Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
harmonylab
PPTX, PDF
4,799 views
Playing Atari with Six Neurons
Playing Atari with Six Neurons の紹介
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 20
2
/ 20
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
8
/ 20
9
/ 20
10
/ 20
11
/ 20
12
/ 20
13
/ 20
14
/ 20
15
/ 20
16
/ 20
17
/ 20
18
/ 20
19
/ 20
20
/ 20
More Related Content
PDF
Trainable Calibration Measures for Neural Networks from Kernel Mean Embeddings
by
harmonylab
PDF
Top-K Off-Policy Correction for a REINFORCE Recommender System
by
harmonylab
PPTX
Invariant Information Clustering for Unsupervised Image Classification and Se...
by
harmonylab
PDF
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
PDF
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised L...
by
harmonylab
PDF
A PID Controller Approach for Stochastic Optimization of Deep Networks
by
harmonylab
PPTX
Mutual Mean-Teaching:Pseudo Label Refinery for Unsupervised Domain Adaption o...
by
harmonylab
PPTX
Can increasing input dimensionality improve deep reinforcement learning?
by
harmonylab
Trainable Calibration Measures for Neural Networks from Kernel Mean Embeddings
by
harmonylab
Top-K Off-Policy Correction for a REINFORCE Recommender System
by
harmonylab
Invariant Information Clustering for Unsupervised Image Classification and Se...
by
harmonylab
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised L...
by
harmonylab
A PID Controller Approach for Stochastic Optimization of Deep Networks
by
harmonylab
Mutual Mean-Teaching:Pseudo Label Refinery for Unsupervised Domain Adaption o...
by
harmonylab
Can increasing input dimensionality improve deep reinforcement learning?
by
harmonylab
What's hot
PDF
NVIDIA Seminar ディープラーニングによる画像認識と応用事例
by
Takayoshi Yamashita
PDF
効率的学習 / Efficient Training(メタサーベイ)
by
cvpaper. challenge
PDF
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
PPTX
Globally and Locally Consistent Image Completion
by
harmonylab
PPTX
Mobilenet
by
harmonylab
PPTX
Variational Template Machine for Data-to-Text Generation
by
harmonylab
PDF
Capsule Graph Neural Network
by
harmonylab
PPTX
[DLゼミ] Learning agile and dynamic motor skills for legged robots
by
harmonylab
PPTX
Predictron
by
harmonylab
PPTX
2021 09 29_dl_hirata
by
harmonylab
PPTX
How Much Position Information Do Convolutional Neural Networks Encode?
by
Kazuyuki Miyazawa
PDF
Real-Time Semantic Stereo Matching
by
harmonylab
PPTX
2020 08 05_dl_DETR
by
harmonylab
PPTX
Generating Better Search Engine Text Advertisements with Deep Reinforcement L...
by
harmonylab
PDF
DeepVIO: Self-supervised Deep Learning of Monocular Visual Inertial Odometry ...
by
harmonylab
PPTX
Learning to summarize from human feedback
by
harmonylab
PPTX
Bayesian Uncertainty Estimation for Batch Normalized Deep Networks
by
harmonylab
PDF
190602 benchmarking neural network robustness to common corruptions and pertu...
by
亮宏 藤井
PPTX
Differential Networks for Visual Question Answering
by
harmonylab
PPTX
PredCNN: Predictive Learning with Cascade Convolutions
by
harmonylab
NVIDIA Seminar ディープラーニングによる画像認識と応用事例
by
Takayoshi Yamashita
効率的学習 / Efficient Training(メタサーベイ)
by
cvpaper. challenge
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
Globally and Locally Consistent Image Completion
by
harmonylab
Mobilenet
by
harmonylab
Variational Template Machine for Data-to-Text Generation
by
harmonylab
Capsule Graph Neural Network
by
harmonylab
[DLゼミ] Learning agile and dynamic motor skills for legged robots
by
harmonylab
Predictron
by
harmonylab
2021 09 29_dl_hirata
by
harmonylab
How Much Position Information Do Convolutional Neural Networks Encode?
by
Kazuyuki Miyazawa
Real-Time Semantic Stereo Matching
by
harmonylab
2020 08 05_dl_DETR
by
harmonylab
Generating Better Search Engine Text Advertisements with Deep Reinforcement L...
by
harmonylab
DeepVIO: Self-supervised Deep Learning of Monocular Visual Inertial Odometry ...
by
harmonylab
Learning to summarize from human feedback
by
harmonylab
Bayesian Uncertainty Estimation for Batch Normalized Deep Networks
by
harmonylab
190602 benchmarking neural network robustness to common corruptions and pertu...
by
亮宏 藤井
Differential Networks for Visual Question Answering
by
harmonylab
PredCNN: Predictive Learning with Cascade Convolutions
by
harmonylab
Similar to Playing Atari with Six Neurons
PPTX
Paper intoduction "Playing Atari with deep reinforcement learning"
by
Hiroshi Tsukahara
PDF
人工知能とゲーム(前篇)
by
Youichiro Miyake
PPTX
ゲームAIと人工生命
by
Youichiro Miyake
PDF
博士論文本審査スライド
by
Ryuichi Ueda
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
PDF
ゲームAI入門(前半)
by
Youichiro Miyake
PDF
ROS User Group Meeting #28 マルチ深層学習とROS
by
Hiroki Nakahara
PDF
デジタルゲームの調整・デバッグ・品質管理 における人工知能技術の応用
by
Youichiro Miyake
PDF
[DL輪読会]Making Sense of Vision and Touch: Self-Supervised Learning of Multimod...
by
Deep Learning JP
PDF
ゲームAIから見るAIの実情と未来
by
Youichiro Miyake
PDF
実社会・実環境におけるロボットの機械学習 ver. 2
by
Kuniyuki Takahashi
PPTX
勉強会用スライド
by
harmonylab
PPTX
A Generalist Agent
by
harmonylab
PDF
あめとむちで知能を作る!? ーニューラルネットを使ったEnd to-End強化学習と「思考」の創発に向けたカオスNN強化学習ー
by
Katsunari Shibata
PDF
"Playing Atari with Deep Reinforcement Learning"
by
mooopan
PDF
20180830 implement dqn_platinum_data_meetup_vol1
by
Keisuke Nakata
PDF
人工知能とDX
by
Youichiro Miyake
PDF
Raspberry Pi Deep Learning Hand-on
by
Yoshihiro Ochi
PPTX
LUT-Network Revision2
by
ryuz88
PDF
デジタルゲームにおける品質保証のための人工知能
by
Youichiro Miyake
Paper intoduction "Playing Atari with deep reinforcement learning"
by
Hiroshi Tsukahara
人工知能とゲーム(前篇)
by
Youichiro Miyake
ゲームAIと人工生命
by
Youichiro Miyake
博士論文本審査スライド
by
Ryuichi Ueda
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
ゲームAI入門(前半)
by
Youichiro Miyake
ROS User Group Meeting #28 マルチ深層学習とROS
by
Hiroki Nakahara
デジタルゲームの調整・デバッグ・品質管理 における人工知能技術の応用
by
Youichiro Miyake
[DL輪読会]Making Sense of Vision and Touch: Self-Supervised Learning of Multimod...
by
Deep Learning JP
ゲームAIから見るAIの実情と未来
by
Youichiro Miyake
実社会・実環境におけるロボットの機械学習 ver. 2
by
Kuniyuki Takahashi
勉強会用スライド
by
harmonylab
A Generalist Agent
by
harmonylab
あめとむちで知能を作る!? ーニューラルネットを使ったEnd to-End強化学習と「思考」の創発に向けたカオスNN強化学習ー
by
Katsunari Shibata
"Playing Atari with Deep Reinforcement Learning"
by
mooopan
20180830 implement dqn_platinum_data_meetup_vol1
by
Keisuke Nakata
人工知能とDX
by
Youichiro Miyake
Raspberry Pi Deep Learning Hand-on
by
Yoshihiro Ochi
LUT-Network Revision2
by
ryuz88
デジタルゲームにおける品質保証のための人工知能
by
Youichiro Miyake
More from harmonylab
PDF
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Lea...
by
harmonylab
PDF
Mixture-of-Personas Language Models for Population Simulation
by
harmonylab
PDF
Mixture-of-Personas Language Models for Population Simulation
by
harmonylab
PDF
Encoding and Controlling Global Semantics for Long-form Video Question Answering
by
harmonylab
PDF
Data Scaling Laws for End-to-End Autonomous Driving
by
harmonylab
PDF
Efficient anomaly detection in tabular cybersecurity data using large languag...
by
harmonylab
PDF
Can Large Language Models perform Relation-based Argument Mining?
by
harmonylab
PDF
CTINexus: Automatic Cyber Threat Intelligence Knowledge Graph Construction Us...
by
harmonylab
PDF
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
by
harmonylab
PDF
Multiple Object Tracking as ID Prediction
by
harmonylab
PDF
Collaborative Document Simplification Using Multi-Agent Systems
by
harmonylab
PDF
TransitReID: Transit OD Data Collection with Occlusion-Resistant Dynamic Pass...
by
harmonylab
PDF
AECR: Automatic attack technique intelligence extraction based on fine-tuned ...
by
harmonylab
PDF
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
by
harmonylab
PDF
QuASAR: A Question-Driven Structure-Aware Approach for Table-to-Text Generation
by
harmonylab
PDF
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models throu...
by
harmonylab
PDF
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
by
harmonylab
PDF
Towards Scalable Human-aligned Benchmark for Text-guided Image Editing
by
harmonylab
PDF
APT-LLM Embedding-Based Anomaly Detection of Cyber Advanced Persistent Threat...
by
harmonylab
PDF
【卒業論文】LLMを用いたMulti-Agent-Debateにおける反論の効果に関する研究
by
harmonylab
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Lea...
by
harmonylab
Mixture-of-Personas Language Models for Population Simulation
by
harmonylab
Mixture-of-Personas Language Models for Population Simulation
by
harmonylab
Encoding and Controlling Global Semantics for Long-form Video Question Answering
by
harmonylab
Data Scaling Laws for End-to-End Autonomous Driving
by
harmonylab
Efficient anomaly detection in tabular cybersecurity data using large languag...
by
harmonylab
Can Large Language Models perform Relation-based Argument Mining?
by
harmonylab
CTINexus: Automatic Cyber Threat Intelligence Knowledge Graph Construction Us...
by
harmonylab
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
by
harmonylab
Multiple Object Tracking as ID Prediction
by
harmonylab
Collaborative Document Simplification Using Multi-Agent Systems
by
harmonylab
TransitReID: Transit OD Data Collection with Occlusion-Resistant Dynamic Pass...
by
harmonylab
AECR: Automatic attack technique intelligence extraction based on fine-tuned ...
by
harmonylab
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
by
harmonylab
QuASAR: A Question-Driven Structure-Aware Approach for Table-to-Text Generation
by
harmonylab
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models throu...
by
harmonylab
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
by
harmonylab
Towards Scalable Human-aligned Benchmark for Text-guided Image Editing
by
harmonylab
APT-LLM Embedding-Based Anomaly Detection of Cyber Advanced Persistent Threat...
by
harmonylab
【卒業論文】LLMを用いたMulti-Agent-Debateにおける反論の効果に関する研究
by
harmonylab
Recently uploaded
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
Playing Atari with Six Neurons
1.
0 Playing Atari with
Six Neurons 調和系工学研究室 幡本昂平 2019/7/5
2.
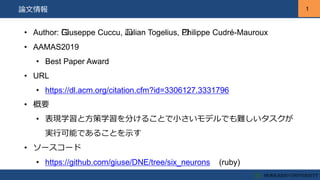
1 1論文情報 • Author: Giuseppe
Cuccu, Julian Togelius, Philippe Cudré-Mauroux • AAMAS2019 • Best Paper Award • URL • https://dl.acm.org/citation.cfm?id=3306127.3331796 • 概要 • 表現学習と方策学習を分けることで小さいモデルでも難しいタスクが 実行可能であることを示す • ソースコード • https://github.com/giuse/DNE/tree/six_neurons (ruby)
3.
2 2背景 深層強化学習では高次元の入力(画像など)を直接的に行動へ変換 • ネットワーク中では入力を内部表現に変換し,それを行動に変換している • 方策が内部表現と同時に学習されている 表現学習と方策学習を分けることで各コンポーネントの高度化が実現可能 •
小さいネットワークで方策学習が行えるようになる • ネットワークの複雑性がどのように正確な方策の表現に寄与するかへの理解が深まる 方策と特徴量を同時かつ別々に学習する方法を提案 • IDVQとDRSCによって達成 • IDVQ: 観測空間のcentroidを保持 • DRSC: 観測のコンパクトなコード化 提案手法
4.
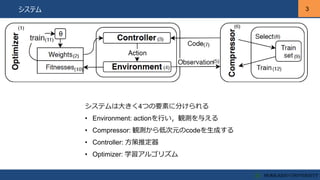
3 3システム システムは大きく4つの要素に分けられる • Environment: actionを行い,観測を与える •
Compressor: 観測から低次元のcodeを生成する • Controller: 方策推定器 • Optimizer: 学習アルゴリズム
5.
4 4Environment • ALEはAtari2600のエミュレータ上に構築されている • 観測は[210
× 180 × 3]のRGB画像 • ネットワークからの出力は18の離散的なactionになる • ジョイスティックからの入力を表現 • フレームスキップは5で固定 • 入力後,4フレームは何も入力せず5フレーム目を学習などに使う ☓はスキップするフレーム https://danieltakeshi.github.io/2016/11/25/frame-skipping-and-preprocessing-for-deep-q-networks-on-atari-2600-games/ Atari2600のジョイスティック https://ja.wikipedia.org/wiki/Atari_2600 フレームスキップ4の例 OpenAI GymフレームワークのArcade Learning Environment(ALE) で実験
6.
5 5Compressor 役割: ニューラルネットが意思決定に集中できるように観測のコンパクトな表現を出力する オンライン学習のように観測そのものからの教師なし学習をすることによって実現可能 • Increasing
Dictionary Vector Quantization • Direct Residuals Sparse Coding 2つのアルゴリズムにより対処
7.
6 6Vanilla Vector Quantization Vector
Quantization: dictionaryベースのエンコードテクニック 代表要素とコードで元の情報を表現する • 代表要素(centroids) 周りの値のreferenceとしてはたらき,k-meansのように周囲の値の代表値となる • コード 各centroidに対応するベクトル 一般的にcentroidに対応する以外の場所の値は0にする もとの情報の再構成(reconstruction)はこれらのベクトル積として与えられる 次元削減や圧縮などに利用される 一般にdictionaryはreconstruction errorを最小化するようなcentroidで構成されるように訓練 再構成ともとの情報の差をreconstruction errorと呼ぶ あつめたものをdictionaryという 今回は元画像が含む情報を全てカバーすることが目標
8.
7 7オンライン強化学習におけるVanilla Vector Quantizationの問題点 •
追加の訓練データが後半ステージまで得られない • 環境とのインタラクションを通じて得られた場合のみアクセス可能 Ex) レベルごとに異なる敵があらわれるAtariのゲーム レベル2の敵の観測はレベル1を解く能力に依存する • レベル1を解くにはレベル1の敵を認識するためのcompressorが必要 小さいdictionaryサイズからはじめて,観測が増えるにつれてサイズを大きくしていく オンライン強化学習への適用を考えるといくつか制約がある dictionaryの更新と候補の解の更新を交互に行う必要がある オンライン学習における2つの相反する要求 • centroidは有用で一貫したコードを出すように訓練される必要がある • 新しい観測に基づく後の段階での訓練には訓練されていない状態のcentroidが必要
9.
8 8Increasing Dictionary VQ 空のdictionaryからはじめて centroidを追加していく 現在のdictionaryで再構成できない部分 に対応するcentroidを追加する 全個体の観測から一様に サンプリングして作成 追加の際には差の合計がしきい値𝛿以上 であることを条件とする dictionaryサイズが増えることでNNへの 入力サイズが変わるので対応する必要がある 意味のないcentroidの追加を防ぐため
10.
9 9Direct Residuals Sparse
Coding 意思決定のために計算時間を削減した Sparse Coding 元情報の再構成ではなく,識別しやすい code作成が目標 • residual imageのcentroidとしての使用 • centroid訓練の必要なし • バイナリエンコーディング • 再構成演算を簡略化 • いくつかのcentroidが選ばれたら終了 • 辞書サイズに対して線形の パフォーマンス 特徴
11.
10 10各アルゴリズムの動作説明 初期化 code: dictionaryと同サイズの0配列 residual information:
元画像 ループ(DRSC) どれだけresidual informationをエンコードできるかを もとにcentroidsを選ぶ residual informationと各centroidを比較して 最も近いcentroidを選ぶ codeの対応する部分を1に residual informationからcentroidを引いて更新
12.
11 11Residual informationの符号 更新されたresidual informationの符号の意味 0:
もとのresidual informationのピクセル情報とcentroidの値が完全に一致 +: 前のresidualでは存在していたが,新しいcentroidでは表現されていない -: 新しいcentroidでは存在しているが,前のresidualにはなかった 大抵の符号化アルゴリズムは未符号化情報と再構成によりうまれた情報を区別しない 再構成した際の誤差を重視しているから 今回は画像情報をすべて表現することだけを目標とするので,負の値の要素は0にする residual imageは元画像にあってまだ取り入れられていない情報となる
13.
12 12コード化とdictionary作成 DRSCはcentroidをresidual informationがしきい値以下になるまで追加しつづける 正しいcentroidがdictionary中にない場合にスパース性を保つため, 一つのcodeにcentroidを追加しすぎた時を終了条件として設定 dictionaryの学習(IDVQ) 新しくできたcentroidを追加する 学習は以上のように • 訓練画像の選択 •
DRSCによるエンコード • dictionaryの作成 の順におこなわれる
14.
13 13Controller 1層 全結合RNN 入力サイズ: compressorの出力サイズ ディクショナリサイズが大きくなるに連れ,入力サイズも大きくなる 増えた入力に対する重みを0にしておくことで,ネットワークの一貫性を保つ 出力サイズ:
各ゲームの行動空間の次元数 ほとんどは18,いくつかは6 行動は最も大きい出力のものが選ばれる
15.
14 14Optimizer Exponential Natural Evolution
Strategy(XNES)の変化系を使用 NES Natural Evolution Strategies パラメータ空間上の分布から個体を生成して最適化をおこなう 分布パラメータ𝜃におけるサンプル𝑧が与えられたときの目的関数値の期待値 を最小化する 自然勾配法により値を更新 XNESでは分布が多変量ガウス分布 𝜃 = (𝜇, ∑) 更新もこれらの値についておこなわれる 自然進化戦略
16.
15 15Optimizerの工夫 XNESにニューラルネットのサイズ変化に対応した工夫を導入 ニューラルネットの重みが0なので0 追加するまでなかったので,他の値との関係はなく0 平均 分散 サイズ増大分のパラメータを追加する 非常に小さい分散
17.
16 16実験設定 • 実行環境: • Intel
Xeon E5-2620 32コア 2.10GHz, 3GB RAM / core • ゲームの実行時間: • 200インタラクション(1000フレーム フレームスキップ5) • XNES: populationサイズ: • デフォルトの1.5倍,学習率:デフォルトの0.5倍 • dictionary growthを制御するパラメータ𝛿: • 0.005 • 解像度: [210 × 180 × 3]を[70 × 80]に削減 • 各チャネルを平均化してグレースケールに • 各個体は5回評価 • 世代数:100 (平均2,3時間)
18.
17 17実験結果1 Atariのゲームのスコア • OpenAI Gymで利用可能 •
観測の解像度が同じ • 3D要素がない 以下の条件を満たすゲームでの結果 他の手法に匹敵する性能 とくにQbertがよくできている
19.
18 18実験結果2 各手法のニューロン数・層数・結合数 表現抽出と意思決定を分離することで小さいリソースで難しい問題を解くことが 可能であると示すこと この論文が示したかったこと 非常に小さいニューロン数・隠れ層数・結合数でAtariのゲームを解くことができている
20.
19 19まとめ • 方策学習と特徴量構築を別々に行い,それぞれの役割に特化した学習をおこなう手法を提案 • 小さいネットワークでも深層ニューラルネットに匹敵する意思決定が行えた •
オーソドックスなend-to-endな手法に疑問を投げかけた
Download


![4
4Environment
• ALEはAtari2600のエミュレータ上に構築されている
• 観測は[210 × 180 × 3]のRGB画像
• ネットワークからの出力は18の離散的なactionになる
• ジョイスティックからの入力を表現
• フレームスキップは5で固定
• 入力後,4フレームは何も入力せず5フレーム目を学習などに使う
☓はスキップするフレーム https://danieltakeshi.github.io/2016/11/25/frame-skipping-and-preprocessing-for-deep-q-networks-on-atari-2600-games/
Atari2600のジョイスティック
https://ja.wikipedia.org/wiki/Atari_2600
フレームスキップ4の例
OpenAI GymフレームワークのArcade Learning Environment(ALE) で実験](https://image.slidesharecdn.com/dl190628-190705062643/85/Playing-Atari-with-Six-Neurons-5-320.jpg)











![16
16実験設定
• 実行環境:
• Intel Xeon E5-2620 32コア 2.10GHz, 3GB RAM / core
• ゲームの実行時間:
• 200インタラクション(1000フレーム フレームスキップ5)
• XNES: populationサイズ:
• デフォルトの1.5倍,学習率:デフォルトの0.5倍
• dictionary growthを制御するパラメータ𝛿:
• 0.005
• 解像度: [210 × 180 × 3]を[70 × 80]に削減
• 各チャネルを平均化してグレースケールに
• 各個体は5回評価
• 世代数:100 (平均2,3時間)](https://image.slidesharecdn.com/dl190628-190705062643/85/Playing-Atari-with-Six-Neurons-17-320.jpg)













![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DLゼミ] Learning agile and dynamic motor skills for legged robots](https://cdn.slidesharecdn.com/ss_thumbnails/20200513dltomoyaodaslideshare-200513093410-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[DL輪読会]Making Sense of Vision and Touch: Self-Supervised Learning of Multimod...](https://cdn.slidesharecdn.com/ss_thumbnails/20190802dl-190808102241-thumbnail.jpg?width=640&height=640&fit=bounds)










































