Download as PDF, PPTX





![4/21/2014 Faster Multi-Objective Optimization via GALE
[Sayyad & Ammar 2013] Report:
- NSGA-II and SPEA2 are the most popular search tools today
Popular Search Tools Evaluate Too Much
- O(N2) internal search: fast if solution evaluation is a cheap operation
- Need to count number of evaluations instead: O(2NG)
This Thesis Proposes GALE: O(2Log2(NG))
- GALE adds data mining to evaluate only the most-informative solutions
Main Message
Introduction
GALE:
597s
NSGA-II:
14,018s
N = population size
G = number of generations
6/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-6-320.jpg)
![4/21/2014 Faster Multi-Objective Optimization via GALE
Aircraft Studies for Safety Assurance
- Complex Simulations at NASA [8 seconds per run]
Standard MOO Tools
- Many [300] weeks
GALE
- Many [300] hours
Applications of MOO
!
* Asiana Flight Wreckage,
Summer 2013
(50400 hrs)
(1.8 wks)
1. Introduction
7/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-7-320.jpg)



![4/21/2014 Faster Multi-Objective Optimization via GALE
Mathematical Programming: [Dantzig]
- The aim is to find solutions that optimize objectives
- Transformation functions transform decisions (x) into objectives (y)
- Solutions are infeasible if they do not satisfy constraint functions
Formalities
2. Background
objectives
Constraint functionsOptimality direction
Transformation functions
a. Defines
11/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-11-320.jpg)


![4/21/2014 Faster Multi-Objective Optimization via GALE
Exterior Search [Dantzig]
- For Linear problems ( [Nelder & Mead 1965] made a non-linear version)
- Embed a simplex with solutions along the vertices
- Traverse along the nodes
- Good average Complexity
- But bad O(N3) worst case
Simplex Search
Nelder, John A.; R. Mead (1965). "A simplex method for
function minimization". Computer Journal 7: 308–313.
2. Background b. Early Methods
14/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-14-320.jpg)
![4/21/2014 Faster Multi-Objective Optimization via GALE
Karmarkar’s Algorithm – [Karmarkar 1984]
- Good for big data
- Fast convergence
- Polynomial complexity
- 50x faster than Simplex
- Single-Objective Only
- Requires Concavity
Interior Point Methods
Narendra Karmarkar (1984). "A New Polynomial Time Algorithm for Linear Programming", Combinatorica, Vol 4, nr. 4, p. 373–395.
2. Background b. Early Methods
15/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-15-320.jpg)

![4/21/2014 Faster Multi-Objective Optimization via GALE
Particle Swarm Optimization [Kennedy 1995]
- Real life swarms; flocks of birds, etc
- Swarm towards good solutions
- Self best and Pack best
Ant Colony Optimization [Dorigo 1992]
- Ant Colony Path Searches
- Pheromone density = best path
PSO & ACO
Kennedy, J.; Eberhart, R. (1995). "Particle Swarm
Optimization". Proceedings of IEEE International Conference on Neural
Networks IV. pp. 1942–1948.
M. Dorigo, Optimization, Learning and Natural Algorithms, PhD thesis,
Politecnico di Milano, Italy, 1992.
2. Background c. Recent Methods
17/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-17-320.jpg)

![4/21/2014 Faster Multi-Objective Optimization via GALE
NSGA-II [Deb 2002]
- Non-dominated Sorting Genetic Algorithm
- Standard select+crossover+mutation
- Sort by ‘bands’, or domination ‘depth’
- Break ties based on density
- crowding distance
NSGA-II
Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. (2002). "A fast
and elitist multiobjective genetic algorithm: NSGA-II". IEEE
Transactions on Evolutionary Computation 6 (2): 182
2. Background c. Recent Methods
19/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-19-320.jpg)
![4/21/2014 Faster Multi-Objective Optimization via GALE
SPEA2 [Zitzler2002]
- Strength Pareto Evolutionary Algorithm
- Standard select+crossover+mutation
- Sort by ‘strength’: count of solutions someone dominates
- Truncate crowded solutions via nearest neighbor
SPEA2
E. Zitzler, M. Laumanns, and L. Thiele. SPEA2: Improving the strength pareto evolutionary algorithm for multiobjective
optimization. Evolutionary Methods for Design Optimization and Control with Applications to Industrial Problems, 95--100, 2001.
2. Background c. Recent Methods
20/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-20-320.jpg)

![4/21/2014 Faster Multi-Objective Optimization via GALE
Experimental Rigor
- Want to maximize validity
- Because reasons to doubt GALE
- Still does good with few evals?
- Can still run fast?
We looked at literature for advice
- Search query targeted these questions:
- Ended up selecting 21 papers
Survey of MOO
Statistical Methods?
- [Demsar2006]: recommends
KS-Test + Friedman + Nemenyi
* J. Demsar, “Statistical comparisons of classifiers over multiple data sets,” ˇ J. Mach. Learn. Res., vol. 7, pp. 1–30, Dec. 2006.
Population size?
- 20 ~ 100 is good.
- Over 200 is a waste
Number of Repeats?
- [Harman 2012]: 30-50 is common.
- This Thesis: 20.
* M. Harman et al., Search based software engineering: techniques, taxonomy, tutorial. In Empirical Software Engineering and
Verification, Bertrand Meyer and Martin Nordio (Eds.). Springer-Verlag, Berlin, Heidelberg 1-59.
3. MOO Critique
22/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-22-320.jpg)





![4/21/2014 Faster Multi-Objective Optimization via GALE
Three key phrases to talk about
1. Active Learning
- Minimize cost of evaluation
- Learn more from using less [Settles 2009]
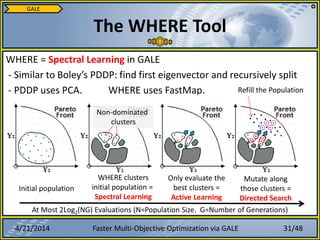
2. Spectral Learning (WHERE)
- Reasoning with eigenvectors via covariance matrix
- “Spectral Clustering” – via eigenvectors
- FastMap finds eigenvectors faster than PCA
3. Directed Search
- Shove solutions along promising directions
Components to GALE
some, not all
clustered
spectrally
Directed
mutation
4. GALE
28/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-28-320.jpg)

![4/21/2014 Faster Multi-Objective Optimization via GALE
Spectral clustering is O(n3) [Kumar12]
- Common method: PCA
- The Nystrom Method reduces to near-linear
- Low-rank approx. of covariance matrix
e.g.: FastMap is a Nystrom Algorithm [Platt05]
- 1) Pick an arbitrary point, z.
- 2) Let ‘east’ be the furthest point from z.
- 3) Let ‘west’ be the furthest point from ‘east’.
- 4) Project all points onto the line east-west
- 5) east-west is the first principal component
Nystrom Method
GALE
east
west
c
b
a x
Active Learning:
- Only evaluate East & West!
30/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-30-320.jpg)






![4/21/2014 Faster Multi-Objective Optimization via GALE
Research Questions:
- Number of Evaluations
- Runtime
- Quality of Solutions
4 Experiment Areas:
- #1 Aircraft Safety
- #2 Agile Software Development
- #3 Constrained Lab Models
- #4 Unconstrained Lab Models
Experimental Methods
6. Experiments
1. Run the Model 500 times
2. Collect an average-case baseline
3. Compute loss (x, baseline) for each solution x
4. The median loss is the “Quality Score”
o = number of objectives
Quality Score:
> 1.0: Loss in Quality from Baseline
= 1.0: No Change from Baseline
< 1.0: Improvement from Baseline
[Zitzler & Kunzli 2004]
38/48](https://image.slidesharecdn.com/final-140421160656-phpapp02/85/Faster-Evolutionary-Multi-Objective-Optimization-via-GALE-the-Geometric-Active-Learner-38-320.jpg)











This document presents a Ph.D. defense on a thesis proposal concerning a new multi-objective optimization method named GALE, which aims to improve upon existing algorithms like NSGA-II and SPEA2 by significantly reducing evaluation times and enhancing solution quality. The thesis responds to critiques from a previous proposal by emphasizing rigorous methodologies, broad literature reviews, and the validation of GALE's contributions through extensive experimental results across various application areas. Ultimately, the work aims to demonstrate GALE's capabilities as a competitive tool in the field of multi-objective optimization.