리눅스 컨테이너
3
리눅스에서 운영체제 가상화를 지원하는 방법
“프로세스 그룹을 각자 별도의 시스템인 것처럼 보이게 만든다”
운영 체제(커널)는 호스트와 게스트가 공유하면서 데이터
는 별도 사용한다.
각 게스트를 컨테이너라고 부르며 운영 체제의 기능을 사용
하여 상호 독립적으로 고립시키는 개념
제어 그룹 네임스페이스 COW 파일시스템
하드웨어를 가상화한 게 아니므로 가상화 오버헤드가 거의
없다.
4.
제어 그룹 (cgroups)
4
2006년‘프로세스 컨테이너’라는 이름으로 두 명의 구글 엔지니어가 개발 시작
그룹 단위로 최대 사용 가능한 메모리량 제한
리소스(cpu, memory, Disk I/O) 제약을 할 수 있는 프로세스들의 그룹
리소스 제약
우선 순위 조정
사용량 측정
실행 제어 그룹에 속한 프로세스들을 체크포인팅, 멈춤, 재실행 등의 제어
그룹별로 CPU 우선순위나 Disk I/O 성능 조절
그룹별로 사용량 측정. 서비스 과금으로 사용 가능
5.
Namespace
5
프로세스 그룹을 마치별도의 시스템인 것처럼 고립시켜 볼 수 있는 방법
cgroups가 얼마나 사용할 수 있는지를 제어하는 것이라면
namespace는 어디까지 볼 수 있는지(사용할 수 있는지)를 제어하는 것
pid 번호를 1부터 새로 매기는 네임스페이스pid
net
mnt
uts, ipc, user, .. hostname 변경, ipc 네임스페이스, uid/gid mapping, ..
네트웍 장치, 라우팅 테이블, 방화벽, 소켓 등의 네임스페이스
파일시스템의 root를 변경하는 것. chroot
6.
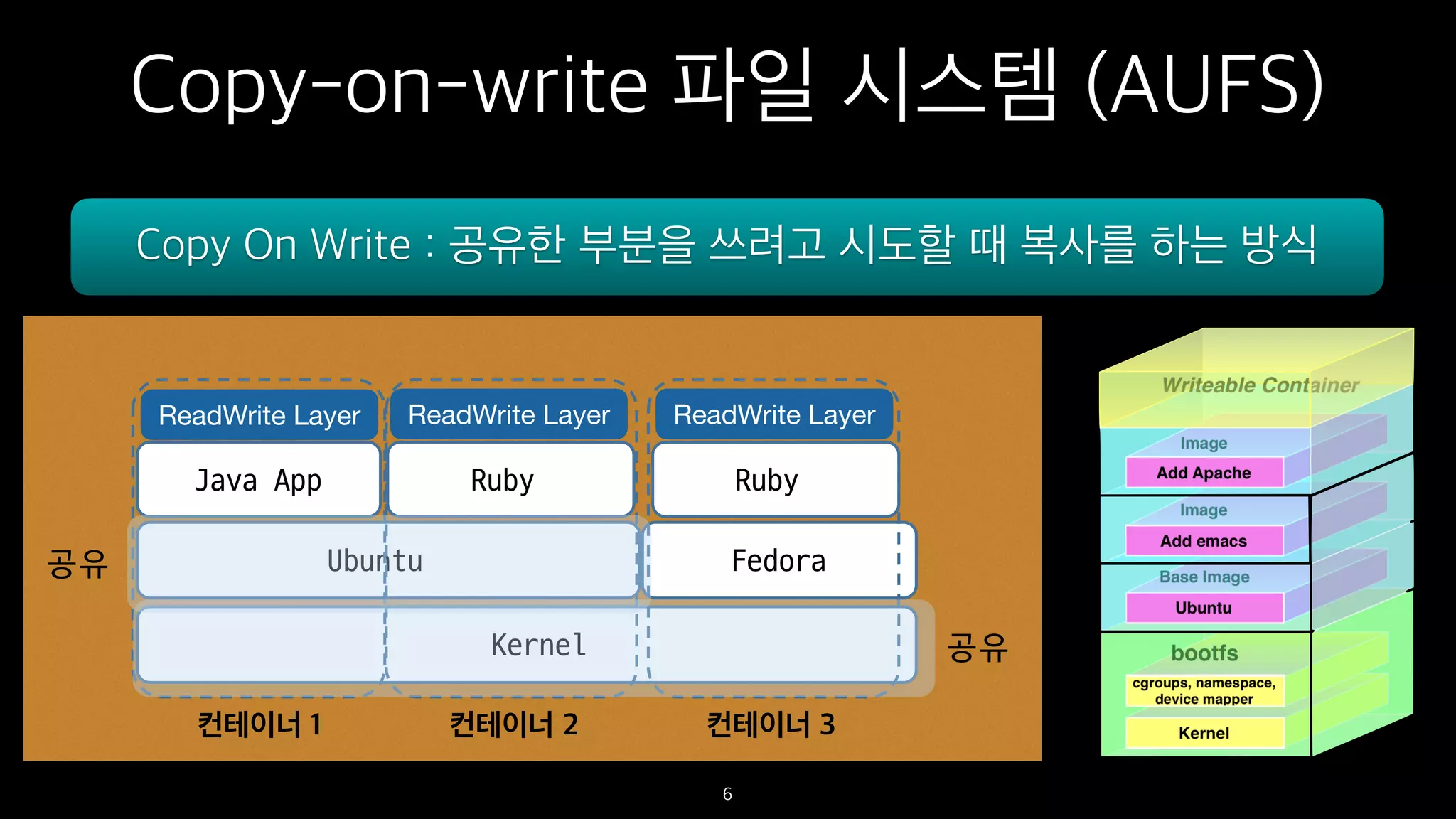
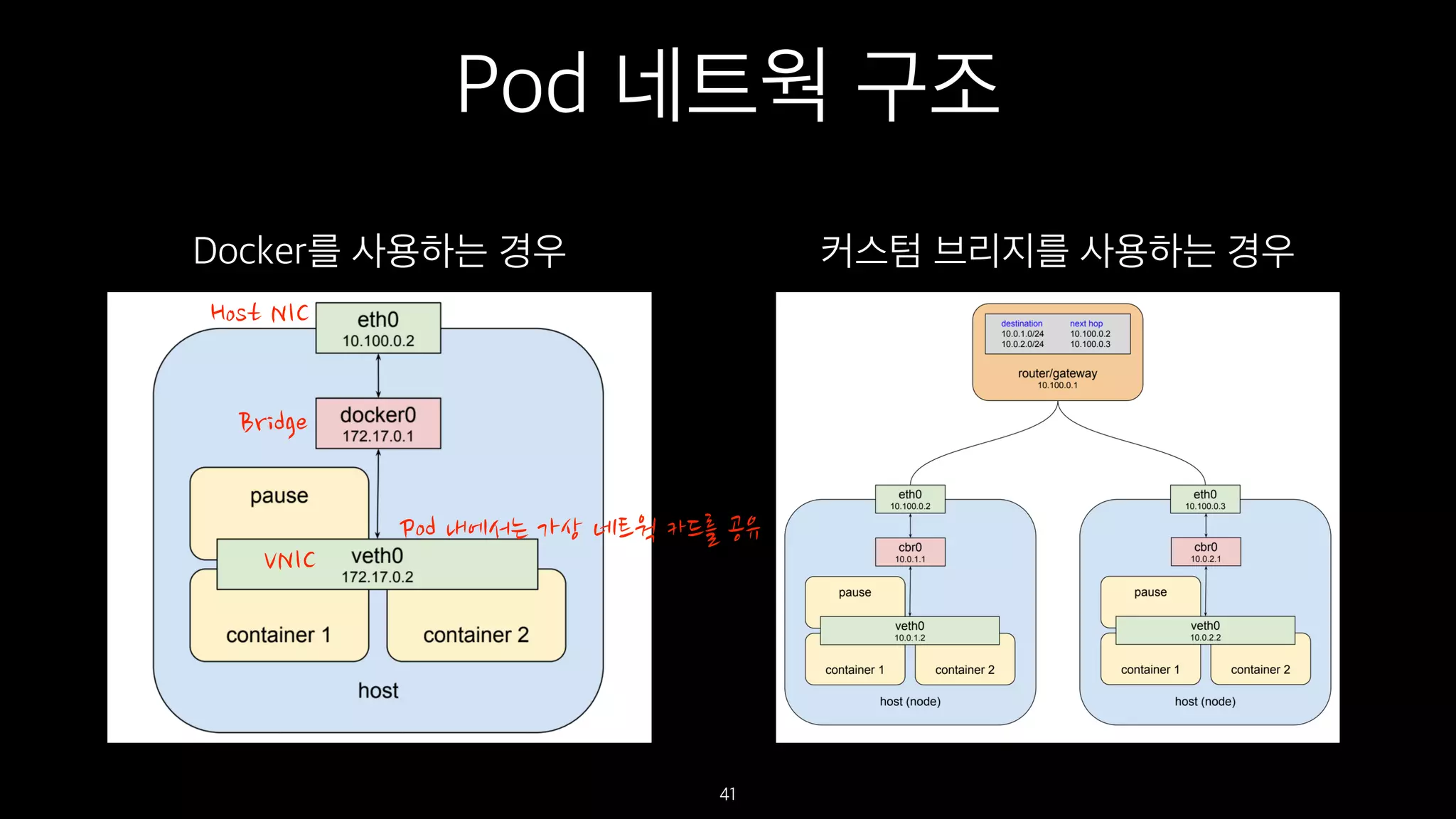
Copy-on-write 파일 시스템(AUFS)
6
Copy On Write : 공유한 부분을 쓰려고 시도할 때 복사를 하는 방식
AAAAAKernel
AAAAAUbuntu AAAAAFedora
AAAAA AAAAAJava App Ruby AAAAARuby
Container Container Container
공유
공유
컨테이너 1 컨테이너 2 컨테이너 3
ReadWrite Layer ReadWrite Layer ReadWrite Layer
7.
1. 클라우드 스케줄링
2.클러스터 관리자
3. 쿠버네티스
4. 쿠버네티스 기본 객체
5. 쿠버네티스 컨트롤러
6. 미니쿠베
7. 모니터링
차례
8
스케줄링이란?
• 작업 부하를처리 가능한 자원에 할당하는 수단
Scheduling is a method to to assign workloads to resources
that can handle those workloads
• (질문) 만약 컴퓨터 물리 노드 하나에 보통 60여개의 마이크로서비스 서버
용 컨테이너를 실행할 수 있고 현재 100대의 물리 노드들로 클라우드 컨테
이너 서비스를 운영 중이라고 가정해보자.
새로 다섯 대의 마이크로서비스 서버 컨테이너가 Wrapsody eCo 서비
스를 위해 필요하다. 각각 어느 물리 노드에 컨테이너를 할당하는 게 가
장 좋을까?
10
10.
스케줄링의 목표에 고려할사항
• Thruput(처리량) 증가
IO 경쟁이나 CPU 경쟁이 심할수록 처리량이 줄어들 수 있다
• 리소스(노드) 파편화 감소
Job packing 능력 증가
파편화되면 같은 Job에 대해 물리 노드 활용도가 줄어들게 된다.
• 비사용 리소스(노드) 증가
클라우드 환경에서 전력 소비 감소
같은 Job에 대해 10개의 물리 노드에 전원을 켤 것이냐, 20개의 물리 노드에 전
원을 켤 것이냐 (Thruput, Fragmentation과 충돌할 수 있다)
11
11.
작업 및 리소스모델
• 리소스 (Machine) 모델
CPU
Memory
Disk
12
• Job 모델
Task들의 집합
Task 속성들
1. Cpu, disk, memory,
precedence, priority 등등
2. 지속 시간
3. 기타 제약 사항들
• affinity (장애 고려 등), hw
dependency (GPU,
network bandwidth 등), …
12.
스케줄링 방식 고려사항
•스케줄러 구조 : single scheduler or multi-level scheduler
(예) Mesos는 2-level 스케줄러 사용
• 스케줄링 자원 단위 : node 단위 혹은 cluster 단위
• 작업 특성별 고려 two types : long running & on-demand
(한시적, 배치 job 등)
• 스코어링 알고리즘
13
13.
일반적인 스케줄링 알고리즘
•작업 t가 주어졌을 때 리소스(머신) r을 선택하는 스케줄링
1. t를 운영 가능한 가용 리소스를 filtering 해낸다.
2. filter된 리소스들별로 각각 스케줄링 점수 score(r, t)를 계산한다.
(예) free_mem_pct(r, t) = (t 스케줄링 후의 r의 예상 free
mem) / (r의 전체 mem)
마찬가지로 free_cpu_pct(r, t), free_disk_pct(r, t) 등 계산 가능
3. 가장 점수가 낮은 리소스에게 작업을 할당한다. (best-fit, 다음 참고)
14
14.
단일 score 스케줄링알고리즘
• Best-fit : 필요한 공간을 가진 머신들 중 가장 가용 공간이 작은 (가장 딱 맞는)
머신에 job을 할당
(예) score(i,j) = free_ram_pct(i) + free_cpu_pct(i)
• First-fit : 충분히 큰 공간을 가진 첫번째 머신에 job을 할당
• Worst-fit : 가장 큰 가용 공간을 가진 머신에 job을 할당
(예) score(i,j) = - (10free_ram_pct(i) + 10free_cpu_pct(i) +
10free_disk_pct(i))
• Random : 필요한 공간을 가진 머신들 중 무작위 할당
• 그외 단일 머신이 아닌 유사 리소스 상태를 가진 머신들을 그룹핑하는 알고리즘
15
15.
Multi-resource scoring 알고리즘
•하나의 점수로 만들어 비교하지 않고 여러 개
의 점수를 서로 비교하여 스케줄하는 방식
• DRF : Dominant Resource Fairness
A의 메모리 점유율 = B의 CPU 점유율
Mesos
• Asset Fairness
사용자별 리소스 할당량 총합이 같게
• CEEI (Competitive Equilibrium from
Equal Incomes) : 미시경제학
완전자유경쟁 시장을 가정하기 때문에 완
전 할당을 추구 (과잉 할당 가능성)
16
9 CPU, 18GB Memory
User A 요청 : x*<1 CPU, 4GB>
User B 요청 : y*<3 CPU, 1GB>
6CPU, 2GB
3CPU, 12GB
2.5CPU, 10.1GB
6.5CPU,2.2GB
4.1CPU, 16.4GB
4.9CPU,1.6GB
Cluster Manager
• 자원관리 및 장애 처리의 세부 과정을 감춰서 (자동화해서) 사용자들이 애플리케
이션 개발에 집중할 수 있도록 해준다
• 매우 높은 신뢰성과 가용성으로 운영하며 애플리케이션이 같은 능력을 제공할 수
있도록 지원해준다.
• 수만의 기계에 걸친 작업 부하를 효율적으로 운용할 수 있게 해준다
약간의 활용도 개선이 엄청난 비용 절감을 가져온다.
• Operator별 관리 노드 수 Scaling이 중요 (operator scale-out이라고 부
름. 구글은 운영자 1명이 수만 노드 이상 관리)
19
18.
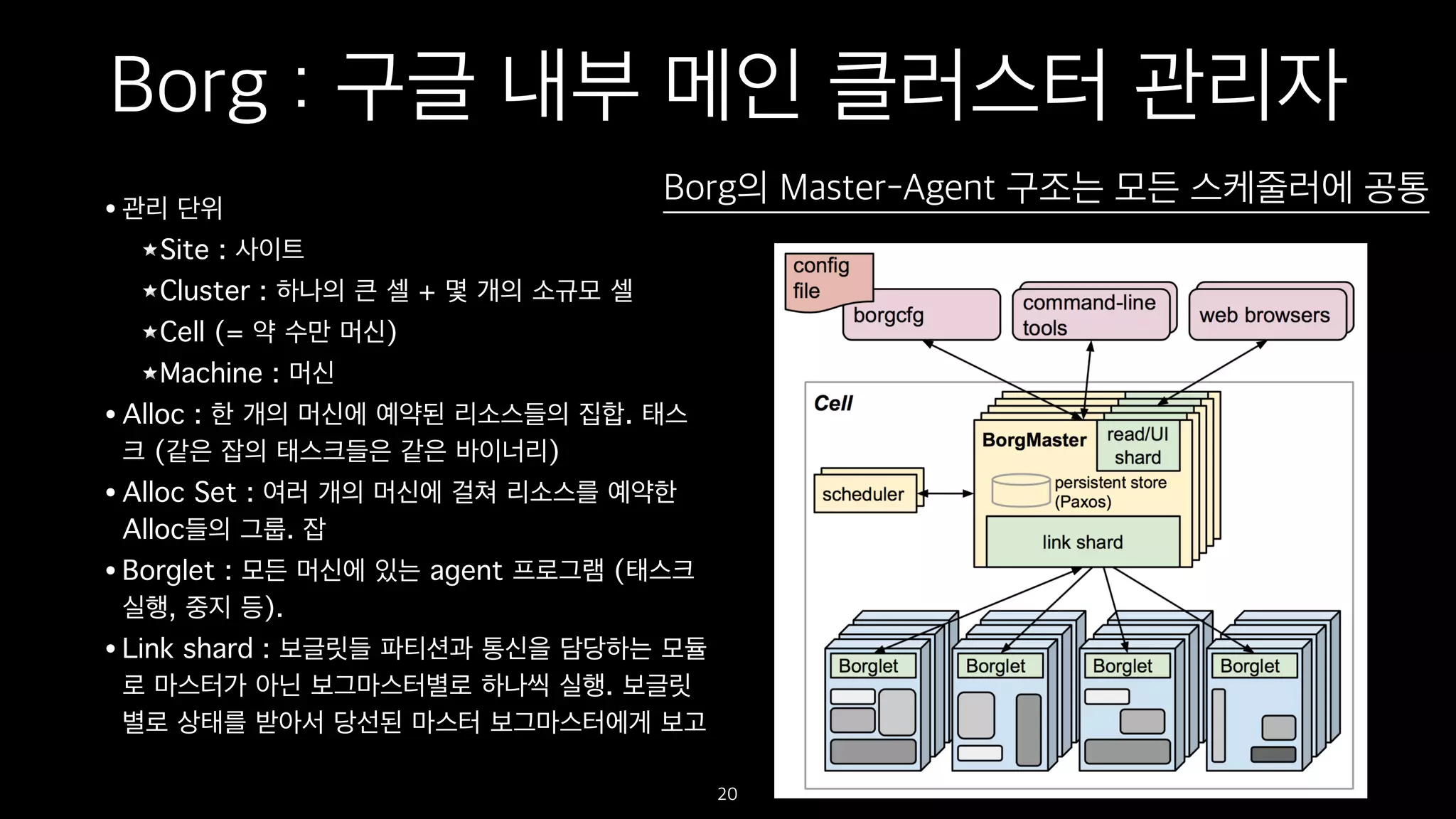
Borg : 구글내부 메인 클러스터 관리자
• 관리 단위
Site : 사이트
Cluster : 하나의 큰 셀 + 몇 개의 소규모 셀
Cell (= 약 수만 머신)
Machine : 머신
• Alloc : 한 개의 머신에 예약된 리소스들의 집합. 태스
크 (같은 잡의 태스크들은 같은 바이너리)
• Alloc Set : 여러 개의 머신에 걸쳐 리소스를 예약한
Alloc들의 그룹. 잡
• Borglet : 모든 머신에 있는 agent 프로그램 (태스크
실행, 중지 등).
• Link shard : 보글릿들 파티션과 통신을 담당하는 모듈
로 마스터가 아닌 보그마스터별로 하나씩 실행. 보글릿
별로 상태를 받아서 당선된 마스터 보그마스터에게 보고
20
Borg의 Master-Agent 구조는 모든 스케줄러에 공통
19.
Borg (2)
• 요청에따른 스케줄링 (뒤에 설명할 Mesos는 가용 리소스가 제공될 때 스케줄링)
• Job workload 성격 분류
long running services : 항상 실행 중이어야 하는 서비스. 보통 한번 할당되면 다운될 때까지 사용되는 경
향
batch jobs : 수시로 실행되는 경향. 단기적인 fluctuation에 영향을 덜 받음
• 머신 속성
CPU, RAM, disk, network, processor type, performance, external IP address, flash storage
• 구글 내부 사용인 부분이 고려
Borg는 VM 가상화를 사용하지 않음. 내부니까 불필요한 자원 낭비 안함.
스케줄 스코어링 시에 priority, quota, acl 등을 사용하여 DRF와 같은 복잡도를 회피
1. 초기에는 worst fit(E-PVM)을 사용했으나 프래그멘테이션, 전력 사용이 증가하는 문제.
2. best fit은 tight하게 스케줄링하는 것이나 예측에 오류가 있으면 곤란. (bursty load에 취약)
3. best fit을 따르되 낭비되는 자원이 최소화되는 방식의 hybrid 방식 사용 중
21
20.
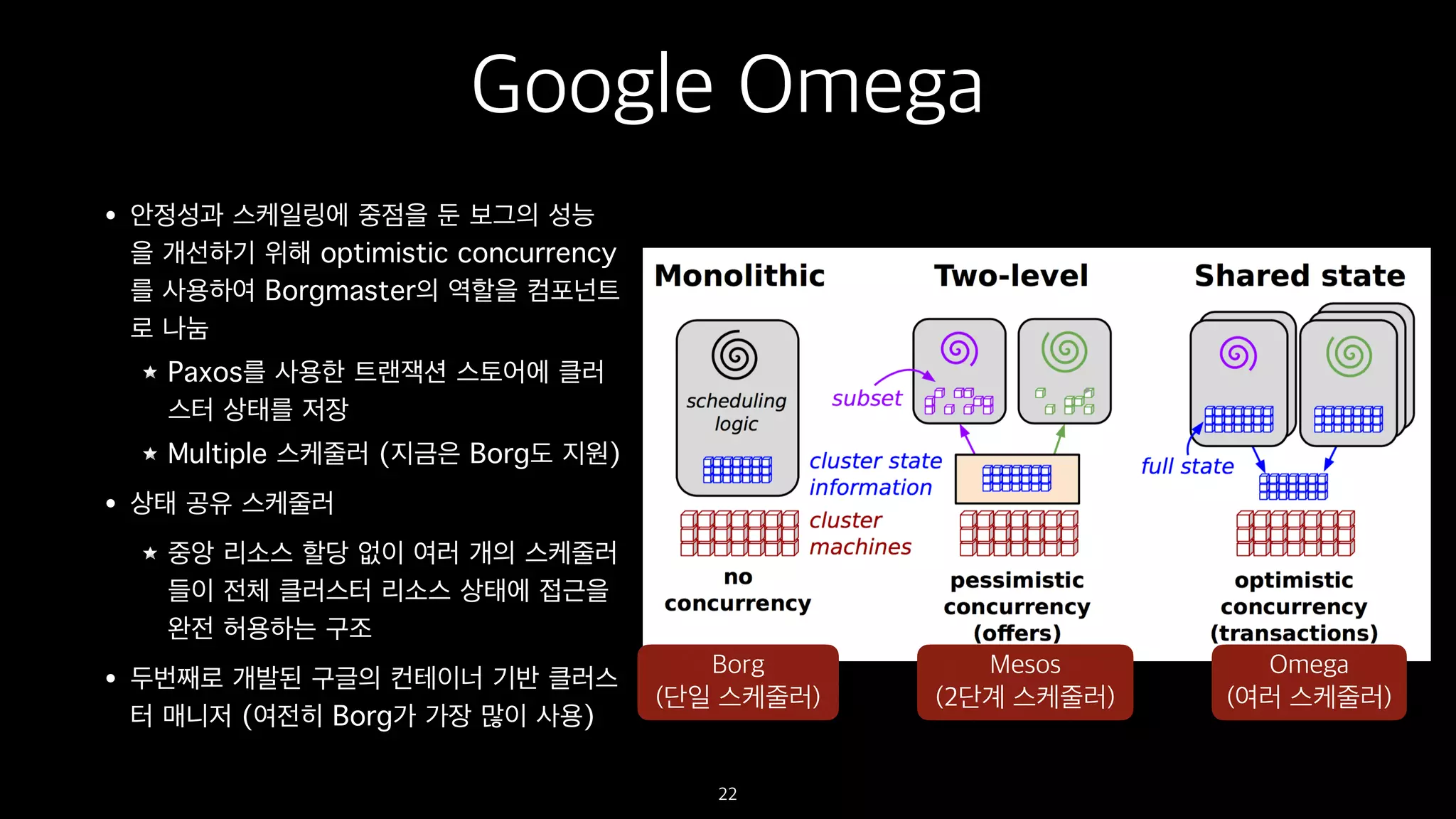
Google Omega
• 안정성과스케일링에 중점을 둔 보그의 성능
을 개선하기 위해 optimistic concurrency
를 사용하여 Borgmaster의 역할을 컴포넌트
로 나눔
Paxos를 사용한 트랜잭션 스토어에 클러
스터 상태를 저장
Multiple 스케줄러 (지금은 Borg도 지원)
• 상태 공유 스케줄러
중앙 리소스 할당 없이 여러 개의 스케줄러
들이 전체 클러스터 리소스 상태에 접근을
완전 허용하는 구조
• 두번째로 개발된 구글의 컨테이너 기반 클러스
터 매니저 (여전히 Borg가 가장 많이 사용)
22
Borg
(단일 스케줄러)
Mesos
(2단계 스케줄러)
Omega
(여러 스케줄러)
21.
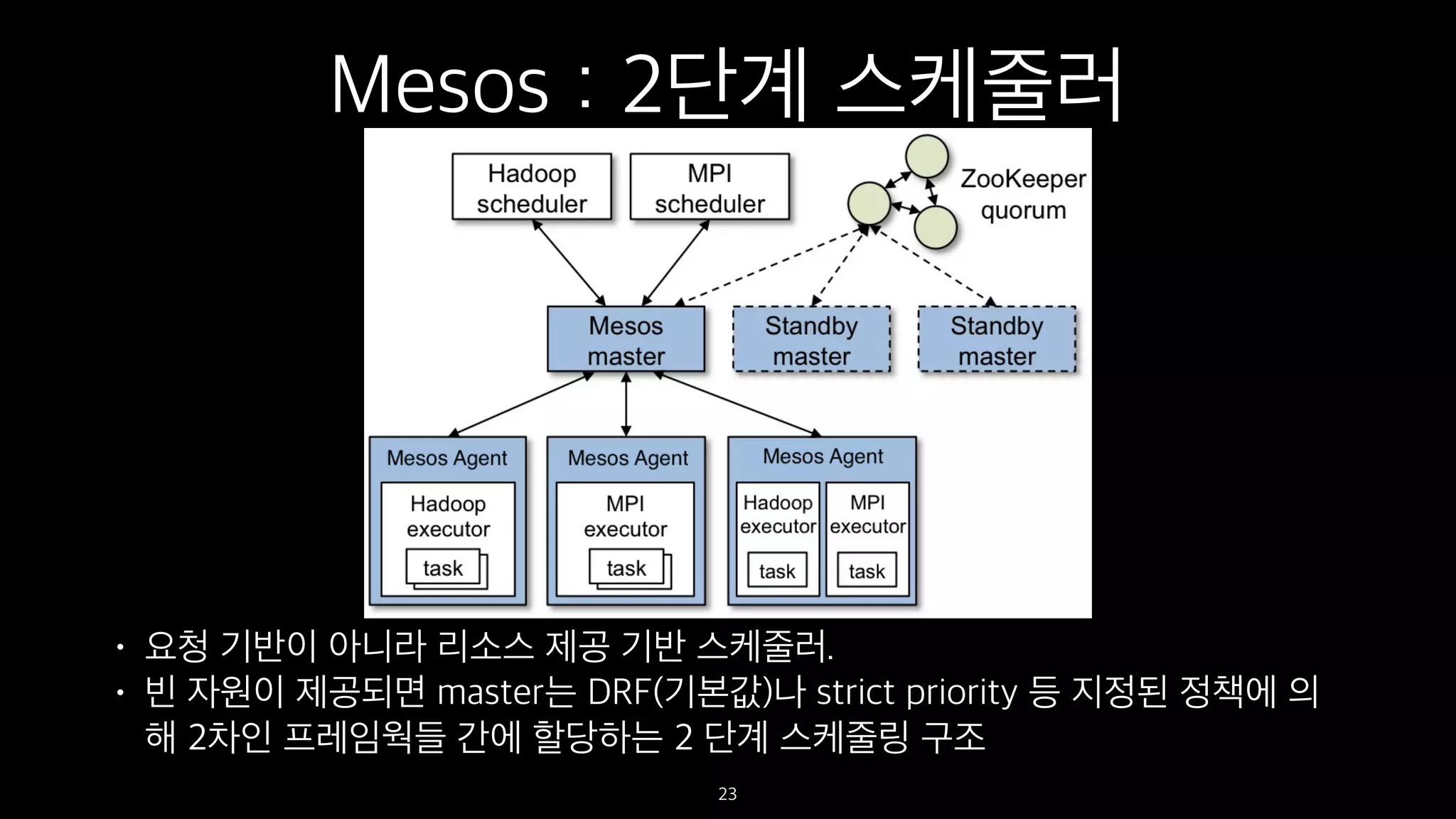
Mesos : 2단계스케줄러
• 요청 기반이 아니라 리소스 제공 기반 스케줄러.
• 빈 자원이 제공되면 master는 DRF(기본값)나 strict priority 등 지정된 정책에 의
해 2차인 프레임웍들 간에 할당하는 2 단계 스케줄링 구조
23
22.
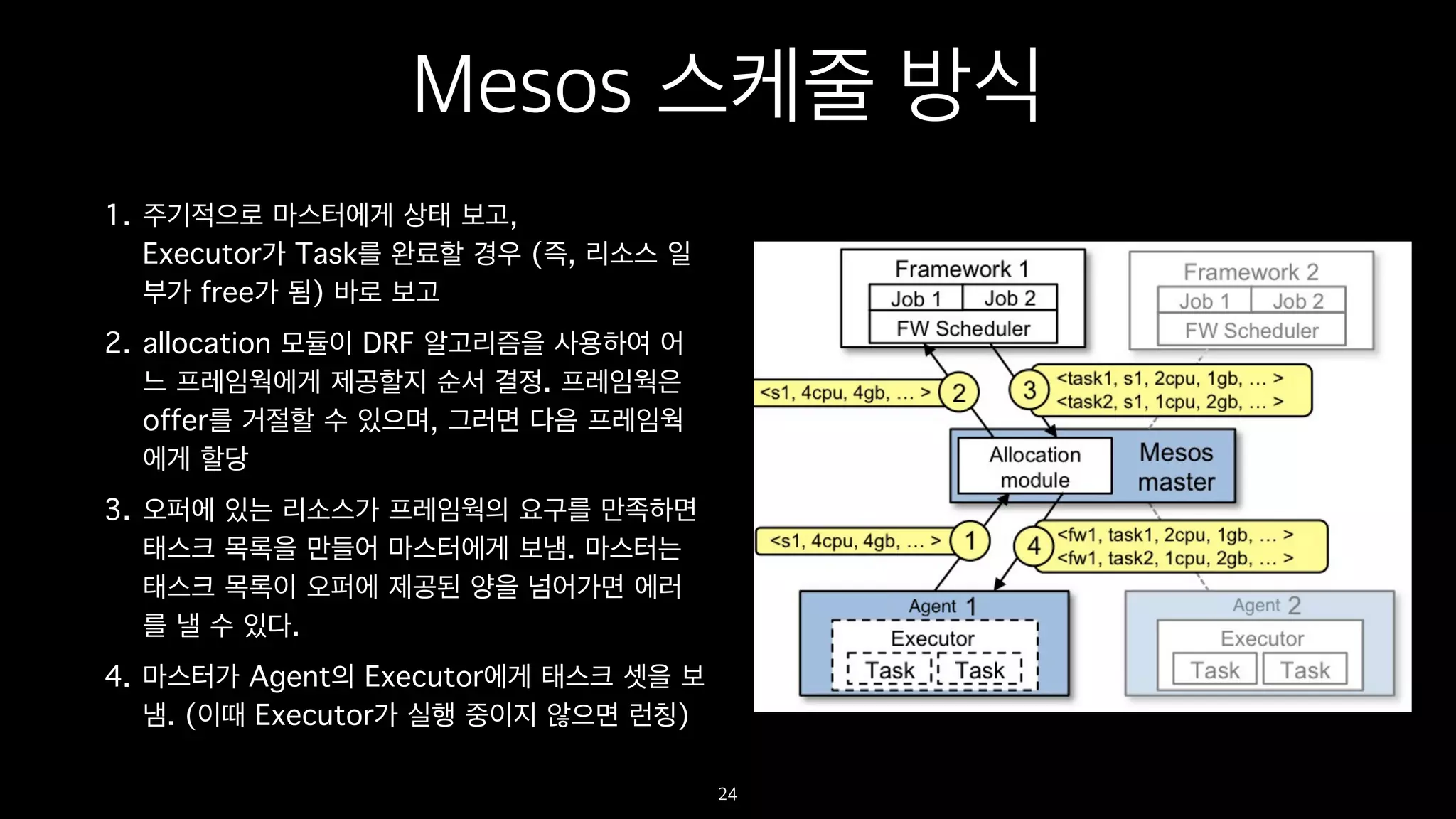
Mesos 스케줄 방식
1.주기적으로 마스터에게 상태 보고,
Executor가 Task를 완료할 경우 (즉, 리소스 일
부가 free가 됨) 바로 보고
2. allocation 모듈이 DRF 알고리즘을 사용하여 어
느 프레임웍에게 제공할지 순서 결정. 프레임웍은
offer를 거절할 수 있으며, 그러면 다음 프레임웍
에게 할당
3. 오퍼에 있는 리소스가 프레임웍의 요구를 만족하면
태스크 목록을 만들어 마스터에게 보냄. 마스터는
태스크 목록이 오퍼에 제공된 양을 넘어가면 에러
를 낼 수 있다.
4. 마스터가 Agent의 Executor에게 태스크 셋을 보
냄. (이때 Executor가 실행 중이지 않으면 런칭)
24
23.
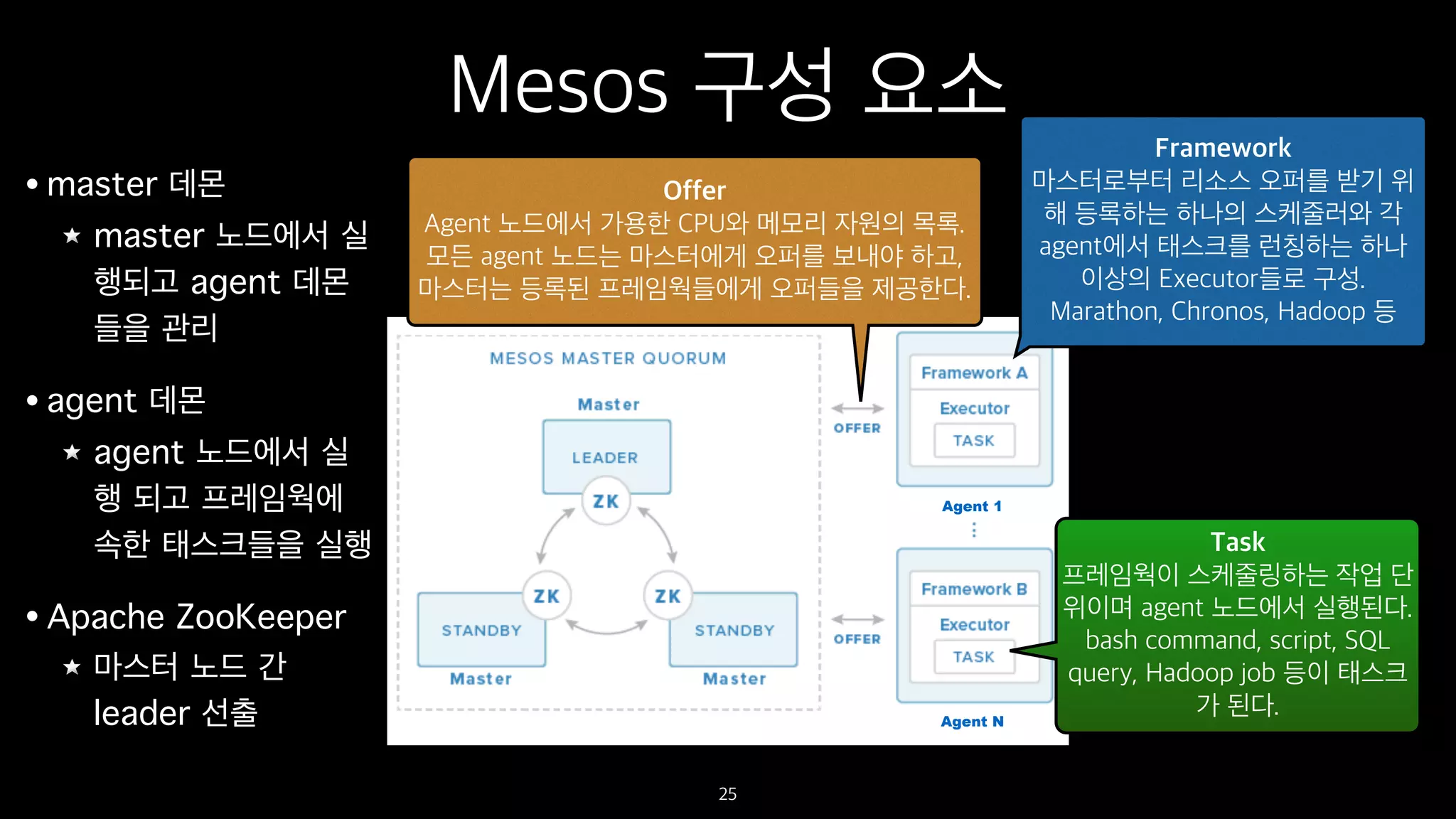
• master 데몬
master노드에서 실
행되고 agent 데몬
들을 관리
• agent 데몬
agent 노드에서 실
행 되고 프레임웍에
속한 태스크들을 실행
• Apache ZooKeeper
마스터 노드 간
leader 선출
Mesos 구성 요소
25
Agent 1
Agent N
Framework
마스터로부터 리소스 오퍼를 받기 위
해 등록하는 하나의 스케줄러와 각
agent에서 태스크를 런칭하는 하나
이상의 Executor들로 구성.
Marathon, Chronos, Hadoop 등
Offer
Agent 노드에서 가용한 CPU와 메모리 자원의 목록.
모든 agent 노드는 마스터에게 오퍼를 보내야 하고,
마스터는 등록된 프레임웍들에게 오퍼들을 제공한다.
Task
프레임웍이 스케줄링하는 작업 단
위이며 agent 노드에서 실행된다.
bash command, script, SQL
query, Hadoop job 등이 태스크
가 된다.
Kubernetes
• Borg, Omega에이어 세번째로 개발된 구글의 컨테이너 기반 클러스터 매니저
• Mesos가 Job을 스케줄하는 반면 Kuberentes는 컨테이너를 스케줄링
• 특징
Shared persistent store (Omega와 유사)
Omega에서는 직접 state에 접근할 수 있지만 k8s에서는 REST API 사용
스케줄 단위가 컨테이너가 아니라 컨테이너의 그룹인 Pod
애플리케이션별로 key-value로 된 메타데이타 정보 지정
(1) apiVersion, (2) kind, (3) metadata, (4) spec 구조
28
26.
Pod
• 쿠버네티스가 스케줄하는최소 단위
• 밀접한 관련이 있는 컨테이너들을 하나로
묶어서 배포하는 개념
(예시) WAS 컨테이너와 WAS 모니터
링 agent 컨테이너
• 포드 단위로 같은 물리 노드에 스케줄
• 포드 안의 컨테이너들 간에는 linux
namespace를 공유 (일반 도커와 다름!)
pod가 OS인 것처럼 착각하게 함
29
YAML : 클라우드의마크업 언어
• Yet Another Markup Language
• Map, List 두 가지 구조를 지원하는 매우
간결한 마크업 언어
• 커멘트, 들여쓰기(TAB 사용 금지), 문자
열 리터럴 지원
• 쿠버네티스 포함 클라우드 환경의 설정에
자주 사용
31
29.
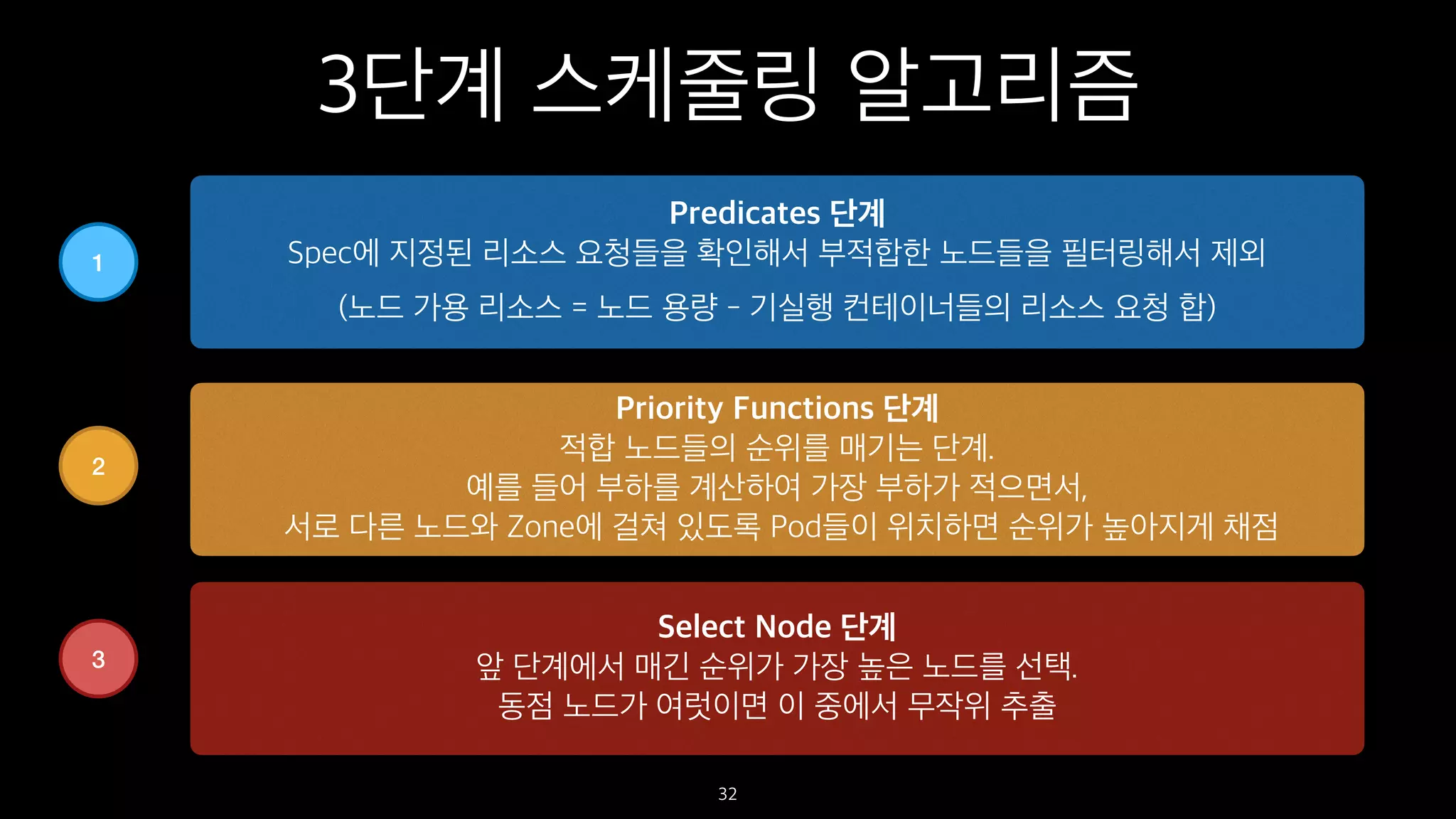
3단계 스케줄링 알고리즘
32
Predicates단계
Spec에 지정된 리소스 요청들을 확인해서 부적합한 노드들을 필터링해서 제외
(노드 가용 리소스 = 노드 용량 - 기실행 컨테이너들의 리소스 요청 합)
1
Priority Functions 단계
적합 노드들의 순위를 매기는 단계.
예를 들어 부하를 계산하여 가장 부하가 적으면서,
서로 다른 노드와 Zone에 걸쳐 있도록 Pod들이 위치하면 순위가 높아지게 채점
2
Select Node 단계
앞 단계에서 매긴 순위가 가장 높은 노드를 선택.
동점 노드가 여럿이면 이 중에서 무작위 추출
3
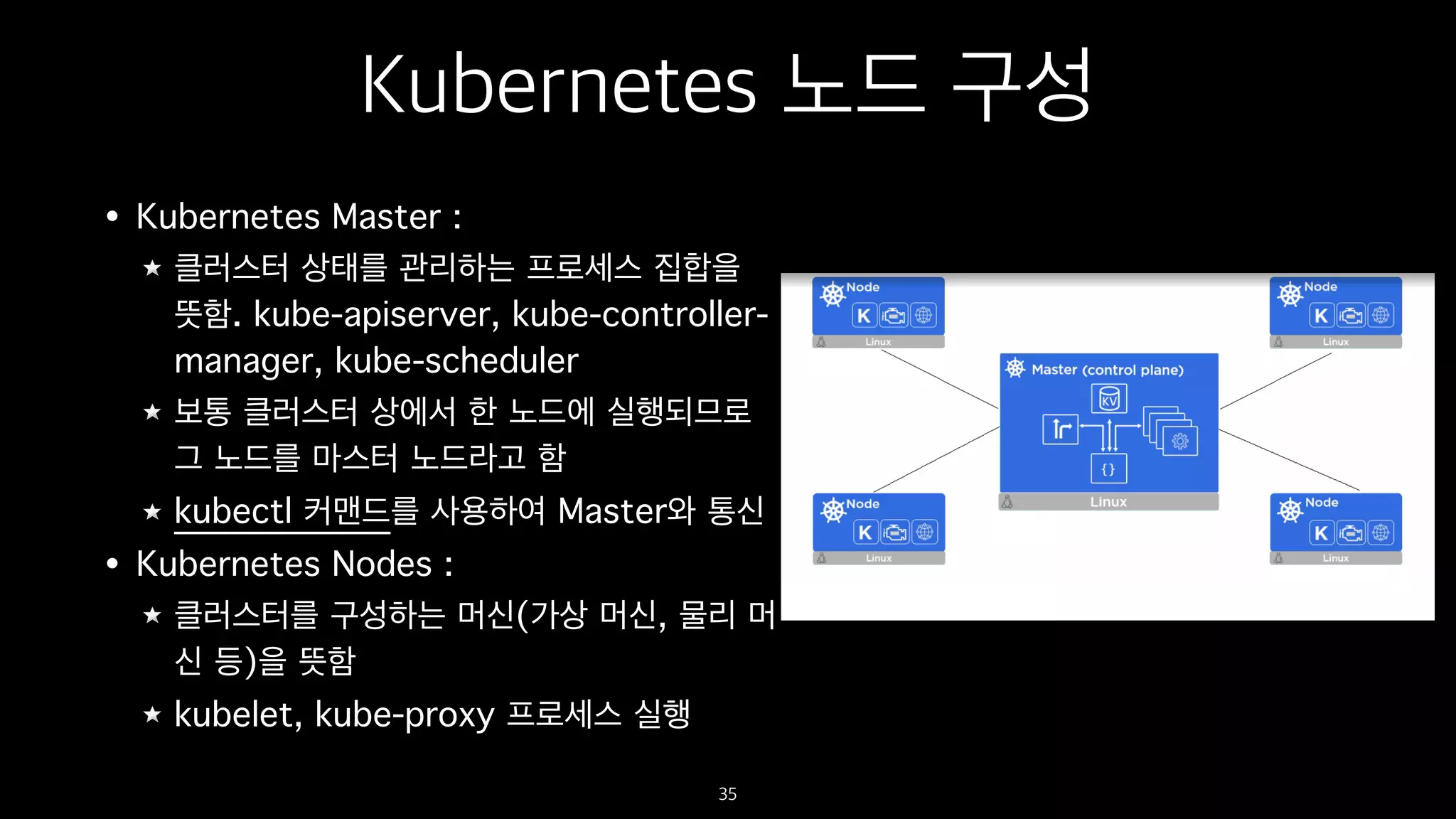
Kubernetes 노드 구성
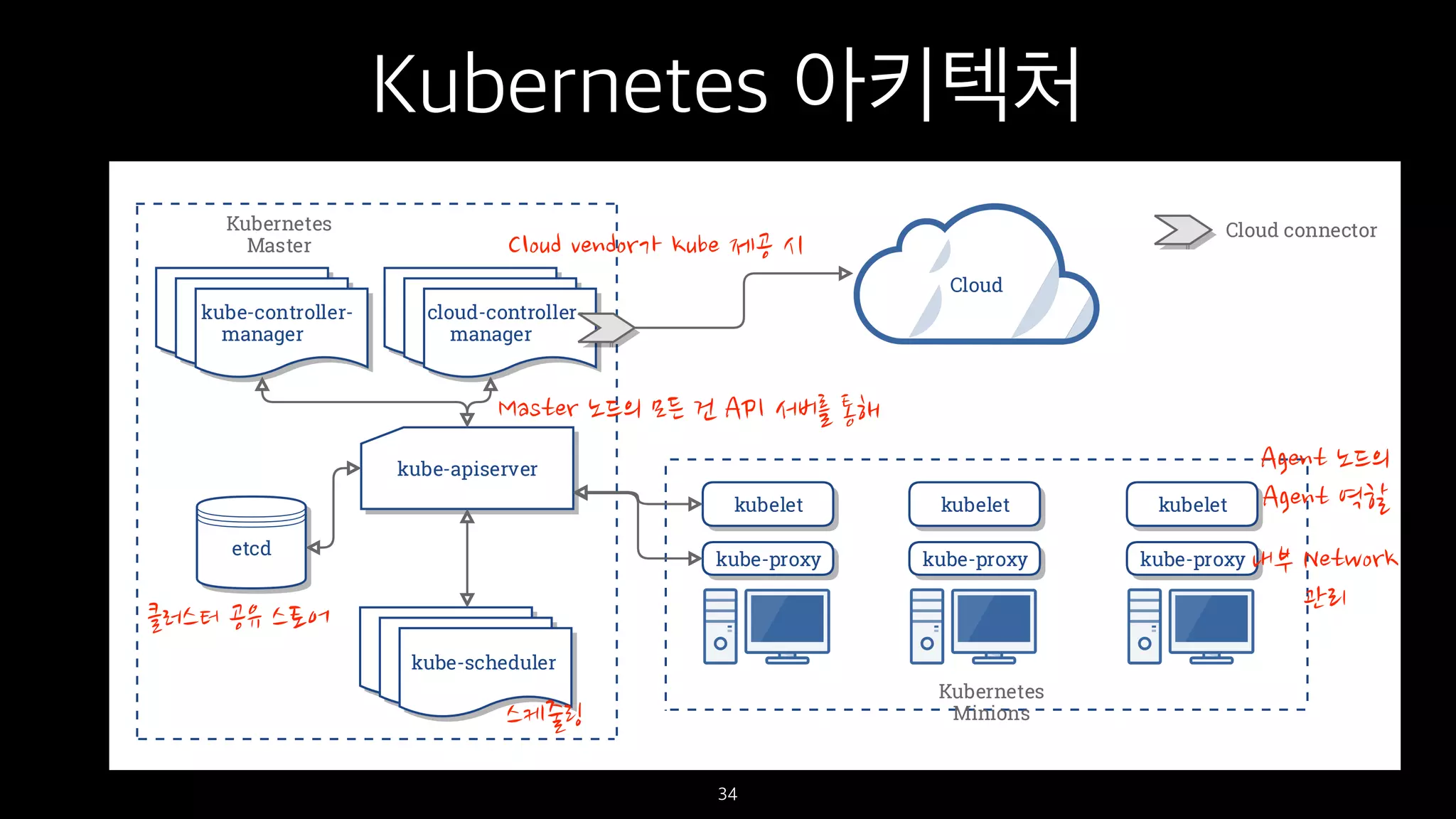
•Kubernetes Master :
클러스터 상태를 관리하는 프로세스 집합을
뜻함. kube-apiserver, kube-controller-
manager, kube-scheduler
보통 클러스터 상에서 한 노드에 실행되므로
그 노드를 마스터 노드라고 함
kubectl 커맨드를 사용하여 Master와 통신
• Kubernetes Nodes :
클러스터를 구성하는 머신(가상 머신, 물리 머
신 등)을 뜻함
kubelet, kube-proxy 프로세스 실행
35
33.
Kubernetes 주요 프로세스
•Kubernetes Master :
kube-apiserver : kubectl의 REST 요청을 처리하는
프로세스
kube-controller-manager : 쿠베의 핵심 제어 로직
을 갖고 있는 데몬 프로세스. 컨트롤러들의 컨트롤러
kube-scheduler : api server가 새로운 pod를 요청하
는지 지켜보다가 클러스터의 특정 노드에 워크로드를 할
당한다.
cluster store (보통 etcd) : 영구 저장소. 분산, 일관
성, 관측성을 제공
• Kubernetes Nodes :
kubelet : 노드마다 있는 쿠베 agent
kube-proxy : 각 pod가 고유 IP를 갖도록 해주고 서비
스의 pod 간 로드밸런싱 등 담당
36
Kubernetes 기본 관리객체
38
Pod
Service
Namespace
Volume
pod는 같은 호스트에 위치한 컨테이너들의 그룹.
같은 Pod의 컨테이너들은 리눅스 네임스페이스를 공유한다.
K8s의 가장 작은 배포 단위.
Pod 단위로 만들고, 스케줄하고 관리한다.
관련된 Pod들 집합의 컨택 포인트 역할을 한다.
서비스는 같이 일하도록 설정된 모든 Pod들로 트래픽을 라우팅
(service proxies).
각 노드에 위치한 kube-proxy가 마스터의 Service, Endpoints
객체 변경을 모니터링하여 proxy-mode를 변경.
Pod들을 구분하는 방법.
서로 다른 네임스페이스의 Pod들은 서비스
디스커버리에 참여할 수 없다.
Pod 단위의 스토리지 볼륨
36.
Pod
• schedule 및scale의 최소 단위
• 컨테이너 하나인 경우와 여럿인 경우
• 컨테이너에 networking과 storage를 제공
ip address. 같은 pod 내의 컨테이너들
은 서로 localhost로 통신 가능
Volumes 사용하여 스토리지 제공
• 여러 개의 pod를 만들고 관리하는 것은 컨트
롤러라고 부름
Deployment, StatefulSet,
DaemonSet 등
39
Cluster
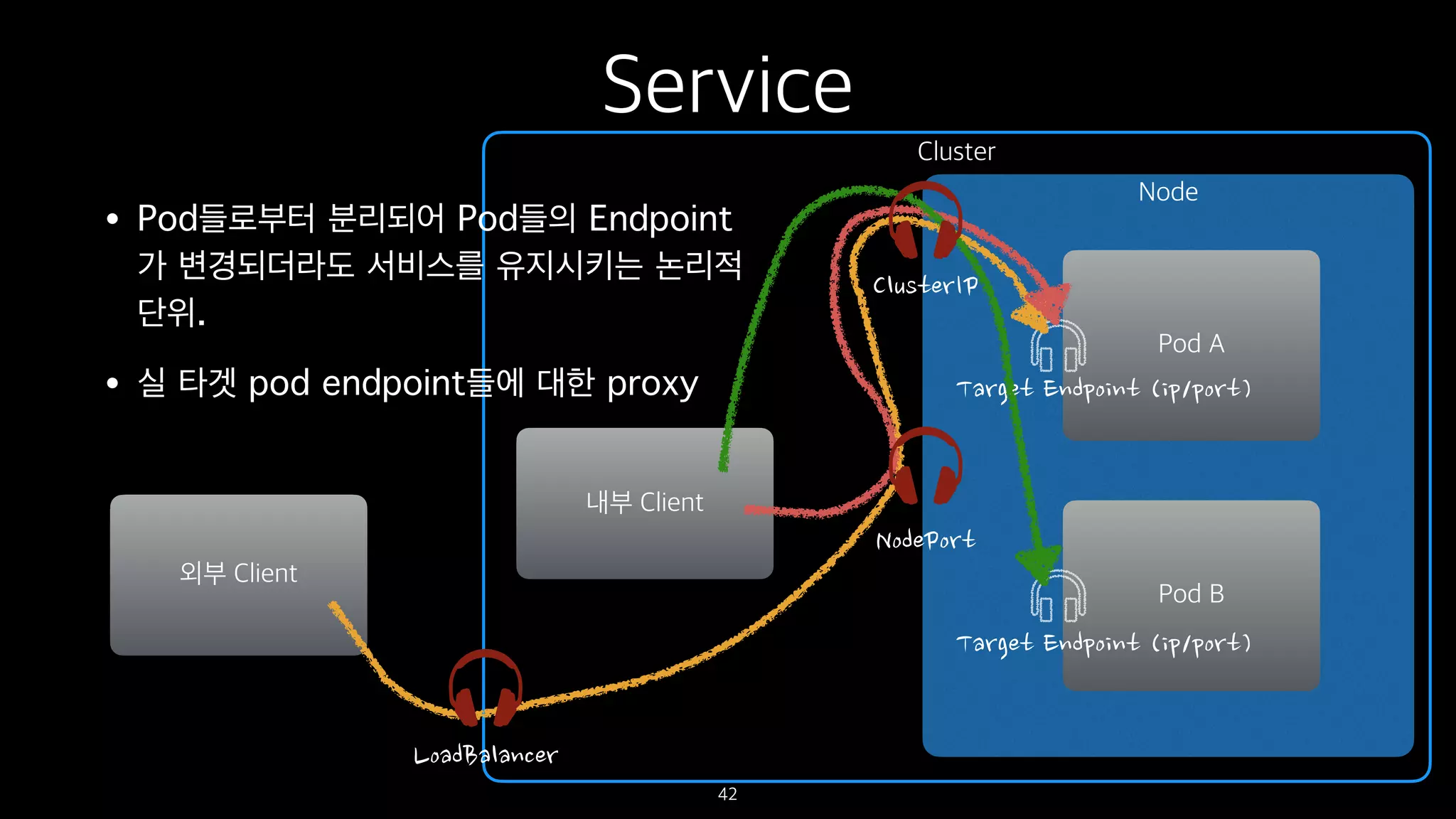
Service
• Pod들로부터 분리되어Pod들의 Endpoint
가 변경되더라도 서비스를 유지시키는 논리적
단위.
• 실 타겟 pod endpoint들에 대한 proxy
42
외부 Client
Node
Pod A
Pod B
내부 Client
40.
Cluster
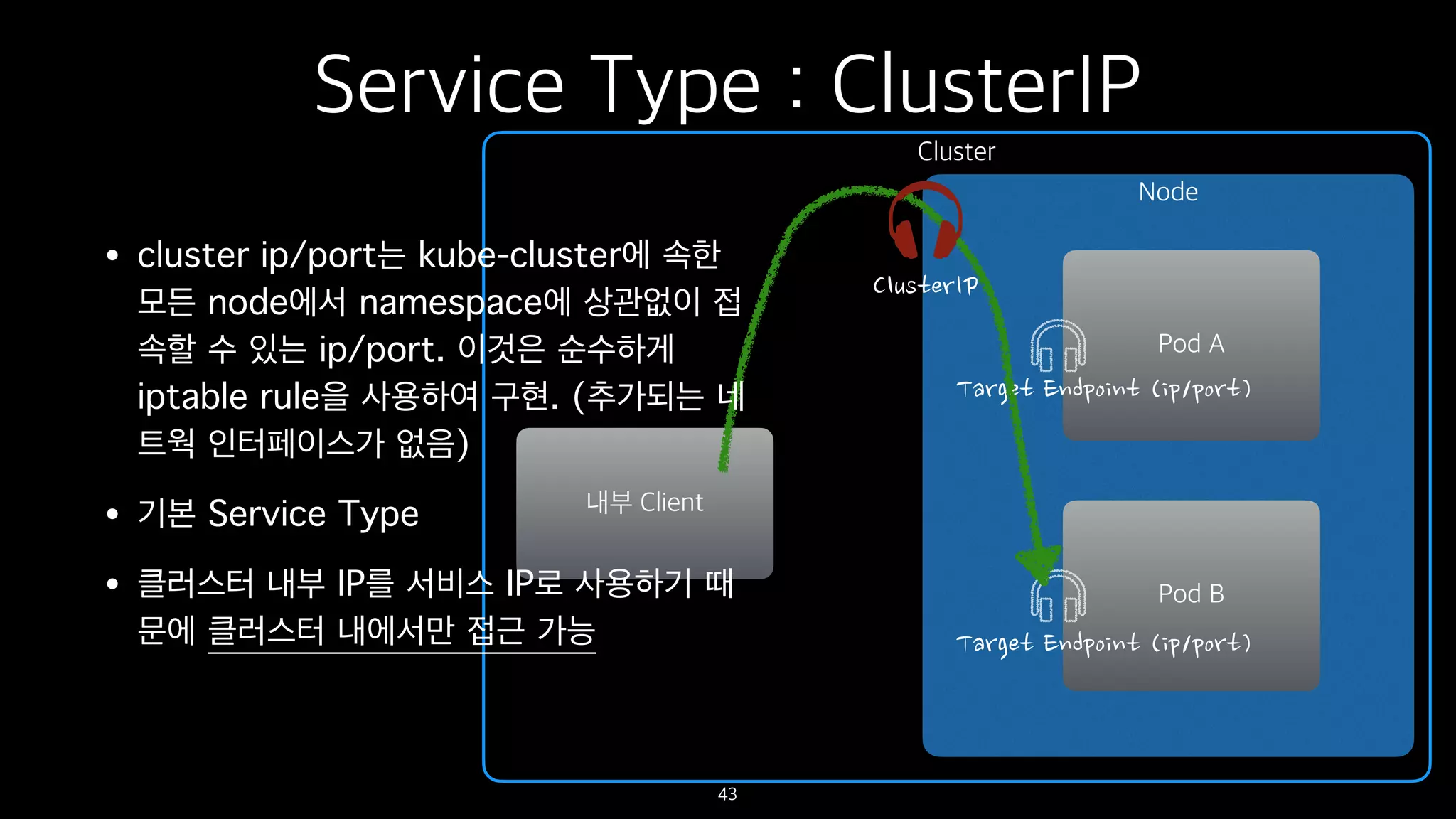
Service Type :ClusterIP
43
Node
Pod A
Pod B
내부 Client
• cluster ip/port는 kube-cluster에 속한
모든 node에서 namespace에 상관없이 접
속할 수 있는 ip/port. 이것은 순수하게
iptable rule을 사용하여 구현. (추가되는 네
트웍 인터페이스가 없음)
• 기본 Service Type
• 클러스터 내부 IP를 서비스 IP로 사용하기 때
문에 클러스터 내에서만 접근 가능
41.
Cluster
Service Type :NodePort
44
외부 Client
Node
Pod A
Pod B
내부 Client
• 서비스를 노드의 특정 고정 port로 노출.
• 내부적으로는 ClusterIP를 자동으로 생성하여 라우팅.
• 외부에서는 <NodeIP>:<NodePort>를 사용하여 접
근 가능. 내부에서만 접근한다면 loopback I/F를 통
해서 접근 가능.
• node port는 kube-cluster에서 namespace에 상관없이 모든 node가 특정 port를 listen하는 형태.
• node의 외부 연결 network interface에서 listen하므로 해당 노드까지 연결할 수 있으면 누구나 접속 가능.
42.
Cluster
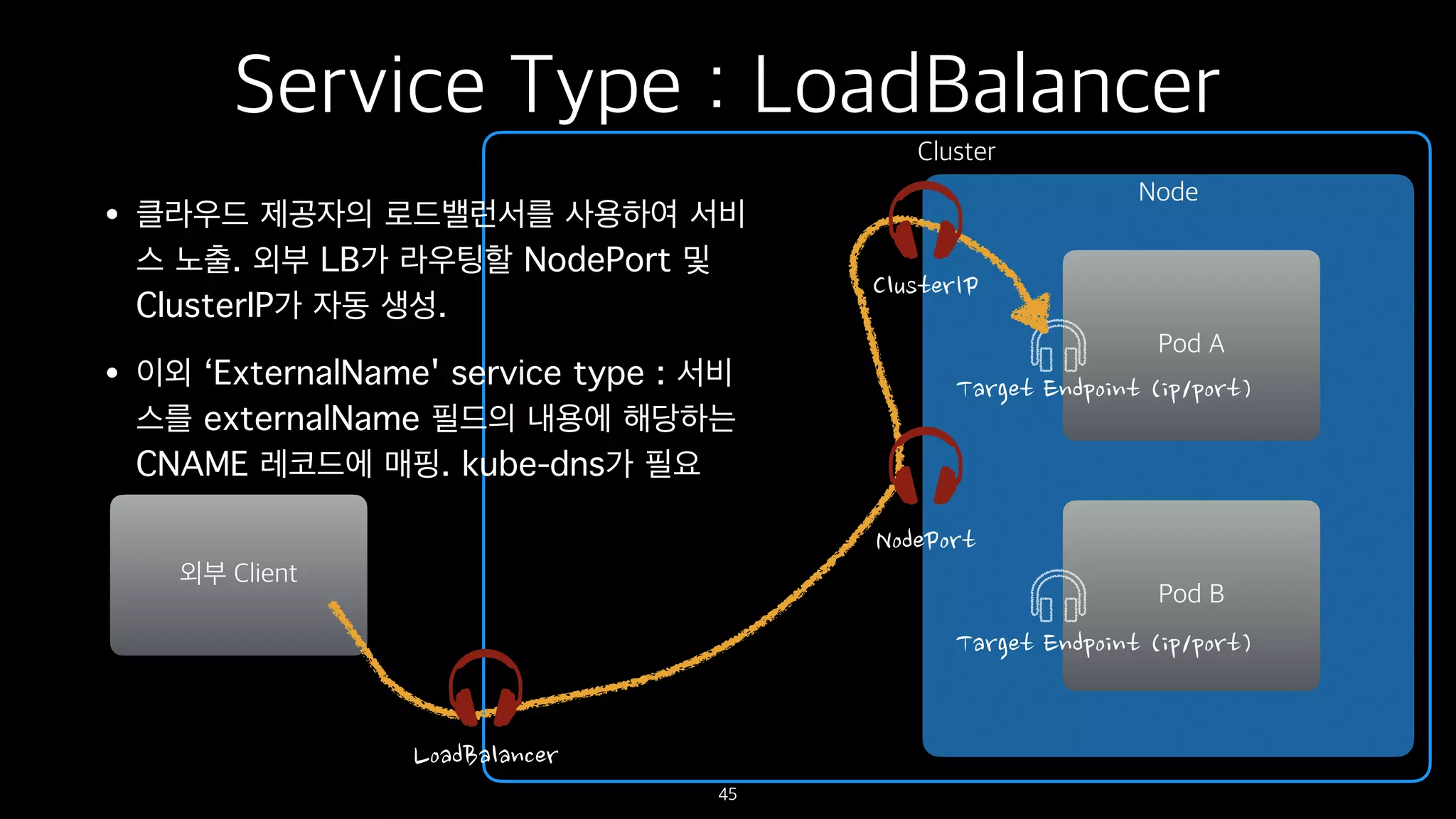
Service Type :LoadBalancer
• 클라우드 제공자의 로드밸런서를 사용하여 서비
스 노출. 외부 LB가 라우팅할 NodePort 및
ClusterIP가 자동 생성.
• 이외 ‘ExternalName' service type : 서비
스를 externalName 필드의 내용에 해당하는
CNAME 레코드에 매핑. kube-dns가 필요
45
외부 Client
Node
Pod A
Pod B
43.
서비스에 사용되는 용어정리
• Cluster IP/Port
cluster ip/port는 kube-cluster에 속한 모든 node에서 namespace에 상관없이 접속할 수 있는 ip/port. 이것은 순
수하게 iptable rule을 사용하여 구현. (추가되는 네트웍 인터페이스가 없음. iptables-save 통해 확인)
• NodePort
node port는 kube-cluster에서 namespace에 상관없이 모든 node가 특정 port를 listen하는 형태. 이것은 실제로
node의 외부 연결 network interface에서 listen하므로 해당 노드까지 연결할 수 있으면 누구나 접속할 수 있음.
• Target Port
target port는 실제 서비스하는 pod(안의 컨테이너 안의 프로세스)가 listen하는 port. 해당하는 pod의 network
namespace 안에서만 listen하고 있는 port이며 pod별로 추가된 가상 네트웍 인터페이스에서 listen하고 있다.
보통 container에서 지정하는 containerPort 중 하나이다.
• 실제 서비스 연결 경로
실제 서비스는 pod의 target port에서 제공하므로 외부에서 들어오는 트래픽은 반드시 서비스 중인 pod가 있는 node
의 node port를 거쳐 해당 pod의 target port로 연결되는 구조이다.
cluster ip이든 external ip이든 node port로 연결된 후 pod target port로 연결.
46
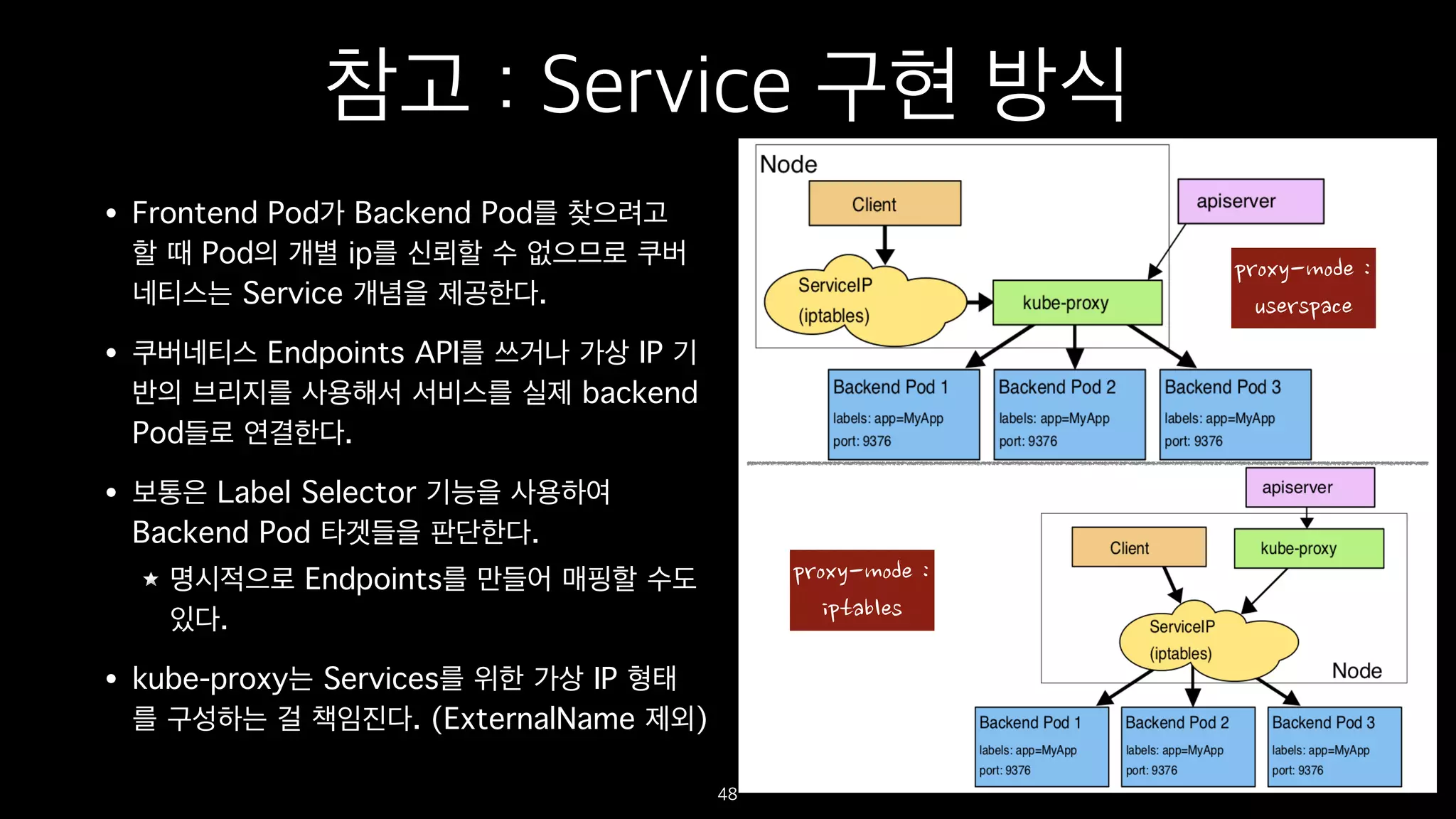
참고 : Service구현 방식
• Frontend Pod가 Backend Pod를 찾으려고
할 때 Pod의 개별 ip를 신뢰할 수 없으므로 쿠버
네티스는 Service 개념을 제공한다.
• 쿠버네티스 Endpoints API를 쓰거나 가상 IP 기
반의 브리지를 사용해서 서비스를 실제 backend
Pod들로 연결한다.
• 보통은 Label Selector 기능을 사용하여
Backend Pod 타겟들을 판단한다.
명시적으로 Endpoints를 만들어 매핑할 수도
있다.
• kube-proxy는 Services를 위한 가상 IP 형태
를 구성하는 걸 책임진다. (ExternalName 제외)
48
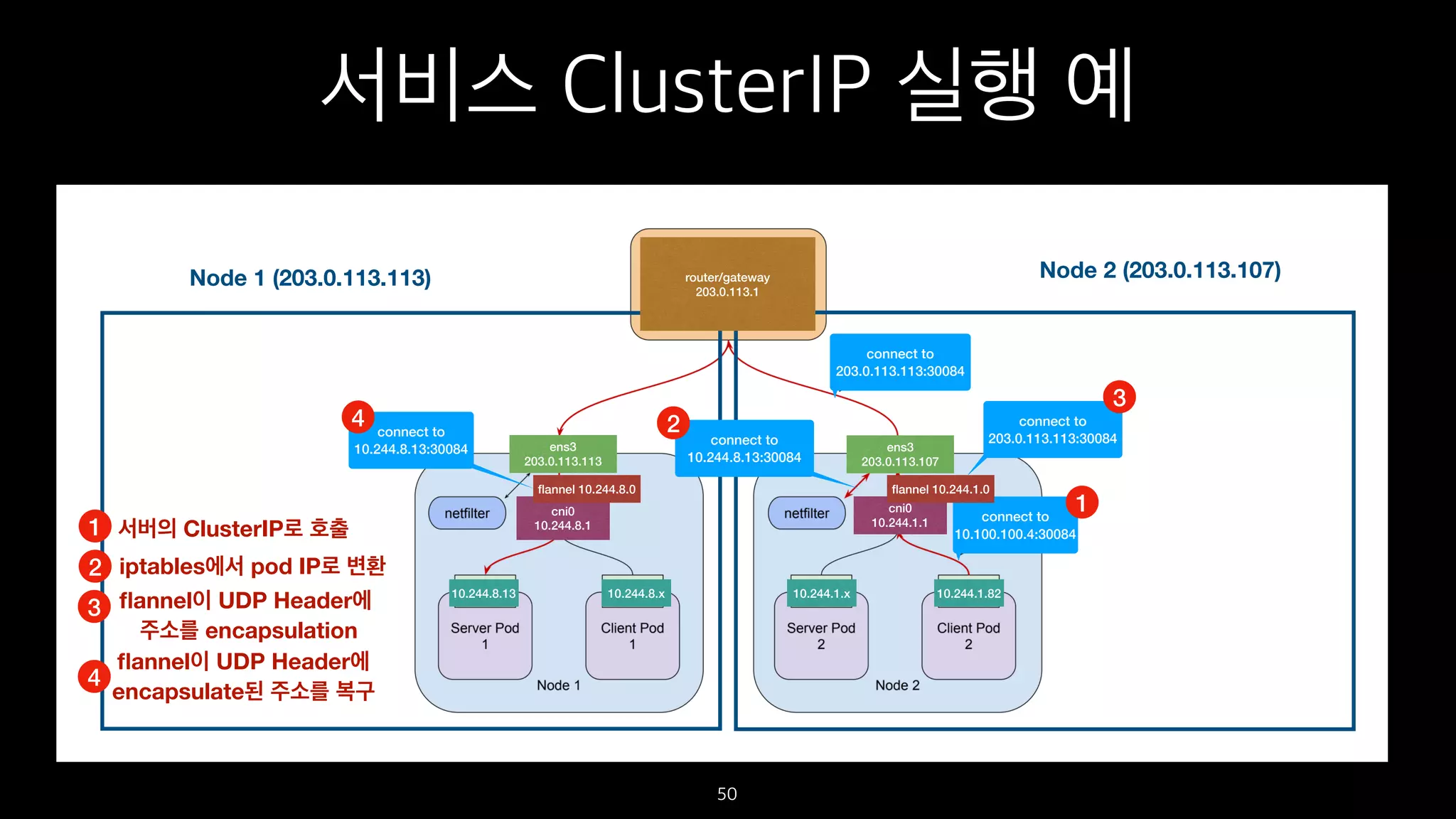
서비스 ClusterIP 실행예
50
10.244.1.82
connect to
10.100.100.4:30084
ens3
203.0.113.107
cni0
10.244.1.1
10.244.8.13
connect to
203.0.113.113:30084
connect to
10.244.8.13:30084 ens3
203.0.113.113
10.244.1.x10.244.8.x
cni0
10.244.8.1
connect to
203.0.113.113:30084
1
3
flannel 10.244.1.0flannel 10.244.8.0
4
Node 2 (203.0.113.107)router/gateway
203.0.113.1
connect to
10.244.8.13:30084
2
Node 1 (203.0.113.113)
1
2
3
4
서버의 ClusterIP로 호출
iptables에서 pod IP로 변환
flannel이 UDP Header에
주소를 encapsulation
flannel이 UDP Header에
encapsulate된 주소를 복구
48.
Namespace
• 쿠버네티스는 같은물리 클러스터 기반 위
에 다수의 가상 클러스터를 지원하는데 이
들 가상 클러스터를 네임스페이스라고 부름
• 다수의 팀, 프로젝트의 사용자들이 사용하
는 환경에서 사용.
• 같은 네임스페이스 안에서도 리소스를 label
을 사용하여 버전 등은 구분할 수 있음.
• 이름의 범위(scope)를 지정하고 클러스터
리소스를 다수의 사용자들 간에 나누는 방법
(리소스 쿼타)으로 사용
51
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCP
49.
Volume, PersistentVolume
• 컨테이너의디스크 파일은 영속적이지 않고, 또
Pod 내에서 컨테이너들 간에 파일을 공유할 필요
가 종종 있다.
이 문제에 대한 쿠버네티스의 해법이
Volume
• 쿠버네티스 Volume의 라이프타임은 Pod의 라
이프타임과 같다
• Volume은 기본적으로는 디렉토리
• 각 Pod 설정에서 .spec.volumes
와 .spec.containers.volumeMounts를 지정
• 유사하지만 영속적인 볼륨으로
PersistentVolume을 지원
52
awsElasticBlockStore azureDisk azureFile cephfs
configMap csi downwardAPI emptyDir fc flocker
gcePersistentDisk glusterfs hostPath iscsi local nfs
persistentVolumeClaim projected portworxVolume
quobyte rbd scaleIO secret storageos vsphereVolume
지원 Volume types
50.
– HINT: 모든서비스는 이 유형의 서비스로 변환되어야 Target Pod에 접근 가능하다
“쿠버네티스의 서비스 유형에는 ClusterIP, NodePort, LoadBalancer
등이 있다. ClusterIP는 쿠베 클러스터 내에서는 어디서나 접근 가능한 가
상 IP이고, NodePort는 클러스터 내의 모든 노드가 해당 Port를 listen
하고 있는 방식이다.”
Quiz
서비스 Spec을 지정할 때 Type을 지정하지 않으면 어떤 유형으로 서비스
가 만들어질까?
53
Break 4
Kubernetes 컨트롤러
• 컨트롤러는기본 객체(Pod, Service, Namespace, Volume) 위에 만들어지며 추가 기
능이나 편의 기능을 제공한다. 기본 객체를 관리하는 매크로 같은 개념으로 생각할 수 있다.
주로 여러 개의 pod를 만들고 관리하기 위함
55
ReplicaSet Deployment
StatefulSet DaemonSet
Job CronJob
• 지정된 수의 Pod 복제본이 실행되도록 보장 • Pod와 ReplicaSet 변경을 선언적 방식으로 제공
• deployment와 pod set의 스케일링을 관리하며
이 pod들의 순서와 유일성을 보장
• 모든 노드(혹은 일부 노드 그룹)에 특정 Pod를 실행
주로 로그 에이전트 같은 걸 실행할 때 사용.
• Pod와 유사하지만 종료된다. 주로 배치 처리 • 주기에 따라 반복해서 Job을 만든다.
53.
ReplicaSet
• ReplicaSet은 어떤시점에도 지정된 수
의 Pod 복제본이 실행되도록 보장해주는
역할
• ReplicaSet을 직접 사용하기보다는 좀더
고차원의 컨트롤러인 Deployment 사용
을 권장
56
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
app: guestbook
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
ports:
- containerPort: 80
54.
Deployment
• Pod와 ReplicaSet변경을 선언적 방식으로
제공
기존에는 kubectl rolling update 커맨
드를 사용. 선언적 방식이 아닌 커맨드 방식
• kubectl 등을 사용하여 이전 버전으로
rollback 등 가능
Pod 변경은 버전으로 관리하나 scale 등
은 버전으로 관리하지 않음
• kubectl 등을 사용하여 매뉴얼 스케일하거
나 자동 스케일 설정 가능
57
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
55.
StatefulSet
• v1.9부터 안정화(쿠베 현재 버전 1.15)
• deployment와 pod set의 스케일링을 관리하
며 이 pod들의 순서와 유일성을 보장한다.
Deployment와 달리 각 pod는 영속적인 id
를 가지고 있어 같은 spec으로 만들어져도 상
호 교체 가능하지 않다. (id가 다르게 생성)
• 다음 요건들이 있을 경우
고정된 네트웍 식별자가 필요한 경우
고정된 영구 스토리지가 필요한 경우
순차적이며 graceful한 배포와 스케일링
순차적이며 graceful한 삭제와 종료
순차적이며 자동화된 롤링 업데이트
58
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
56.
DaemonSet
• 모든 노드들이한 카피의 Pod를 실행하도록 보장한다.
즉, 클러스터에 노드가 추가되면 Pod가 노드에 추가되
고 클러스터에서 노드가 빠지면 Pod도 해당 노드에서 가
비지 컬렉트된다.
DaemonSet을 삭제하면 이로 인해 생성된 Pod들
이 제거된다.
• 다음 요건들이 있을 경우
glusterd, ceph 등과 같은 클러스터 스토리지 데몬
을 모든 노드에 띄우고자 할 경우
fluentd나 logstash 같은 로그 수집 데몬을 모든
노드에 띄우고자 할 경우
프로메테우스 Node Exporter인 collectd나
DataDog agent, Ganglia gmond 등과 같은 노
드 모니터링 데몬을 모든 노드에 띄우고자 할 경우
59
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: k8s.gcr.io/fluentd-elasticsearch:1.20
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
57.
Job
• 하나 이상의Pod를 생성하고 지정한 수만큼
의 Pod가 성공적으로 종료하는 것을 보장한
다. Job은 성공적 완료 여부를 추적하여 지정
한 갯수만큼의 성공적인 완료에 도달하면
Job 자체도 완료된다.
Job을 삭제하면 이로 인해 생성된 Pod들
도 제거된다.
• 복수 개의 Pod를 병렬 실행하는 데에도 사용
될 수 있다.
• 다음 요건들이 있을 경우
일정 갯수의 배치를 일회성으로 실행할 때
60
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-
wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
58.
CronJob
• Cron 형식의스케줄 정보에 따라 주기적
으로 job을 실행
• 다음 요건들이 있을 경우
주기적으로 실행해야 하는 배치성 작업
61
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes
cluster
restartPolicy: OnFailure
kubectl command
• kubernetes의master 노드와 통신하는 데 사용되는 command
• minikube에서는 kubectl 명령을 통해 VM 안의 kube master 노드와 통신할 수 있다.
kubectl run hello-minikube --image=k8s.gcr.io/echoserver:1.10 —port=8080
kubectl get pods
kubectl get pods —all-namespaces
kubectl get deployments -o wide
kubectl get deployments -o json
64
62.
– Martine Lothblatt
“Anythingworthwhile in life requires teamwork,
and you cannot manage what you don’t understand”
65




























![Pod spec 예제
40
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo Hello Kubernetes! && sleep 3600']](https://image.slidesharecdn.com/techforum-kubernetes201907-200601080516/75/Kubernetes-37-2048.jpg)









![ReplicaSet
• ReplicaSet은 어떤 시점에도 지정된 수
의 Pod 복제본이 실행되도록 보장해주는
역할
• ReplicaSet을 직접 사용하기보다는 좀더
고차원의 컨트롤러인 Deployment 사용
을 권장
56
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
app: guestbook
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
ports:
- containerPort: 80](https://image.slidesharecdn.com/techforum-kubernetes201907-200601080516/75/Kubernetes-53-2048.jpg)

![StatefulSet
• v1.9부터 안정화 (쿠베 현재 버전 1.15)
• deployment와 pod set의 스케일링을 관리하
며 이 pod들의 순서와 유일성을 보장한다.
Deployment와 달리 각 pod는 영속적인 id
를 가지고 있어 같은 spec으로 만들어져도 상
호 교체 가능하지 않다. (id가 다르게 생성)
• 다음 요건들이 있을 경우
고정된 네트웍 식별자가 필요한 경우
고정된 영구 스토리지가 필요한 경우
순차적이며 graceful한 배포와 스케일링
순차적이며 graceful한 삭제와 종료
순차적이며 자동화된 롤링 업데이트
58
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi](https://image.slidesharecdn.com/techforum-kubernetes201907-200601080516/75/Kubernetes-55-2048.jpg)

![Job
• 하나 이상의 Pod를 생성하고 지정한 수만큼
의 Pod가 성공적으로 종료하는 것을 보장한
다. Job은 성공적 완료 여부를 추적하여 지정
한 갯수만큼의 성공적인 완료에 도달하면
Job 자체도 완료된다.
Job을 삭제하면 이로 인해 생성된 Pod들
도 제거된다.
• 복수 개의 Pod를 병렬 실행하는 데에도 사용
될 수 있다.
• 다음 요건들이 있을 경우
일정 갯수의 배치를 일회성으로 실행할 때
60
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-
wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4](https://image.slidesharecdn.com/techforum-kubernetes201907-200601080516/75/Kubernetes-57-2048.jpg)







![[오픈소스컨설팅]클라우드자동화 및 운영효율화방안](https://cdn.slidesharecdn.com/ss_thumbnails/random-140217215646-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











![[오픈소스컨설팅]Tomcat6&7 How To](https://cdn.slidesharecdn.com/ss_thumbnails/tomcat67-130206051107-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[발표자료] 오픈소스 기반 클라우드 네이티브 애플리케이션 구축 방안 (feat. Kubernetes)](https://cdn.slidesharecdn.com/ss_thumbnails/kubernetes-241219083038-3bd08c9d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[오픈소스컨설팅] Ansible을 활용한 운영 자동화 교육](https://cdn.slidesharecdn.com/ss_thumbnails/ansibleautomationv1-190221013416-thumbnail.jpg?width=640&height=640&fit=bounds)






![[2019.04] 쿠버네티스 기반 하이퍼레저 패브릭 네트워크 구축하기](https://cdn.slidesharecdn.com/ss_thumbnails/hyperledgerfabriconk8s-190418042054-thumbnail.jpg?width=640&height=640&fit=bounds)

![[OpenInfra Days Korea 2018] Day 2 - E5: Mesos to Kubernetes, Cloud Native 서비스...](https://cdn.slidesharecdn.com/ss_thumbnails/e60930openinfraday2018dennis-180705030830-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]쿠버네티스를 활용한 개발환경 구축](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsutingkubernetesv0-191010000815-thumbnail.jpg?width=640&height=640&fit=bounds)


![[넥슨] kubernetes 소개 (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/gcdkubernetes-190419130148-thumbnail.jpg?width=640&height=640&fit=bounds)





![[NDC17] Kubernetes로 개발서버 간단히 찍어내기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-170529041601-thumbnail.jpg?width=640&height=640&fit=bounds)
















