Downloaded 18 times




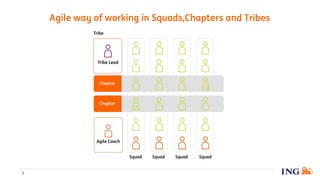



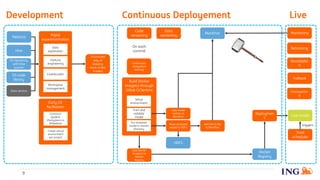
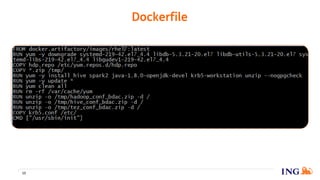
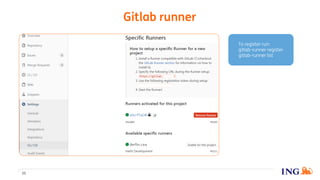





The document discusses the implementation of a data science pipeline using Docker at the ING Dataworks Summit. It explains Docker's role in creating, deploying, and running applications in containers, ensuring consistent environments across different systems. The presentation highlights an agile workflow in data science, detailed processes for pipeline management, and considerations for using GitLab and Jenkins for CI/CD in data science projects.






















































































