Download to read offline

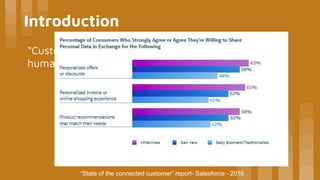






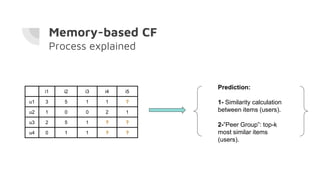

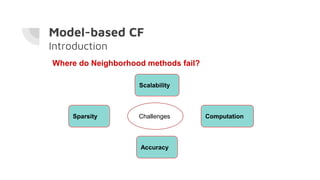


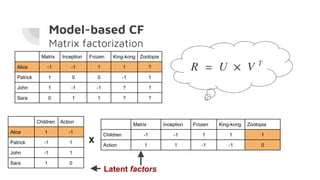
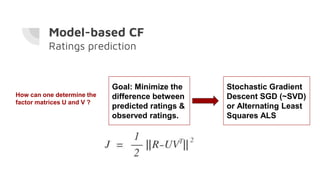










This document discusses building a recommender system using collaborative filtering. It begins with an introduction to collaborative filtering and common methods like memory-based and model-based collaborative filtering. It then explains the process for memory-based collaborative filtering including similarity calculation, determining peer groups, and making recommendations. Model-based collaborative filtering is introduced using matrix factorization to predict ratings. The document concludes with the steps to build a recommender system which includes understanding data, pre-processing, building the collaborative filtering model, training and testing the model, and evaluating accuracy.








![[Final]collaborative filtering and recommender systems](https://cdn.slidesharecdn.com/ss_thumbnails/finalcollaborativefilteringandrecommendersystems-141103044224-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































