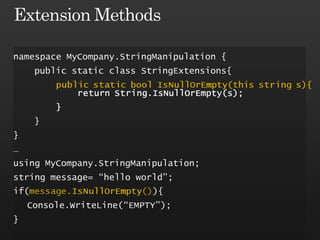
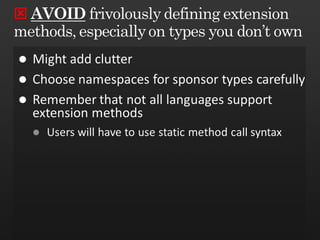
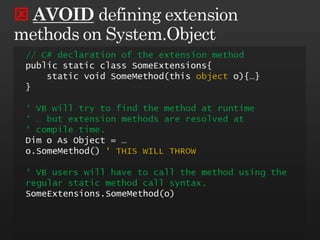
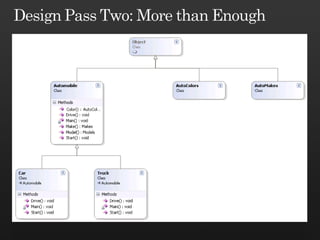
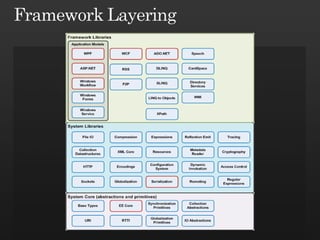
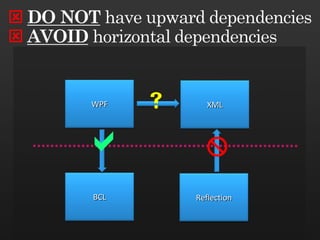
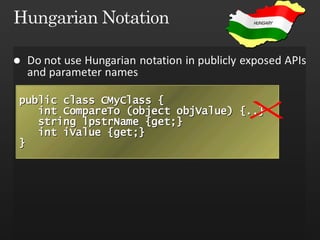
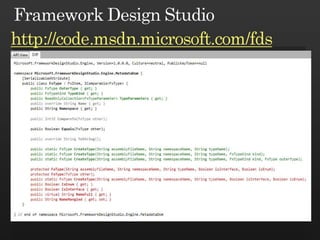
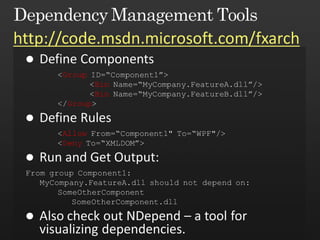
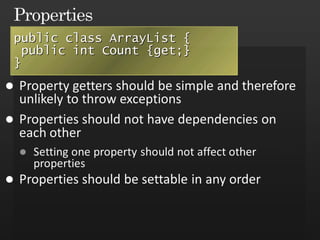
The document discusses best practices in framework design, highlighting the importance of dependency management for the successful evolution of frameworks. It includes code examples in C# demonstrating class inheritance, method overriding, and properties. The content emphasizes the need for defining contracts for virtual members and includes various naming conventions for code clarity.










![EmployeeList l = FillList(); for (int i = 0; i < l.Length; i++){ if (l.All[i] == x){...} } if (l.GetAll()[i]== x) {...} public Employee[] All {get{}} public Employee[] GetAll() {} Moral: Use method if the operation is expensive Calling Code](https://image.slidesharecdn.com/frameworkdesignguidelines-1225209286781447-8/85/Framework-Design-Guidelines-11-320.jpg)