Download as PDF, PPTX









![How can we achieve the following
in Ruby1?
string = “Hello world. Let’s try segmentation.”
Desired output: [“Hello world.”, “Let’s try segmentation.”]
Pragmatic Segmenter1 Using the core or standard library (no gems)](https://image.slidesharecdn.com/exploringnaturallanguageprocessinginruby-150409101413-conversion-gate01/85/Exploring-Natural-Language-Processing-in-Ruby-9-320.jpg)
![Some potential answers
• string.scan(/[^.]+[.]/).map(&:strip)!
• string.scan(/(?<=s|A)[^.]+[.]/)!
• string.split(/(?<=.)s*/)!
• string.split(/(?<=.)/).map(&:strip)!
• string.split('.').map { |segment| segment.strip.insert(-1, '.') }!
• … your answer
Pragmatic Segmenter](https://image.slidesharecdn.com/exploringnaturallanguageprocessinginruby-150409101413-conversion-gate01/85/Exploring-Natural-Language-Processing-in-Ruby-11-320.jpg)
![Let’s change the original string
string = “Hello from Mt. Fuji. Let’s try segmentation.”
Desired output: [“Hello from Mt. Fuji.”, “Let’s try segmentation.”]
Pragmatic Segmenter](https://image.slidesharecdn.com/exploringnaturallanguageprocessinginruby-150409101413-conversion-gate01/85/Exploring-Natural-Language-Processing-in-Ruby-12-320.jpg)
![Uh oh…
string = “Hello from Mt. Fuji. Let’s try segmentation.”
=> [“Hello from Mt.”, “Fuji.”, “Let’s try segmentation.”]
string.scan(/[^.]+[.]/).map(&:strip)
Pragmatic Segmenter](https://image.slidesharecdn.com/exploringnaturallanguageprocessinginruby-150409101413-conversion-gate01/85/Exploring-Natural-Language-Processing-in-Ruby-13-320.jpg)



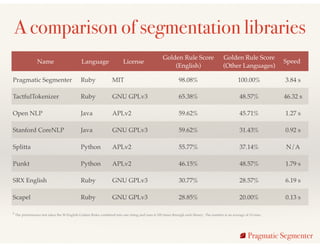
![The Holy Grail
Pragmatic Segmenter
A.M. / P.M. as non sentence boundary and sentence boundary
At 5 a.m. Mr. Smith went to the bank. He left the bank at 6 P.M. Mr. Smith then went to the store.
Golden Rule #18
All tested segmentation libraries failed this spec
["At 5 a.m. Mr. Smith went to the bank.", "He left the bank at 6 P.M.", "Mr. Smith then went to the store."]](https://image.slidesharecdn.com/exploringnaturallanguageprocessinginruby-150409101413-conversion-gate01/85/Exploring-Natural-Language-Processing-in-Ruby-18-320.jpg)
















The document discusses natural language processing (NLP) in Ruby, focusing on sentence segmentation with a specific tool called Pragmatic Segmenter. It highlights the importance of segmentation as a foundation for various NLP tasks and outlines methods for segmentation while addressing the limitations of existing libraries. Additionally, it introduces projects like Chat Correct and Word Count Analyzer, which aim to assist in language learning and understanding discrepancies in word counts, respectively.




































































