Downloaded 34 times




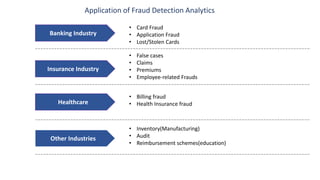
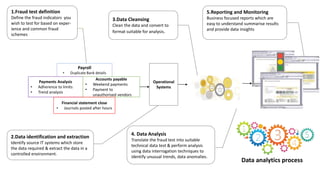




The document discusses the integration of analytic technology and human interaction in fraud detection analytics to identify improper transactions such as fraud or bribery. It outlines the steps involved in fraud detection, from defining fraud indicators to data analysis and reporting, emphasizing the need for data quality, security, and appropriate skill sets. Various industries, including banking, insurance, and healthcare, are highlighted for the application of these analytics techniques.









































































