Download to read offline


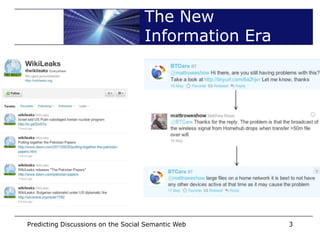
![Social Data
Publication Rates
• ~600 Tweets per second [1]
• ~700 Facebook status updates per second [1]
• Spinn3r dataset collected from Jan – Feb 2011
[2]
– 133 million blog posts
– 5.7 million forum posts
– 231 million social media posts
[1] http://searchengineland.com/by-the-numbers-twitter-vs-facebook-vs-google-buzz-36709
[2] http://icwsm.org/data/index.php
Predicting Discussions on the Social Semantic Web 2](https://image.slidesharecdn.com/eswc2011-socialweb-discussionpredictions-110601042349-phpapp01-120228054024-phpapp02/85/Eswc2011-socialweb-discussionpredictions-3-320.jpg)





![T he likelihood of post s elicit ing replies depends upon popularity, a highly subjec-
t ive t erm influenced by ext ernal fact ors. Propert ies influencing popularity include
Features
user at t ribut es - describing t he reput at ion of t he user - and at t ribut es of a post ’s
cont ent - generally referred t o as cont ent feat ures. In Table 1 we define user and
cont ent feat ures and st udy t heir influence on t he discussion “ cont inuat ion” .
T abl e 1. User and Cont ent Feat ures
U ser Feat ur es
I n D eg r ee: N umb er of fol l ower s of U #
O u t D eg r ee: N umb er of user s U fol l ows #
L i st D eg r ee: N umb er of l i st s U app ear s on. L i st s gr ou p user s by t op i c #
P o st C o u n t : T ot al numb er of p ost s t he user has ever p ost ed #
U ser A g e: N umb er of m i nut es fr om user j oi n dat e #
P ost C ou n t
P o st R at e: Post i ng fr equency of t he user U s er A g e
Cont ent Feat ur es
P o st l en g t h : L engt h of t he p ost i n char act er s #
C o m p l ex i t y : Cumul at i ve ent r opy of t he uni que wor ds i n p ost p λ
i ∈ [1, n ] p i ( l og λ − l og p i )
of t ot al wor d l engt h n and pi t he fr equency of each wor d λ
U p p er ca se co u n t : N umb er of upp er case wor ds #
R ead ab i l i t y : G unni ng fog i ndex usi ng aver age sent ence l engt h ( A SL ) [7]
and t he p er cent age of com pl ex wor d s ( P C W ) . 0.4( A SL + P C W )
V er b C o u n t : N umb er of ver bs #
N ou n C ou nt : N umb er of nouns #
A d j ect i v e C ou n t : N umb er of adj ect i ves #
R ef er r al C o u n t : N umb er of @user #
T i m e i n t h e d ay : N or m al i sed t i m e i n t he day m easur ed i n m i nut es #
I n f o r m at i v en ess: T er m i nol ogi cal novel t y of t he p ost wr t ot her p ost s
T he cumul at i ve t fI df val ue of each t er m t i n p ost p t∈p t f i df ( t , p)
P o l ar i t y : Cumul at ion of p ol ar t er m weight s in p ( using
P o+ N e
Sent i wor dnet 3 l ex i con) nor m al i sed by p ol ar t er m s count | t er m s |
4.2 Ex p er im ent s
Predicting Discussions on the Social Semantic Web 10
Experiment s are int ended t o t est t he performance of different classificat ion mod-](https://image.slidesharecdn.com/eswc2011-socialweb-discussionpredictions-110601042349-phpapp01-120228054024-phpapp02/85/Eswc2011-socialweb-discussionpredictions-11-320.jpg)
![different motives which do not necessarily designat e a response t o t he initial
Identifying Seed
message. T herefore, we only invest igat e explicit replies to messages. To gather
our discussions, and our seed post s, we it erat ively move up t he reply chain - i.e.,
Posts
from reply t o parent post - until we reach t he seed post in t he discussion. We
define this process as dataset enrichment, and is performed by querying T wit t er’s
• Experiments
REST API 6 using t he in reply to id of t he parent post, and moving one-st ep at
a t ime up the reply chain. T his same approach has been employed successfully
– Haiti and Union Address Datasets
in work by [12] t o gather a large-scale conversation dat aset from T wit ter.
– Divided each dataset up using 70/20/10 split for
training/validation/testing s used for experiment s
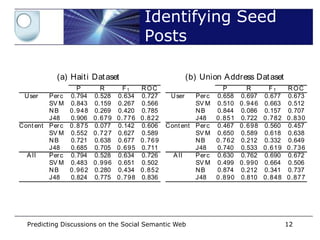
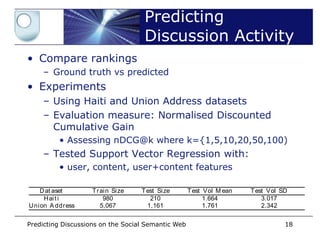
T abl e 2. St at ist ics of t he dat aset
D at aset U ser s T weet s Seeds N on-Seeds Repli es
H ai t i 44,497 65,022 1,405 60,686 2,931
U ni on A ddr ess 66,300 80,272 7,228 55,169 17,875
TableEvaluated a binary classification task datasets. One can
– 2 shows the statist ics that explain our collected
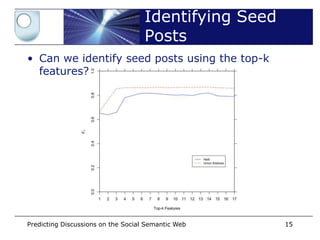
• Is this post a seed post or not?
observe the difference in conversat ional tweet s between t he two corpora, where
t he Hait i dat aset cont ains fewer F1 and Areaa percent age t han t he Union
• Precision, Recall, seed post s as under ROC
dataset, and therefore fewer replies. However, as we explain lat er a lat er sect ion,
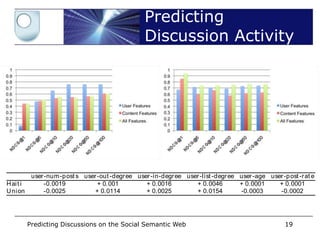
• Tested: user, content, user+content features
this does not correlate with a higher discussion volume in the former dat aset. We
convert t he collected dataset s from SVM, Naïve Bayesformat s int o triples,
– Tested Perceptron, t heir propriet ary JSON and J48
annot ated using concepts from our above behaviour ont ology, this enables our
features t o be derived by querying our dat aset s using basic SPARQL queries.
Predicting Discussions on the Social Semantic Web 11](https://image.slidesharecdn.com/eswc2011-socialweb-discussionpredictions-110601042349-phpapp01-120228054024-phpapp02/85/Eswc2011-socialweb-discussionpredictions-12-320.jpg)

![Predicting
Discussion Activity
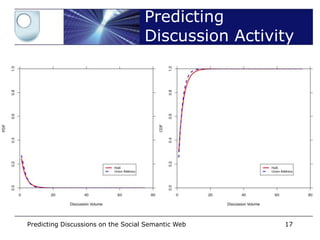
• From identified seed posts:
– Can we predict the level of discussion activity?
– How much activity will a post generate?
• [Wang & Groth, 2010] learns a regression
model, and reports on coefficients
– Identifying relationship between features
• We do something different:
– Predict the volume of the discussion
Predicting Discussions on the Social Semantic Web 16](https://image.slidesharecdn.com/eswc2011-socialweb-discussionpredictions-110601042349-phpapp01-120228054024-phpapp02/85/Eswc2011-socialweb-discussionpredictions-17-320.jpg)





The document discusses predicting discussions on the social semantic web, highlighting the massive scale of social data generation across platforms like Twitter and Facebook. It outlines methods to identify seed posts and anticipate discussion activity based on user and content features, emphasizing the importance of semantics and the challenges posed by heterogeneous data. The findings also include experimentation with different classification models to effectively identify seed posts and predict discussion activity levels.



































































