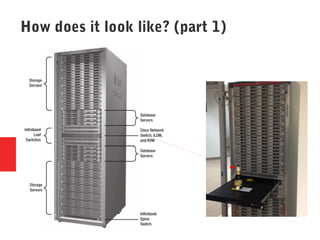
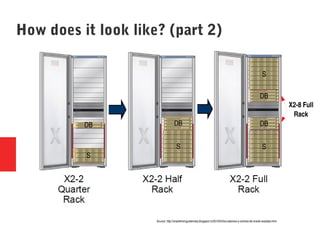
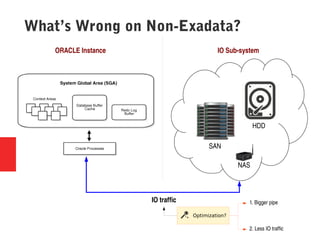
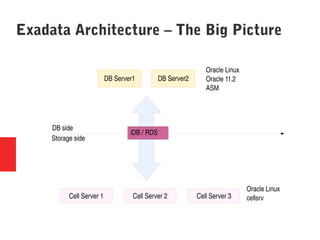
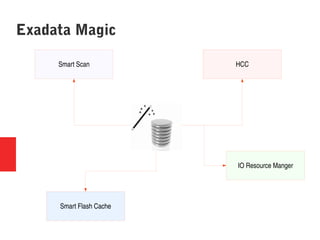
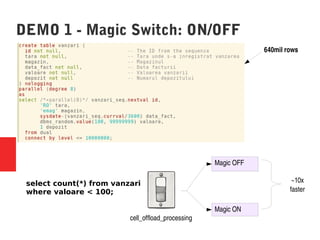
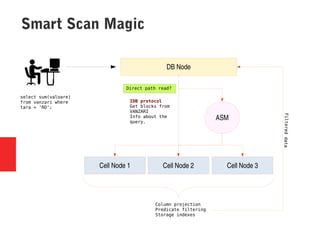
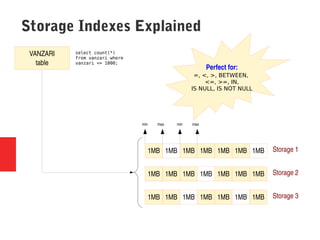
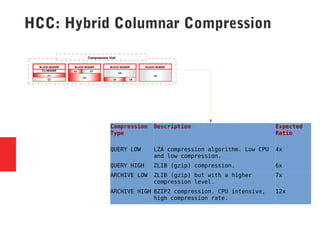
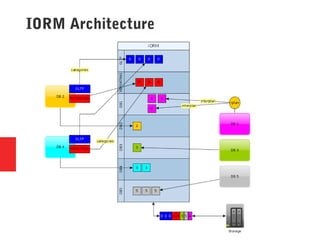
Oracle Exadata is a database machine that combines hardware and software. It consists of database servers, storage servers, and InfiniBand switches housed in a self-contained rack. Exadata uses several technologies like smart scan, storage indexing, predicate filtering, and smart flash cache to improve database performance. It also features a flash cache, hybrid columnar compression, and an I/O resource manager. Exadata timelines show the improvements in each version from 2008 to the present. Exadata provides many benefits but also has some limitations and challenges around its closed architecture, integration with the optimizer, and high price tag.











































![[Oracle DBA & Developer Day 2012] 高可用性システムに適した管理性と性能を向上させるASM と RMAN の魅力](https://cdn.slidesharecdn.com/ss_thumbnails/ma-4print20121205-200702094006-thumbnail.jpg?width=640&height=640&fit=bounds)


















































