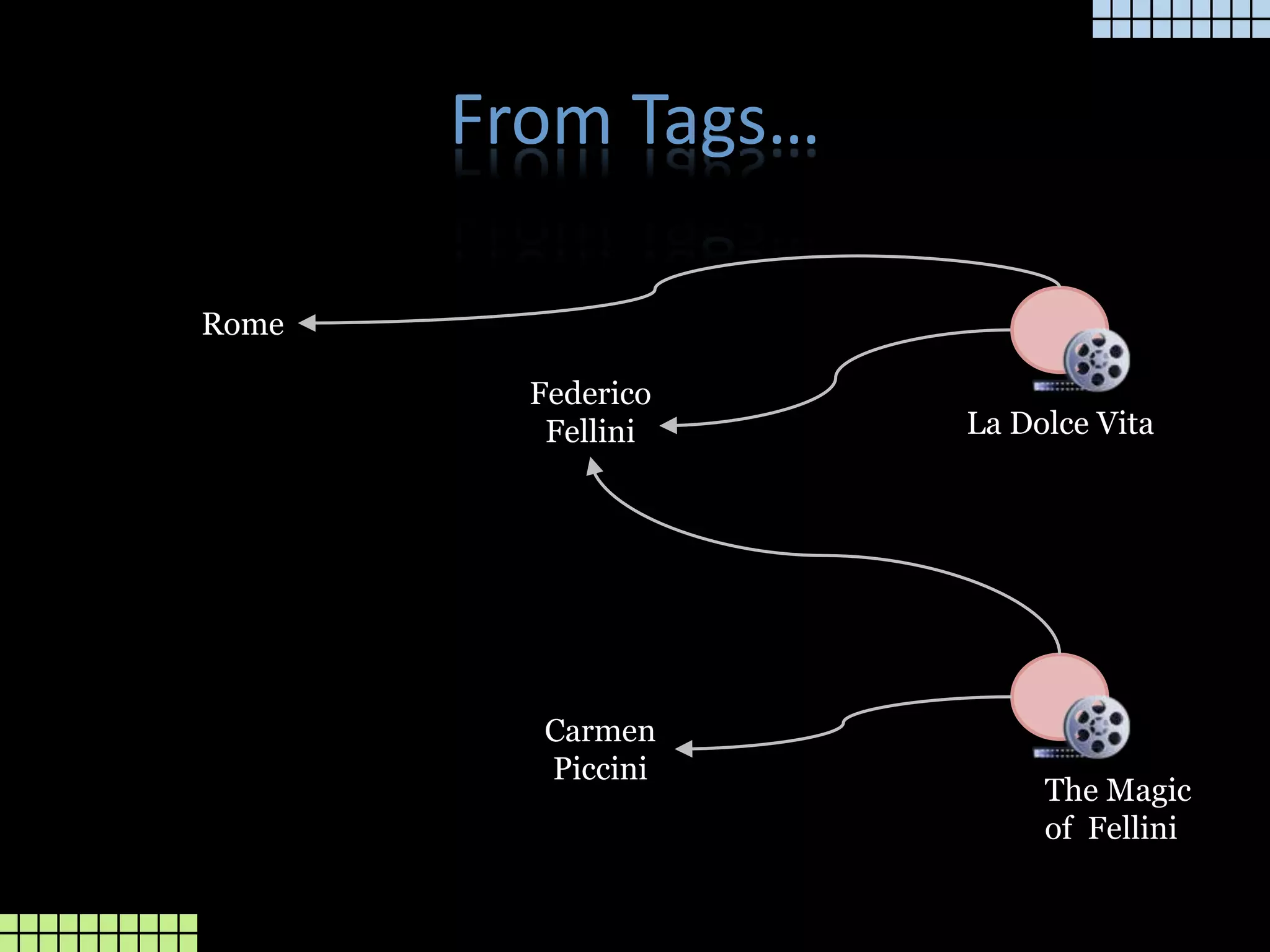
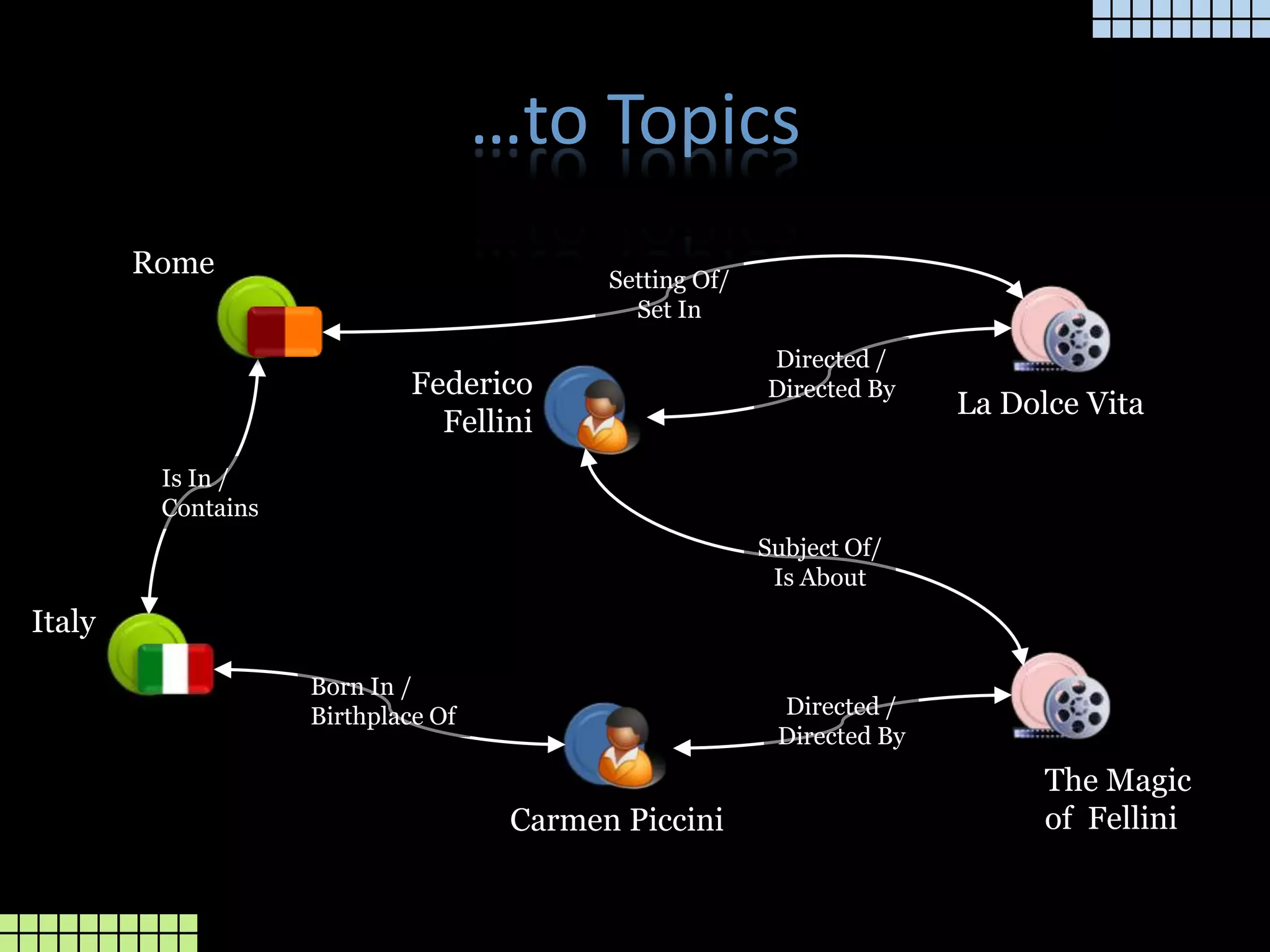
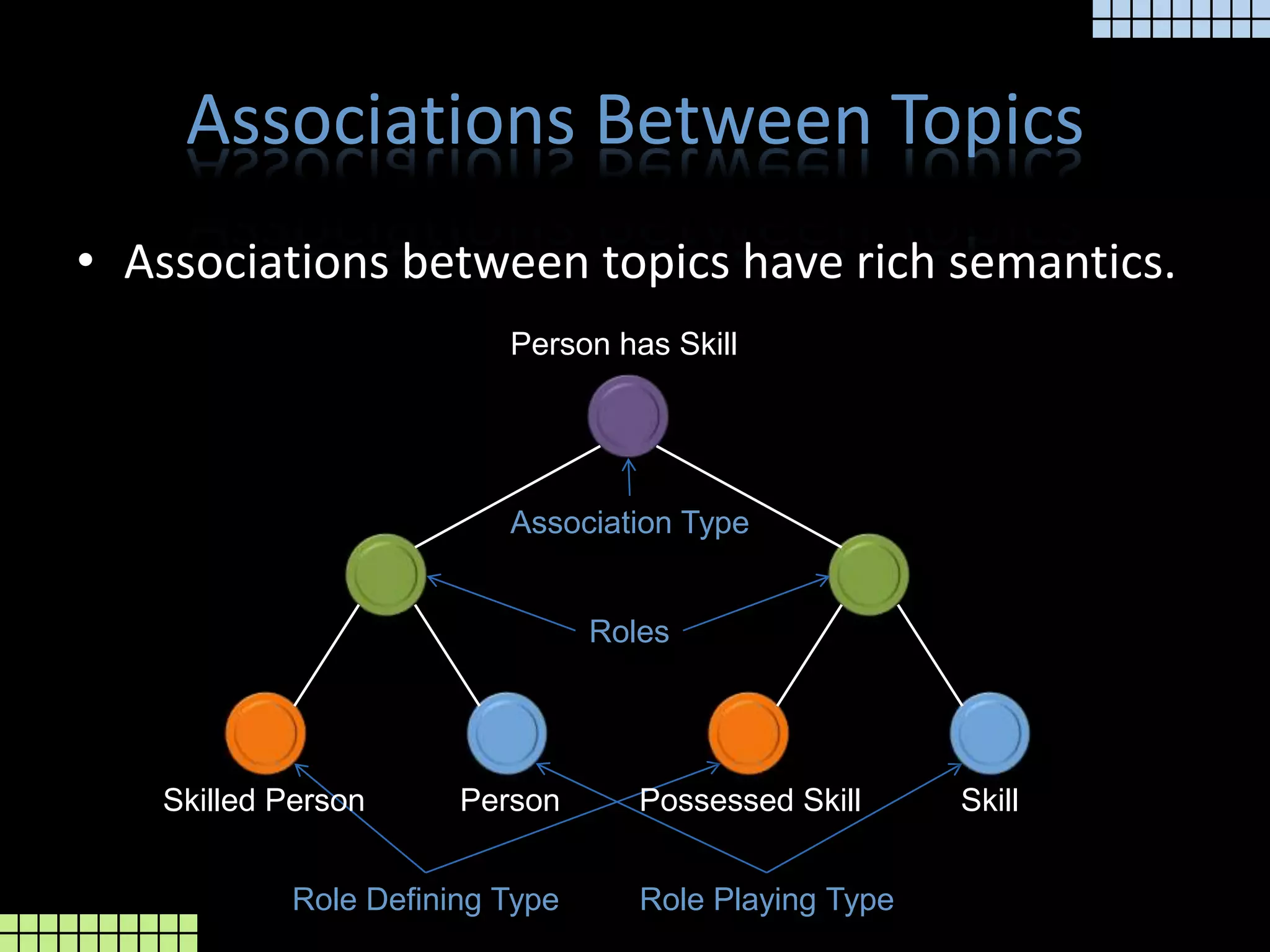
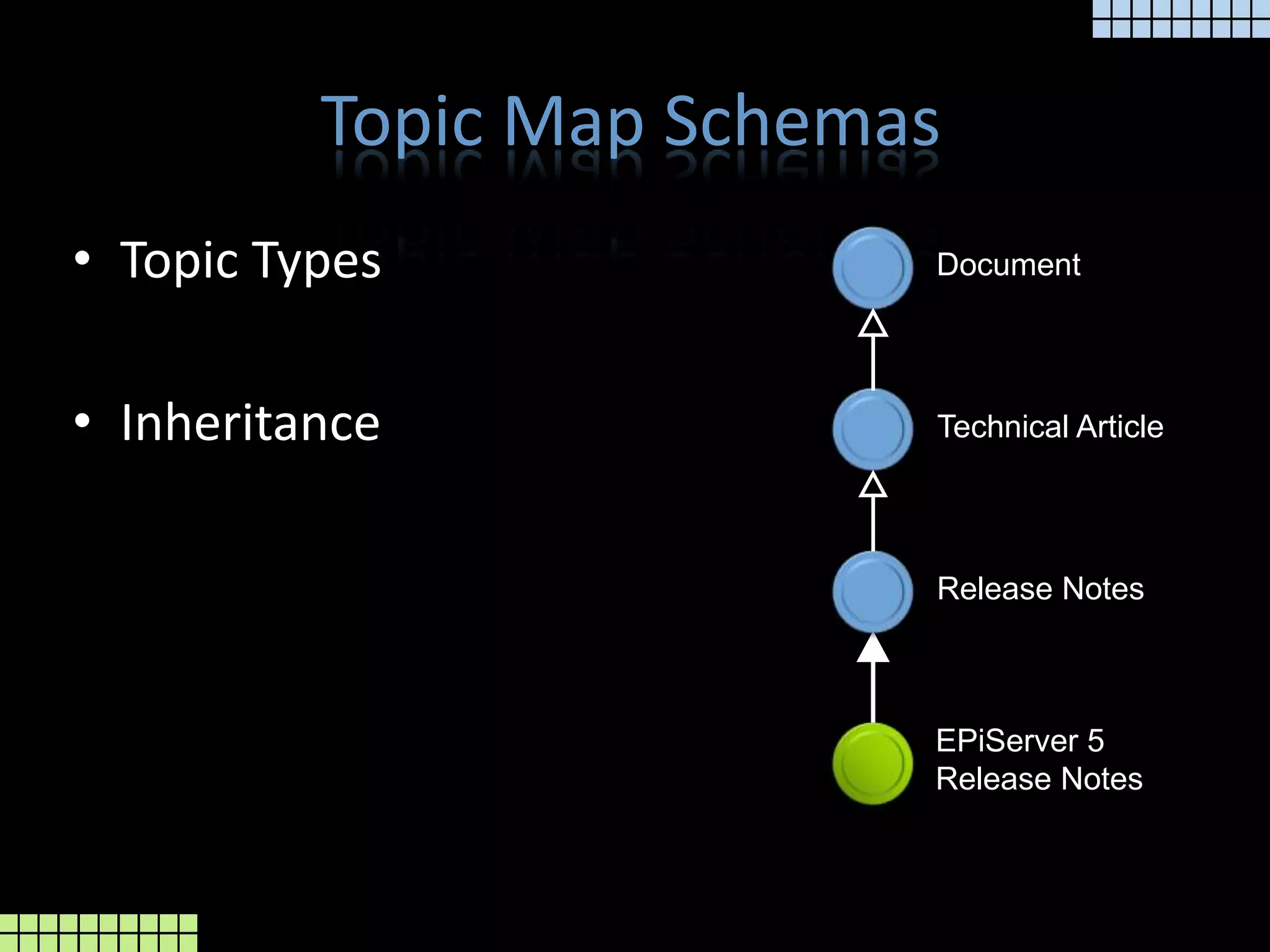
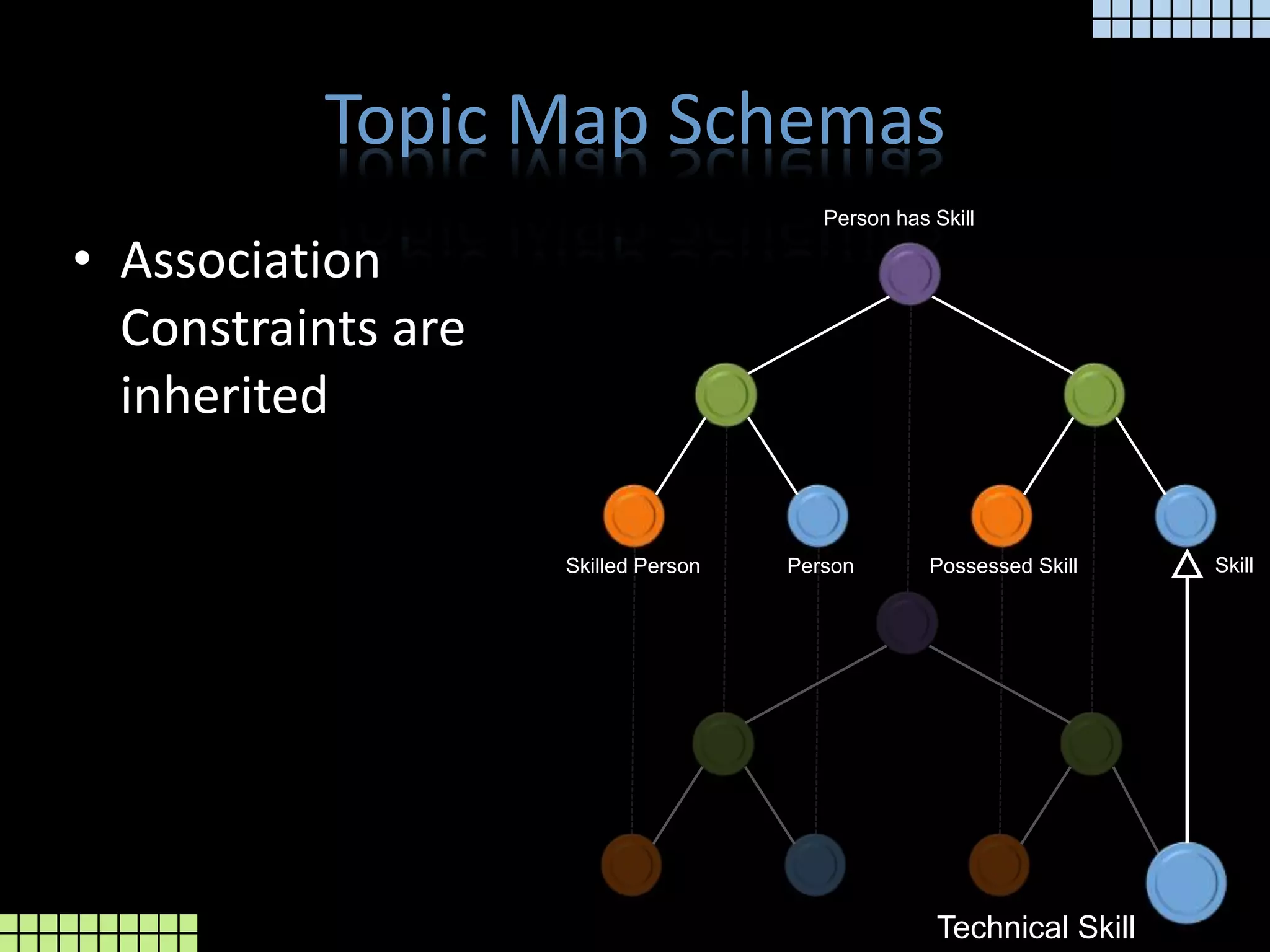
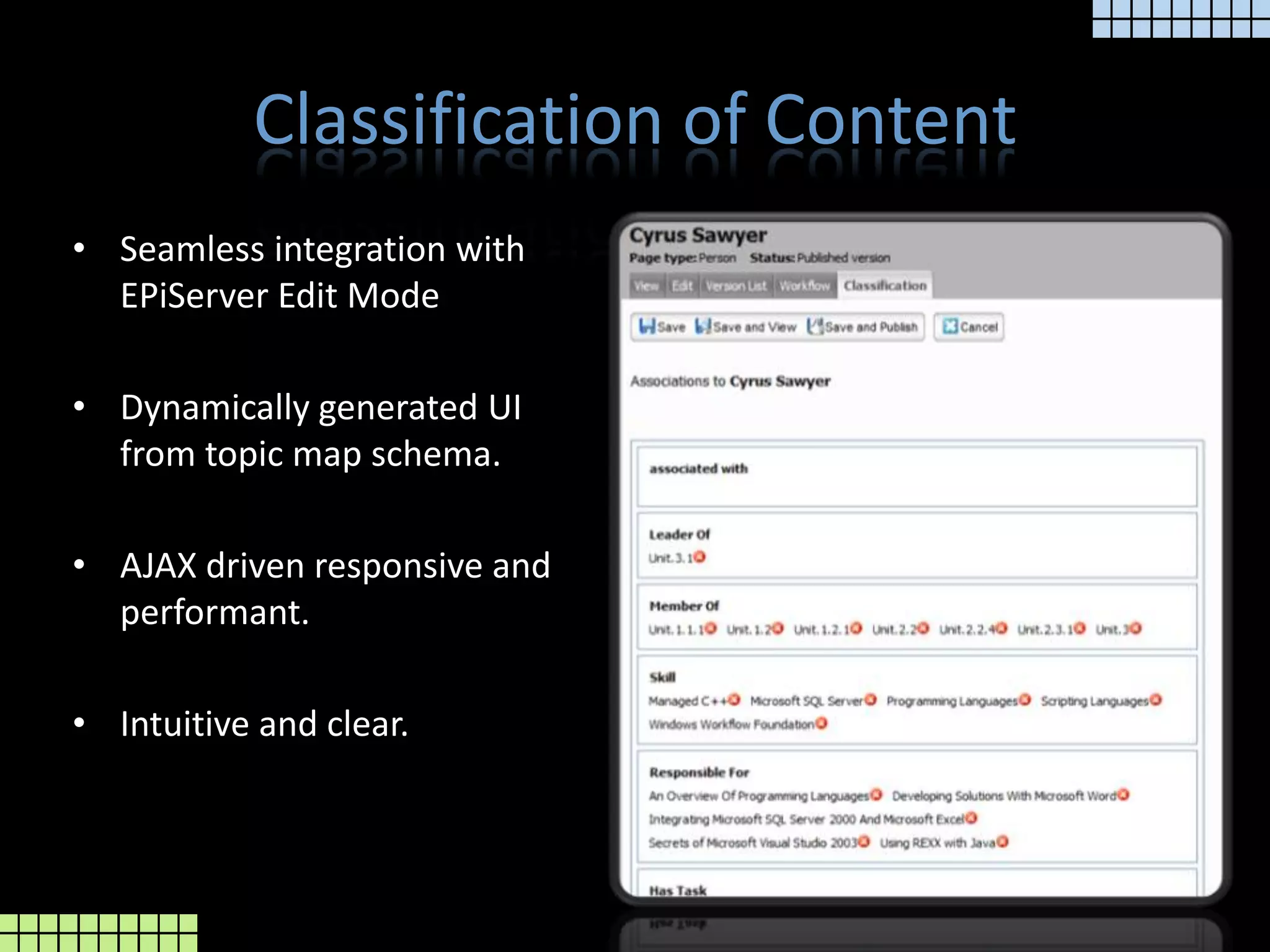
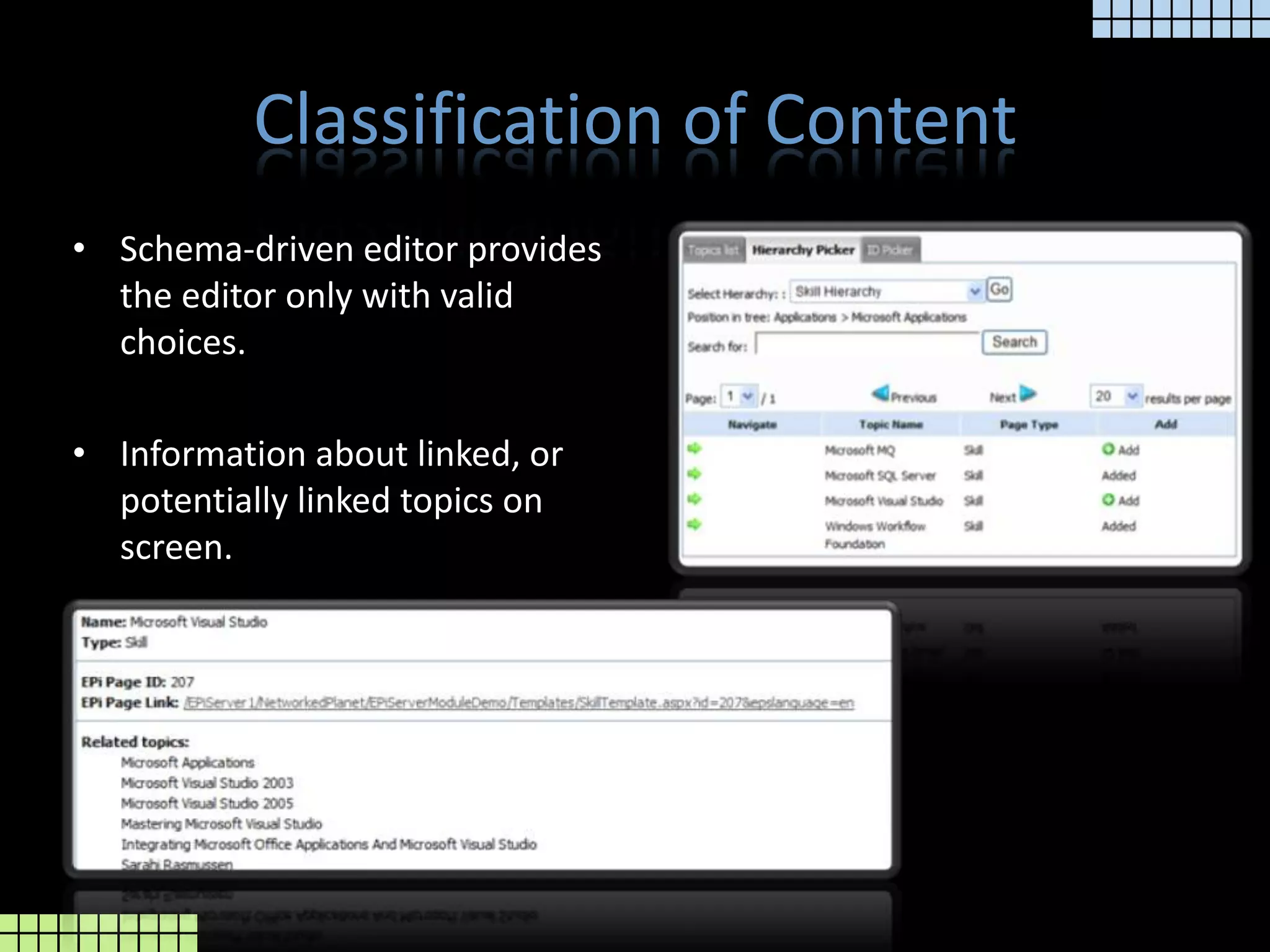
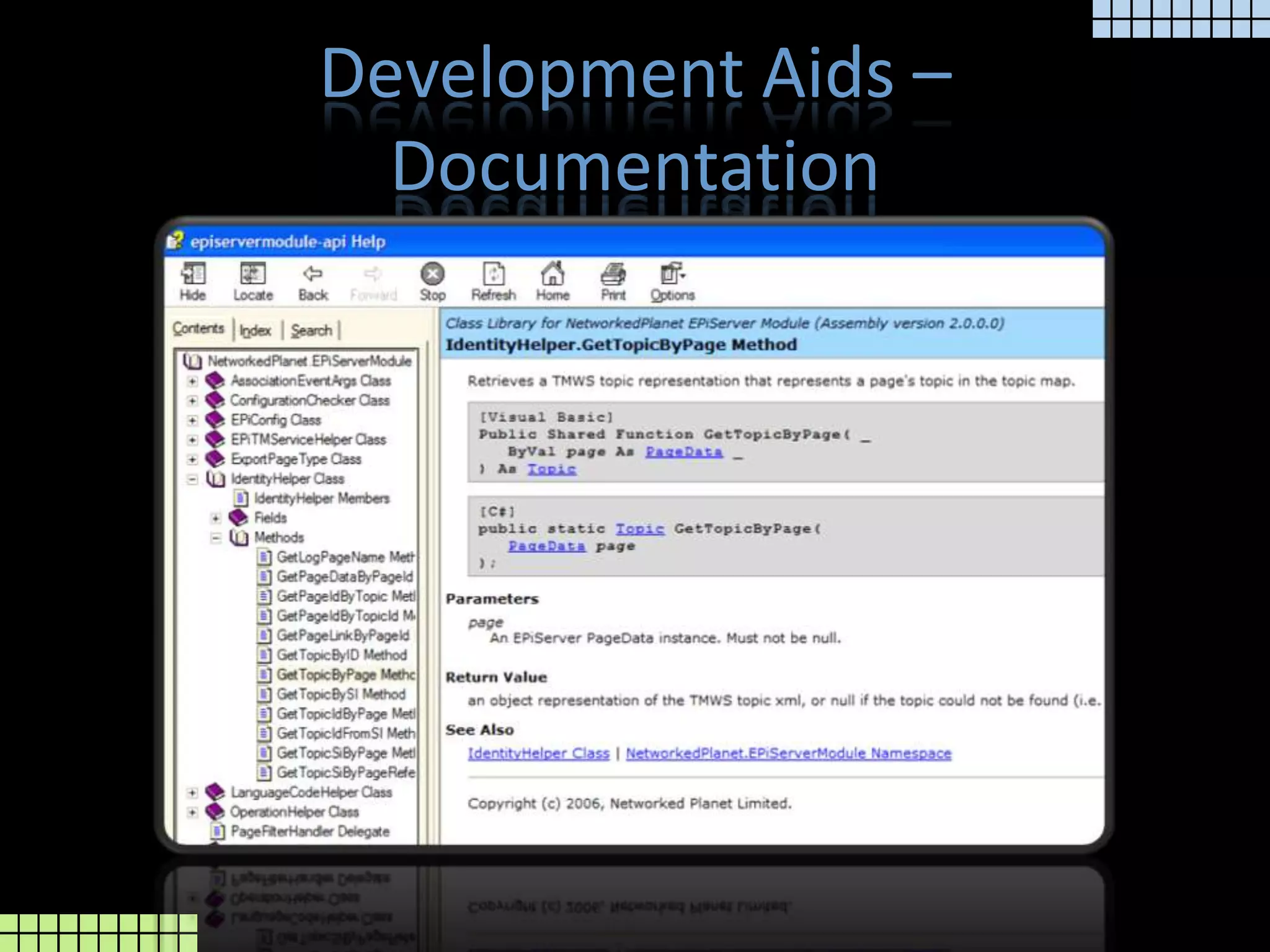
The document provides a technical overview of the tmcore Episerver module, focusing on the concept of topic maps to improve content navigation and management within Episerver. It outlines the challenges users face with current navigation and link management and presents topic maps as a solution for integrating heterogeneous content and enhancing semantic search capabilities. Additionally, it discusses the classification of content and the development aids available for implementing topic maps, emphasizing the importance of user needs alongside technology.






















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















