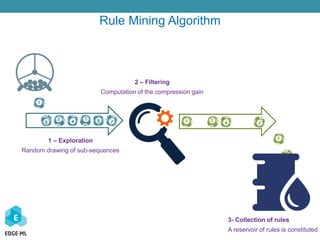
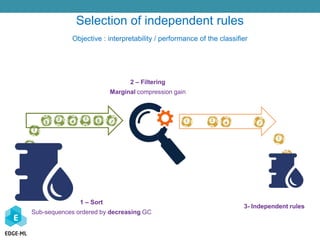
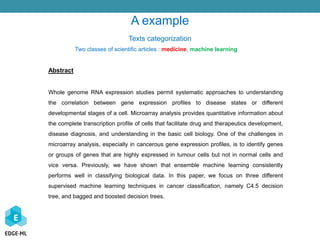
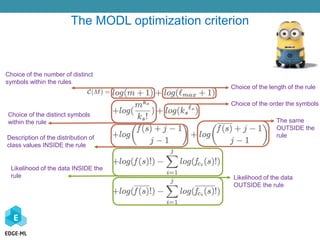
The document discusses a Bayesian approach to model selection for mining sequential rules in data, particularly focusing on machine learning techniques for classifying biological data related to cancer. It emphasizes the challenges in analyzing gene expression profiles and the effectiveness of ensemble machine learning methods. Additionally, the document presents various applications of sequential data mining in fields such as spam detection and article categorization, showcasing the performance metrics of different classifiers.



![[4] M. E. Egho, D. Gay, N. Voisine, M. Boullé, F. Clérot. A Parameter-Free Approach for Mining Robust
Sequential Classification Rules. ICDM 2015.
Mac Boullé : http://www.marc-boulle.fr
Bibliography, implemented articles](https://image.slidesharecdn.com/video4sequenceeng-170827140718/85/EXTRACTION-OF-SEQUENTIAL-RULES-VIDEO-4-4-3-320.jpg)




![Other kinds of variable: adaptation of the criterion
< … > sequences
[ … ] lists
{ … } ensembles
1 – Computation of the supports (specific indexation technic)
2 – The order of the symbols is not encoded for the sub-set rules
Sub-list : contignuous symbols
Sub-set : symbol without order](https://image.slidesharecdn.com/video4sequenceeng-170827140718/85/EXTRACTION-OF-SEQUENTIAL-RULES-VIDEO-4-4-11-320.jpg)