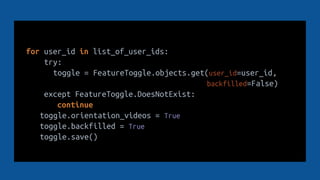
This document provides best practices for fixing data issues that occur in production databases. It recommends treating data fixes as code by checking fixes into source control, testing them, and conducting code reviews. It also advises logging all data fix executions, changes, and exceptions. Developers should make fixes idempotent and reversible when possible, be fault-tolerant of exceptions, and optimize for bottlenecks like CPU, memory, and database usage. Database snapshots should be used for testing and reverting changes.





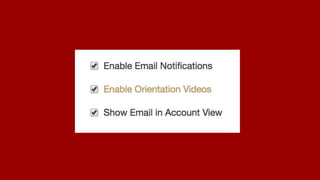
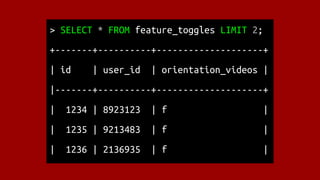
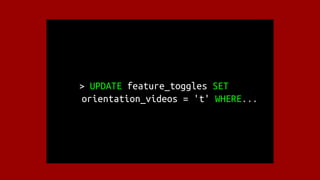









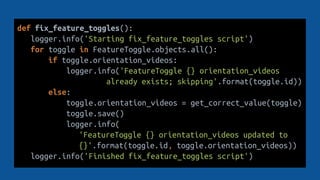


![import boto3
firehose = boto3.client('firehose')
def log_to_kinesis(message):
data = OrderedDict([
('script_name', get_filename_of_caller()),
('environment', settings.ENVIRONMENT),
('ts', str(pytz.utc.localize(datetime.datetime.now()))),
('message', message),
])
firehose.put_record(
DeliveryStreamName='backfill-logs',
Record={'Data': (json.dumps(data, sort_keys=False) + 'n')}
)](https://image.slidesharecdn.com/if4cxtrs0crwlhg42egv-signature-926e3305d6847a0c4682e650933a42ebfa20d8a7b2e894d78e0b59b6ec5be92f-poli-171007183907/85/Fixing-Web-Data-in-Production-20-320.jpg)

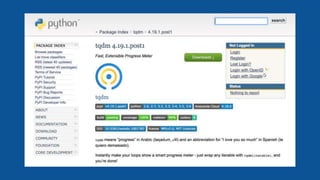
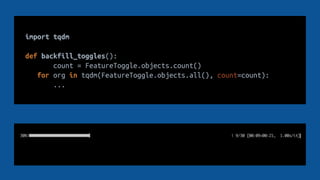

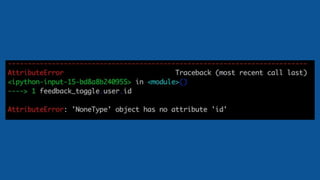
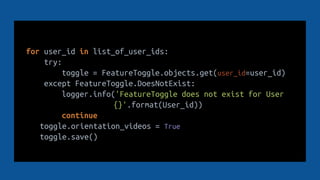






![feature_toggles = []
for user_id in user_ids_to_backfill:
feature_toggles.append(FeatureToggle(
user_id=user_id,
orientation_videos=True
)
)
FeatureToggle.objects.bulk_create(feature_toggles)](https://image.slidesharecdn.com/if4cxtrs0crwlhg42egv-signature-926e3305d6847a0c4682e650933a42ebfa20d8a7b2e894d78e0b59b6ec5be92f-poli-171007183907/85/Fixing-Web-Data-in-Production-34-320.jpg)
![def backfill_activity_progresses():
conn = psycopg2.connect("some_credentials")
cursor = conn.cursor(cursor_factory=psycopg2.extras.RealDictCursor)
data_to_replicate = []
for index in tqdm(batch_range):
cursor.execute("SELECT user_id, type, correct_answers,
total_answers, is_complete FROM legacy_activity ORDER BY id;")
data_to_replicate.append(cursor.fetchall())
conn.close()
add_to_new_activity_table(data_to_replicate)](https://image.slidesharecdn.com/if4cxtrs0crwlhg42egv-signature-926e3305d6847a0c4682e650933a42ebfa20d8a7b2e894d78e0b59b6ec5be92f-poli-171007183907/85/Fixing-Web-Data-in-Production-35-320.jpg)





















![Data analysis and visualization with mongo db [mongodb world 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/dataanalysisandvisualizationwithmongodbmongodbworld2016-160713161849-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2019] Java에서 Fiber를 이용하여 동시성concurrency 프로그래밍 쉽게 하기](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201927-200122095808-thumbnail.jpg?width=640&height=640&fit=bounds)















































