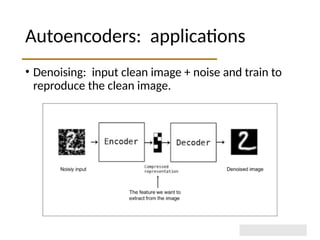
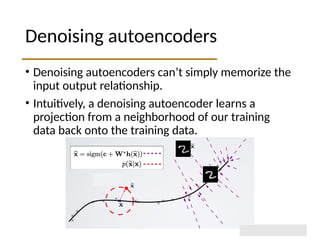
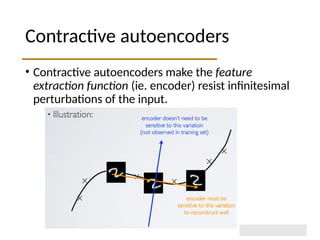
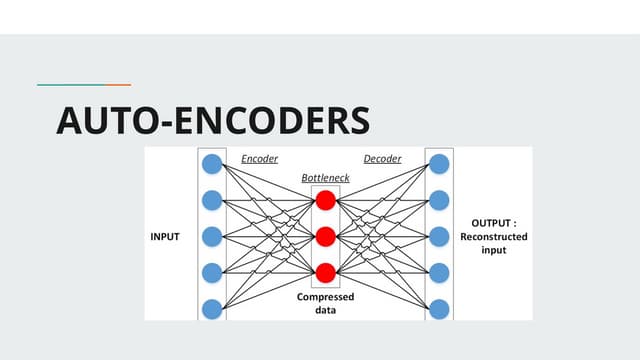
The document discusses autoencoders within deep learning, outlining their purpose to reproduce input data, particularly in image processing. It contrasts autoencoders with traditional methods like PCA and details various types and applications, such as denoising and sparse autoencoders. Key concepts include the structure of autoencoders, their limitations, and training techniques that enhance their performance.