This document discusses content-based image retrieval (CBIR) using interactive genetic algorithms. It proposes using IGA to better capture a user's image preferences through iterative refinement of feature weights. Features discussed include color (mean and standard deviation in HSV color space), texture (entropy based on gray level co-occurrence matrix), and edges. IGA allows users to provide feedback on retrieval results to gradually shape the algorithm toward their interests over multiple generations. The document reviews related work using other features for CBIR and discusses color, texture, and edge features in more detail.
![ABSTRACT:
Research on content-based image retrieval (CBIR)has gained tremendous momentum during
the last decade.A technique which uses visual contents to search images from large scale image
databases according to users' interests, has been an active and fast advancing research area .A CBIR
system adaptable to user's interests through the use of an interactive genetic algorithm(IGA) is
presented in this concept. This idea employs IGA to discover a combination of descriptors that
better characterizes the user perception of image resemblance.The mean value and the standard
deviation of a color image are used as color features. We also considered the entropy based on the
gray level co-occurrence matrix and the edge histogram descriptor as the texture features.
Moreover, a wavelet-based descriptor which is used to extract texture features of an image is also
proposed. Further, in order to bridge the gap between the retrieving results and the users'
expectation, the IGA is employed such that users can adjust the weight for each image according to
their expectations.
INDEX TERM :Content-based image retrieval (CBIR), interactive genetic algorithm (GA) ,
low-level descriptors,Gray level co-occurrence matrix (GLCM).
I.INTRODUCTION
Image retrieval problem is actually the problem of searching for digital images in large databases.We often need to
efficiently store and retrieve image data to perform assigned tasks and to make a decision. By and large, research
activities in CBIR have progressed in four major directions: global image properties based, region-level features based,
relevance feedback, and semantic based. Initially, developed algorithms exploit the low-level features of the image such
as color, texture, and shape of an object to help retrieve images .A wide variety of CBIR algorithms has been proposed,
but most of them focus on the similarity computation phase to efficiently find a specific image or a group of images that
are similar to the given query.
igure 1: Content Based Approach
Content-based image retrieval (CBIR) is mainly used for following purpose:
Art collections
entertainment,
fashion design
education,
medicine,
Intellectual property
Architectural and engineering design
In order to achieve a better approximation of the user’s information need for the following search in the image
database, involving user’s interaction is necessary for a CBIR system. To propose a
user-oriented CBIR system that uses the interactive genetic algorithm (GA) (IGA) [5] to infer which images in the data-
bases would be of most interest to the user. Three visual features, color, texture, and edge, of an image are utilized in
our approach. IGA provides an interactive mechanism to better capture user’s intention.
Genetic Algorithm
A Genetic Algorithm (GA) is a method used to getquite accurate solutions to search problems through
application of the values of evolutionary biology. Genetic algorithms (GA) are not new to image retrieval systems [8]
[9]. A GA is an Artificial Intelligence technique which uses interactive methods to solve problems of searches that
satisfies certain requirements. GAs have been broadly valuable in many areas of engineering such as signal processing,
system identification, image retrieval and data mining problems .The GA consists of an iterative process that evolves a](https://image.slidesharecdn.com/ga-130403003544-phpapp02/85/Ga-1-320.jpg)
![working set of individuals called a populationtoward an objective function, or fitness function.GAs also have been
successfully applied in the research of CBIR [18][19][20]. Working of GA is shown in figure (1). There are the three
terms used in Genetic algorithm as follows:
• Crossover – exchange of genetic material (substrings) denoting rules, structural components, features of a
machine learning, search, or optimization problem. Each individual must then be evaluated to produce a fitness
function. Fitness functions refer to a quantifiable scalar-valued measure of the fitness of an individual. In the
case of business processes the fitness functions of each process will most likely be generated by evaluating the
time it would take to complete each
process. Faster processes would receive high fitness functions, and slower ones would receive lower functions.
• Selection – the application of the fitness criterion to choose which individuals from a population will go on to
reproduce. Once each individual has been evaluated, the individuals with the highest fitness functions will be
combined to produce a second generation. In general the second generation of individuals can be expected to
be „fitter‟ than the first, as it was derived only from individuals carrying high fitness functions.
• Replication – the propagation of individuals from one generation to the next.
Begin
i=0;
Initialize S(i);
Evaluate S(i);
While (not termination condition)
Do
Begin
i=i+1;
Select s(i) from S(i-1);
After (cross and mutation)
S(i);
Evaluate S (i);
end;
end;
Children
Reproduction Modification
Modified
Population
Evaluated
Deleted
Discard
Parents
Evaluation](https://image.slidesharecdn.com/ga-130403003544-phpapp02/85/Ga-2-320.jpg)
![ Interactive Genetic Algorithm:
Interactive Genetic Algorithm (IGA) is a branch of evolutionary computation. The basic difference between
IGA and GA is the creation of the fitness function, that is, the fitness is determined by the user‟s valuation and not by
the predefined mathematical function.A user can interactively determine which members of the population will produce
again, and IGA automatically generates the next generation of content based on the user‟s input. During repeated rounds
of content creation and fitness assignment, IGA enables unique content to grow that suits the user‟s choices. Based on
this reason, IGA can be used to solve problems that are difficult or impossible to devise a computational fitness
function, for example, evolving images, music, various artistic designs, and forms to fit a user ‟s visual choices. From
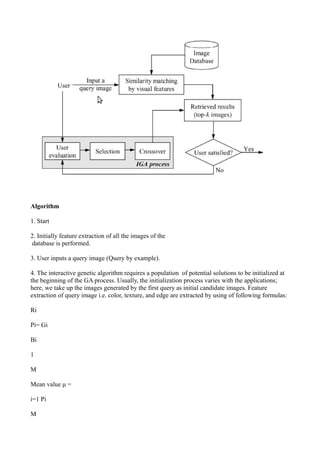
figure this is clear that firstly user puts a query image and then matching function is used which matches the query
image with the database image. Images are compared and then user evaluates the retrieved results if he is not satisfied
then this leads to the other evaluations and also iterative Genetic algorithm. This process continuous until the user is not
satisfied.
III.RELATED WORK
The author Yoo et al. [11] proposed a signature-based color-spatial image retrieval system. Color
and its spatial distribution within the image are used for the features. Liapis and Tziritas [17]
explored image retrieval mechanisms based on a combination of texture and color features. Texture
features are extracted using discrete wavelet frame analysis. Two- or one-dimensional histograms
of the CIE Lab chromaticity coordinates are used as color features. Kokare et al. [15] concentrated
on the problem of finding good texture features for CBIR. They designed 2-D rotated complex
wavelet filters to efficiently handle texture images and formulate a new texture-retrieval algorithm
using the proposed filters. Takagi et al. [4] evauated the performance of the IGA-based image
retrieval system that uses wavelet coefficients to represent physical features of images. Arevalillo-
Herráez et al. [21] introduced a new hybrid approach to relevance feedback CBIR. Their technique
combines an IGA with an extended nearest neighbor approach to reduce the existing gap between
the high-level semantic contents of images and the information provided by their low- leve
descriptors. Under the situation that the target is unknown, face image retrieval has particularity.
4.IMAGE FEATURES
i) The Color Feature
Each image in the database can be represented using three primaries of a color space. The most
common color space is RGB.Since RGB space does not correspond to the human way of perceiving
the colors and does not separate the luminance component from the chrominance ones, we used the
HSV color space in our approach. HSV is an intuitive color space in the sense that each component
contributes directly to visual perception, and it is common for image retrieval systems [11], [23].
Hue is used to distinguish colors, whereas saturation gives a measure of the percentage of white
light added to a pure color. Value refers to the perceived light intensity. The important advantages of
HSV color space are as follows: good compatibility with human intuition, separability of chromatic
and achromatic components, and possibility of preferring one component to other [24]. Two
features to represent the global properties of an image. The mean (μ) and the standard
deviation (σ) of a color image are defined as follows:
1](https://image.slidesharecdn.com/ga-130403003544-phpapp02/85/Ga-3-320.jpg)
![μ=
N
σ=
Pi
(1)
i=1
1
N −1
1/2
N
(Pi − μ)2
(2)
where μ = [μH, μS, μV ]T and σ = [σH, σS, σV ]T , each component of μ and σ indicates the HSV
information, respectively,and Pi indicates the ith pixel of an image.
ii) The Texture Feature
Texture is an important image feature that has been used for characterization ofimages. If choose
appropriate texture descriptor, the performance of theCBIR must be improved. In this concept, the
entropy is used to capture textureinformation in an image and is defined as follows.
Entropy E = −
i
j
C i, j logC(i, j)....(4)
WhereC(i, j) is the gray level co-occurrence matrix. The C(i, j) is obtainedby first specifying a
displacement vector and then counting all pairs of pixelsseparated by the displacement and
having gray levels i and j. In other paper author proposed, a user-oriented mechanism for CBIR
method based on an interactive genetic algorithm (IGA). Color attributes like the mean value, the
standard deviation, and the image bitmap of a color image are used as the features for retrieval. In
addition, the entropy based on the gray level co-occurrence matrix and the edge histogram of an
image is also considered as the texture features. Furthermore, to reduce the gap between the](https://image.slidesharecdn.com/ga-130403003544-phpapp02/85/Ga-4-320.jpg)
![retrieval results and the users‟ expectation, the IGA is employed to help the users identify the
images that are most satisfied to the users‟ need.
iii)Edge Descriptor
Edges in images constitute an important feature to represent their content. Human eyes are
sensitive to edge features for image perception. An edge histogram in the image space represents
the frequency and the directionality of the brightness changes in the image. We adopt the edge
histogram descriptor (EHD) [27] to describe edge distribution with a histogram based on local edge
distribution in an image. The extraction process of EHD consists of the following stages.
1) An image is divided into 4 × 4 subimages.
2) Each subimage is further partitioned into nonoverlapping image blocks with a small size.
3) The edges in each image block are categorized into five types: vertical, horizontal, 45◦
diagonal, 135◦ diagonal, and nondirectional edges.
4) Thus, the histogram for each subimage represents the relative frequency of occurrence of the
five types of edges in the corresponding subimage.
5) After examining all image blocks in the subimage, the five-bin values are normalized by the
total number of blocks in the subimage. Finally, the normalized bin values are quantized for
the binary representation. These normalized and quantized bins constitute the EHD.
V. PROPOSED APPROACH
After studying many image retrieval algorithms,it is found that they all are suffering their own
advantages and disadvantages. So we concluded a new approach which is based on
user-oriented image retrieval system based on IGA, as shown in Fig. 1. Our system operates in four
phases.
1) Querying: The user provides a sample image as the query for the system.
2) Similarity computation: The system computes the similarity between the query image and
the database images according to the aforementioned low-level visual features.
3) Retrieval: The system retrieves and presents a sequence of images ranked in decreasing
order of similarity. As a result, the user is able to find relevant images by getting the top
ranked images first.
4) Incremental search: After obtaining some relevant images, the system provides an
interactive mechanism via IGA, which lets the user evaluates the retrieved images as more
or less relevant to the query one, and the system then updates the relevance information to
include as many user-desired images as possible in the next retrieval result. The search
process is repeated until the user is satisfied with the result or results cannot be further
improved.
When we apply the IGA to develop a content-based color image retrieval system, we
mustconsider the following components: 1) a genetic representation of solutions to the problem; 2)
one way to create the initial population of solutions; 3) an evaluation function that rates all
candidate solutions according to their “fitness”; and 4) genetic operators that alter genetic
composition of children during reproduction.](https://image.slidesharecdn.com/ga-130403003544-phpapp02/85/Ga-5-320.jpg)
![1
Standard deviation σ=
M−1
Entropy E = −
− μ)2
1/2
C i, j logC(i, j)
i
5.
M
i=1(Pi
j
Where μ, σ are used for color and entropy is used for texture information. And Edge Histogram
Descriptor (EHD) is used for extracting edge information. Extracted features are compared with the
stored feature of the images in the database i.e. similarity matching function is applied here.The
fitness function is working to calculate the quality of the chromosomes in the population. The use of
IGA allows the combination of human and computer efforts for problem solving [27]. In
ourapproach, the quality of a chromosome C with relation to the query q is defined as
F(q,C) = w1 sim(q,C) + w2 ・δ
wheresim(q,C) represents the similarity measure between images, δ indicates the impact factor of
Practicability of System Demonstration human‟s decision, the coefficients w1 and w2 determine
the relative importance of them to calculate the fitness. Initially value of δ is set to zero and value of
implicitfeed is zero if the search for the same query image is not performed before else Information
through the log files are matched at the same time and relevant images are extracted.
6. Result is displayed.
7. If user satisfied then searching get finished
8. Else if user does not satisfied then explicit feedback with interactive genetic algorithm works
here and similarity function is again calculated by adjusting the value of impact factor of human
judgment δ.
9 User repeats this step until and unless he is not satisfied.
10 End
At first, we give an example to illustrate the practicability](https://image.slidesharecdn.com/ga-130403003544-phpapp02/85/Ga-7-320.jpg)


































































