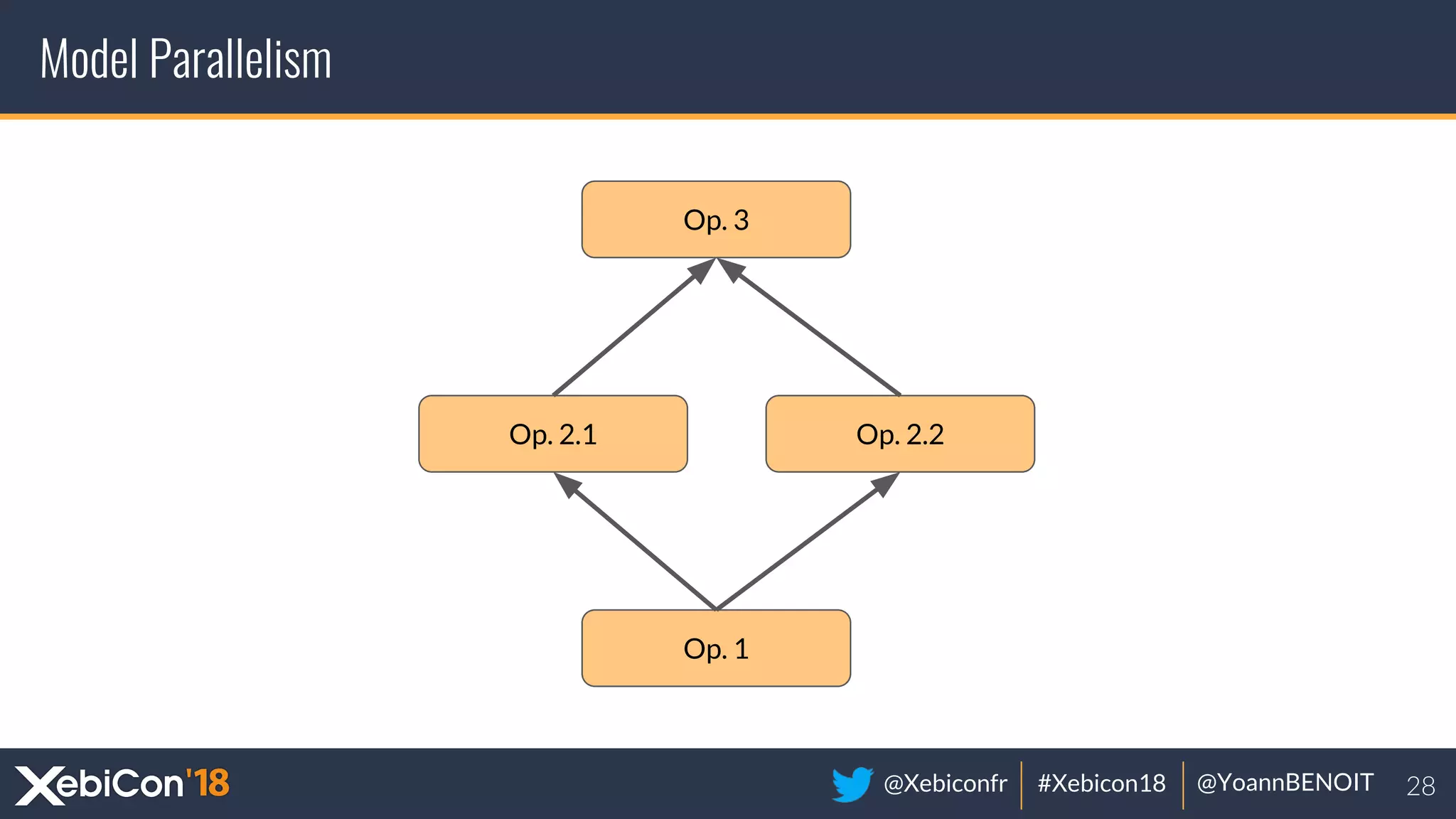
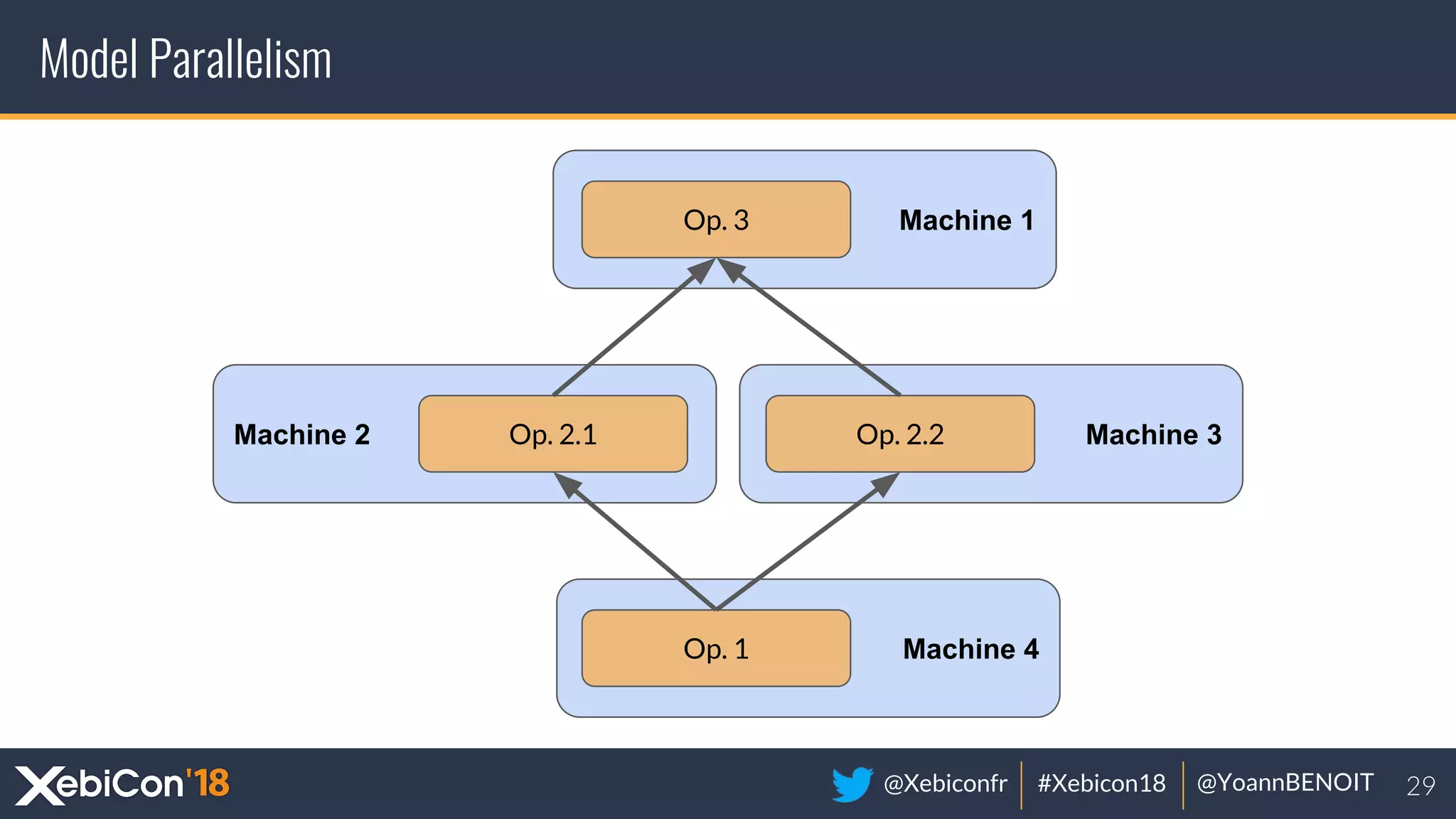



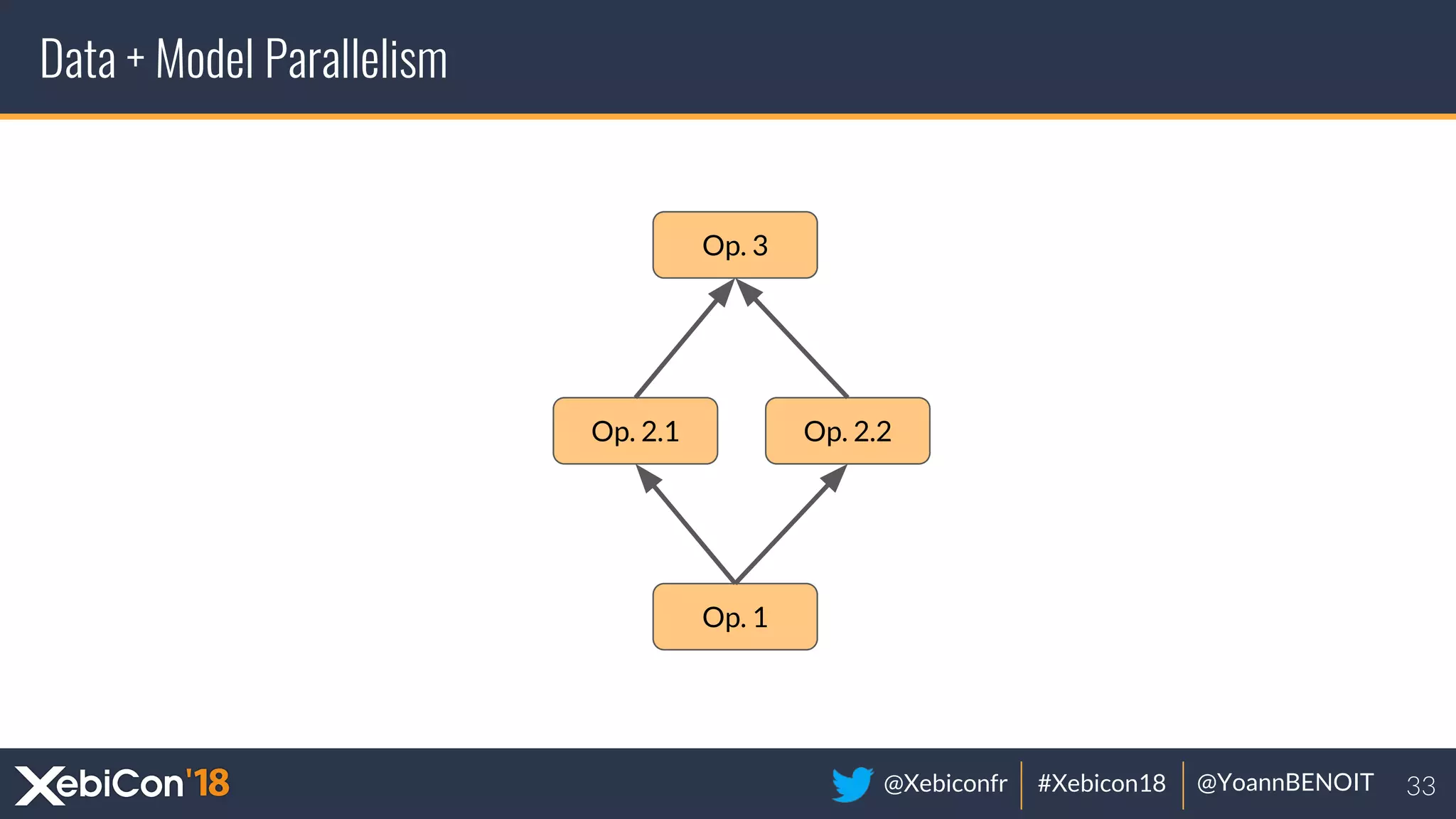
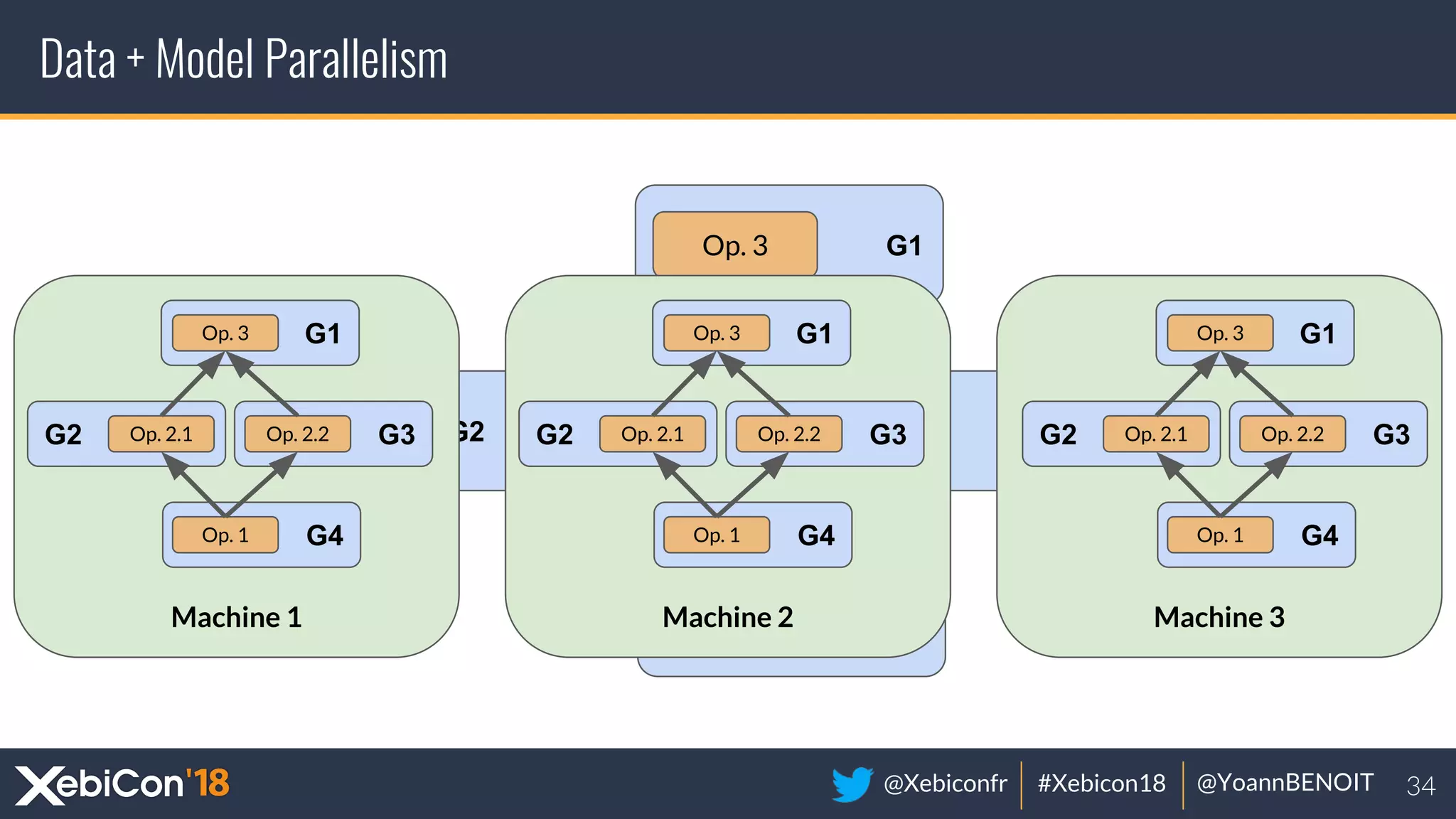









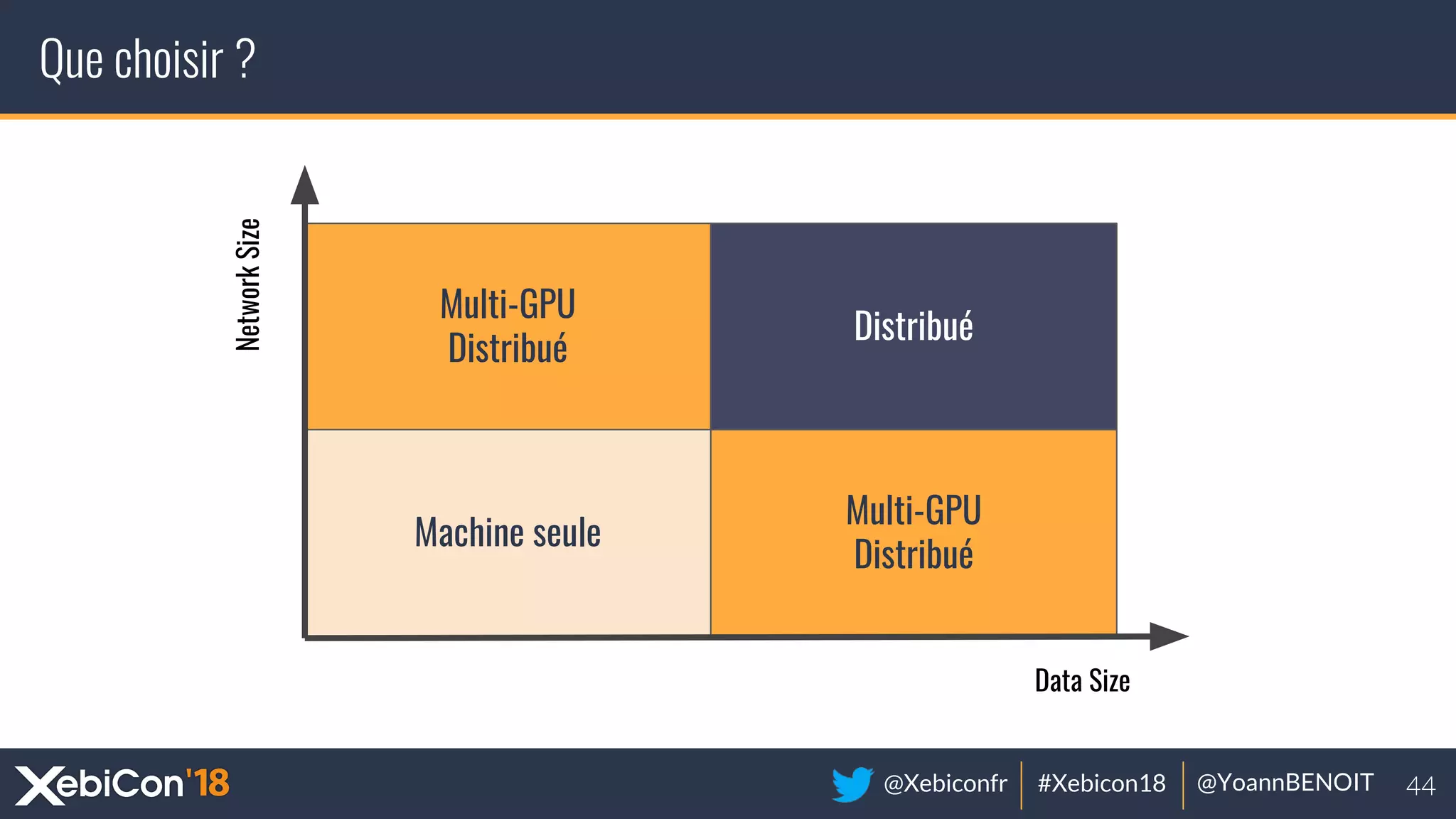




The document discusses distributed deep learning, focusing on techniques such as data parallelism and model parallelism, which allow for efficient training of neural networks across multiple machines. It addresses the constraints of using single machines, like limited computational power and memory issues, and proposes solutions through various frameworks compatible with big data environments like Hadoop. Additionally, it covers scenarios for when to use distributed methods and references resources for further exploration.
































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












