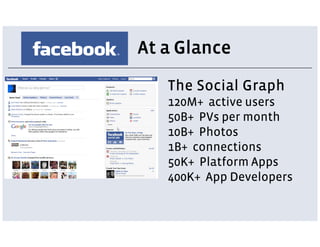
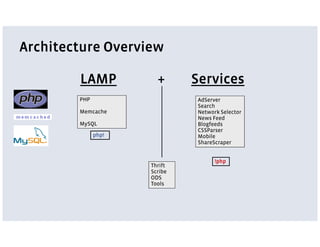
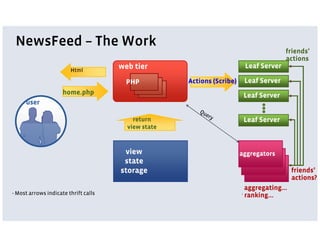
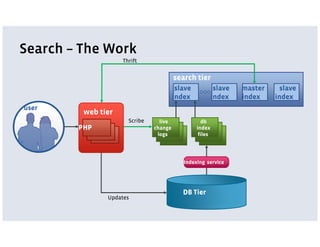
Facebook uses a LAMP stack with additional services and customizations for its architecture. PHP and MySQL are used for the main web and data tiers but have limitations for large scale. Services are implemented using Thrift for cross-language communication and Scribe for distributed logging. Services allow storing code closer to data and using optimized languages. The News Feed and Search architectures incorporate services, distributed data storage, and caching to provide personalized experiences for over 120 million active users.



















































![JavaOne2016 - Microservices: Terabytes in Microseconds [CON4516]](https://cdn.slidesharecdn.com/ss_thumbnails/javaone2016microservicesfinal-160922163749-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Slideshare]fardh ain(introduction lesson#1)may2010](https://cdn.slidesharecdn.com/ss_thumbnails/slidesharefardhainintroduction-lesson1may2010-100506110523-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





































![Lucene 3[1] 0 原理与代码分析](https://cdn.slidesharecdn.com/ss_thumbnails/lucene31-0-100225194736-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







