Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hideo Terada
PDF, PPTX
3,563 views
論文紹介 dhSegment:文書セグメンテーションのための包括的ディープラーニングアプローチ
古文書のデジタル化に関して、ディープラーニングによる画像領域分割を適用する試み。FCN型のディープラーニングにより、従来の専用設計の画像処理アルゴリズムに匹敵または凌駕する認識性能を示している。
Software
◦
Related topics:
Deep Learning
•
Neural Networks
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 35
2
/ 35
3
/ 35
4
/ 35
5
/ 35
6
/ 35
7
/ 35
8
/ 35
9
/ 35
10
/ 35
11
/ 35
12
/ 35
13
/ 35
14
/ 35
15
/ 35
16
/ 35
17
/ 35
18
/ 35
19
/ 35
20
/ 35
21
/ 35
22
/ 35
23
/ 35
24
/ 35
25
/ 35
26
/ 35
27
/ 35
28
/ 35
29
/ 35
30
/ 35
31
/ 35
32
/ 35
33
/ 35
34
/ 35
35
/ 35
More Related Content
PPTX
[DL輪読会]Learning by Association - A versatile semi-supervised training method ...
by
Deep Learning JP
PDF
Deep Forest: Towards An Alternative to Deep Neural Networks
by
harmonylab
PPTX
[第2版]Python機械学習プログラミング 第12章
by
Haruki Eguchi
PDF
[第2版]Python機械学習プログラミング 第15章
by
Haruki Eguchi
PPTX
“速度情報を組み込んだロードマップの提案 ”を読んで
by
Adachi (OEI)
PPTX
20160901 jwein
by
tm1966
PPTX
[DL Hacks] Objects as Points
by
Deep Learning JP
PDF
[第2版]Python機械学習プログラミング 第12章
by
Haruki Eguchi
[DL輪読会]Learning by Association - A versatile semi-supervised training method ...
by
Deep Learning JP
Deep Forest: Towards An Alternative to Deep Neural Networks
by
harmonylab
[第2版]Python機械学習プログラミング 第12章
by
Haruki Eguchi
[第2版]Python機械学習プログラミング 第15章
by
Haruki Eguchi
“速度情報を組み込んだロードマップの提案 ”を読んで
by
Adachi (OEI)
20160901 jwein
by
tm1966
[DL Hacks] Objects as Points
by
Deep Learning JP
[第2版]Python機械学習プログラミング 第12章
by
Haruki Eguchi
Similar to 論文紹介 dhSegment:文書セグメンテーションのための包括的ディープラーニングアプローチ
PPTX
[DL輪読会]Deep Face Recognition: A Survey
by
Deep Learning JP
PDF
【2016.07】cvpaper.challenge2016
by
cvpaper. challenge
PDF
研究を加速するChainerファミリー
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
segmentation-modelsでざっくり動かすセマンティックセグメンテーション(U-Net)
by
Haruka Shimojima
PPTX
Densely Connected Convolutional Networks
by
harmonylab
PPTX
【2016.11】cvpaper.challenge2016
by
cvpaper. challenge
PPTX
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東)
by
Tenki Lee
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
PDF
【DL輪読会】HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentat...
by
Deep Learning JP
PDF
PFP:材料探索のための汎用Neural Network Potential_中郷_20220422POLセミナー
by
Matlantis
PDF
semantic segmentation サーベイ
by
yohei okawa
PDF
オープンソースで作るスマホ文字認識アプリ
by
陽平 山口
PDF
セマンティック セグメンテーションで世界を理解する:AIが捉える“意味”のピクセル.pdf
by
Data Source
PPTX
Object Detection & Instance Segmentationの論文紹介 | OHS勉強会#3
by
Toshinori Hanya
PDF
Semantic segmentation2
by
Takuya Minagawa
PDF
Semantic Segmentation Review
by
Takeshi Otsuka
PDF
第13回関西CVPRML勉強会発表資料
by
Yutaka Yamada
PDF
Sprint17 paper summary
by
YusukeSaruya
PDF
DeepLearningDay2016Summer
by
Takayoshi Yamashita
PPTX
Optim インターンシップ 機械学習による画像の領域分割
by
optim_internship
[DL輪読会]Deep Face Recognition: A Survey
by
Deep Learning JP
【2016.07】cvpaper.challenge2016
by
cvpaper. challenge
研究を加速するChainerファミリー
by
Deep Learning Lab(ディープラーニング・ラボ)
segmentation-modelsでざっくり動かすセマンティックセグメンテーション(U-Net)
by
Haruka Shimojima
Densely Connected Convolutional Networks
by
harmonylab
【2016.11】cvpaper.challenge2016
by
cvpaper. challenge
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東)
by
Tenki Lee
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
【DL輪読会】HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentat...
by
Deep Learning JP
PFP:材料探索のための汎用Neural Network Potential_中郷_20220422POLセミナー
by
Matlantis
semantic segmentation サーベイ
by
yohei okawa
オープンソースで作るスマホ文字認識アプリ
by
陽平 山口
セマンティック セグメンテーションで世界を理解する:AIが捉える“意味”のピクセル.pdf
by
Data Source
Object Detection & Instance Segmentationの論文紹介 | OHS勉強会#3
by
Toshinori Hanya
Semantic segmentation2
by
Takuya Minagawa
Semantic Segmentation Review
by
Takeshi Otsuka
第13回関西CVPRML勉強会発表資料
by
Yutaka Yamada
Sprint17 paper summary
by
YusukeSaruya
DeepLearningDay2016Summer
by
Takayoshi Yamashita
Optim インターンシップ 機械学習による画像の領域分割
by
optim_internship
More from Hideo Terada
PPTX
画像処理AIを用いた異常検知
by
Hideo Terada
PDF
ディープラーニングの2値化(Binarized Neural Network)
by
Hideo Terada
PDF
FPGA, AI, エッジコンピューティング
by
Hideo Terada
PDF
2021 09 豆寄席:(公開用)長く生き残るitエンジニアの”リベラル・アーツ”
by
Hideo Terada
PDF
データ中心の時代を生き抜くエンジニアに知ってほしい10?のこと
by
Hideo Terada
PDF
技術系文書作成のコツ
by
Hideo Terada
PDF
機械学習のための数学のおさらい
by
Hideo Terada
PDF
スパースモデリング入門
by
Hideo Terada
PDF
B-DCGAN Slides for ICONIP2019
by
Hideo Terada
画像処理AIを用いた異常検知
by
Hideo Terada
ディープラーニングの2値化(Binarized Neural Network)
by
Hideo Terada
FPGA, AI, エッジコンピューティング
by
Hideo Terada
2021 09 豆寄席:(公開用)長く生き残るitエンジニアの”リベラル・アーツ”
by
Hideo Terada
データ中心の時代を生き抜くエンジニアに知ってほしい10?のこと
by
Hideo Terada
技術系文書作成のコツ
by
Hideo Terada
機械学習のための数学のおさらい
by
Hideo Terada
スパースモデリング入門
by
Hideo Terada
B-DCGAN Slides for ICONIP2019
by
Hideo Terada
論文紹介 dhSegment:文書セグメンテーションのための包括的ディープラーニングアプローチ
1.
論文紹介 dhSegment: 文書セグメンテーションのための、包括的なディープラーニングアプローチ 2019-02-13 作成:寺田英雄(オープンストリーム) https://www.facebook.com/hideo.terada.5
2.
原著 https://arxiv.org/pdf/1804.10371.pdf タイトル: "dhSegment: A
generic deep-learning approach for document segmentation" 2
3.
問題設定 ● やりたいこと ○ ヨーロッパ圏の古文書(歴史的文書)の画像セグメンテーション ○
複数の課題を同時に扱う: ■ ページ抽出 ■ ベースライン抽出 ■ レイアウト分析 ■ イラスト・写真の抽出と分類 ● やりかた ○ 統一のCNNと、課題別の後処理ブロックを使う ○ ピクセル単位のセマンティック・セグメンテーション 3
4.
dhSegment の構造 4
5.
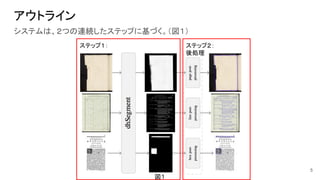
アウトライン システムは、2つの連続したステップに基づく。(図1) 5 図1 ステップ2: 後処理 ステップ1:
6.
アウトライン ● ステップ1: ○ 完全畳み込みニューラルネットワーク(
FCN) ■ 入力:文書の画像; ■ 出力:各ピクセルについて予測された属性の確率のマップ ■ 学習:各ピクセルの属性 IDを示すマスク画像 ● ステップ2:(後処理) ○ 予測マップを各々のタスクの目的の出力に変換 ○ タスクに依存する手作り画像処理を使用(単純・標準的な範囲のアルゴリズムに限定) ● 実装 ○ TensorFlow を使用。GitHubに公開 6
7.
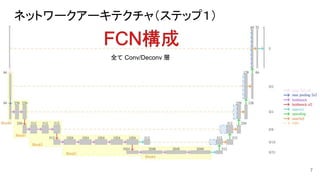
ネットワークアーキテクチャ(ステップ1) 7 全て Conv/Deconv 層
8.
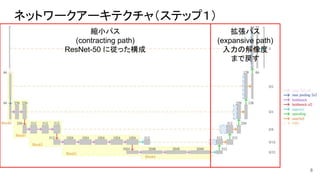
ネットワークアーキテクチャ(ステップ1) 8 縮小パス (contracting path) ResNet-50 に従った構成 拡張パス (expansive
path) 入力の解像度 まで戻す
9.
ネットワークアーキテクチャ(ステップ1) ● 縮小パス ○ ImageNetで事前学習したResNet-50は固定→その他をファインチューニング(転移学習) ○
ResNetにはボトルネック型を使用 ● 拡張パス ○ Deconv層で特徴マップを拡大 ○ アップサンプリングはバイリニア補間 ○ 入力と同じ解像度まで戻す ○ 縮小パスの途中段階の Feature Mapを各々バイパスさせて入力(図 1の点線) ■ →高解像度、中解像度、低解像度の特徴を強調して反映 →局所的特徴と、広域の特徴 を ネットワークに上手く参照させる狙い 9
10.
ステップ2:(後処理) 単純かつ標準的な画像処理だけ使用 ● 2値化 ○ 固定しきい値 ○
大津の方法 ● モルフォロジー ○ 基本演算:膨張(dilation)・収縮(erosion)→開・閉演算子(opening, closing op.) ● 連結成分分析(CCA:Connected Component Analysis) ○ 2値化、モルフォロジーの後に実施 ○ 面積の小さなブロブの除去に使う ● 形状ベクトル化 ○ CCAで抽出した連結画素の外周の多角形の頂点座標(位置ベクトル)列に変換 ○ 面積のない線分も多角形に含む、とする 10
11.
訓練方法 ● ロス関数:L2正則化(weight decay
10-6 )を適用 ● 学習率:指数関数的減衰(0.95)、初期値範囲[10-5 , 10-4 ] ● 重み初期化:Xavier の初期化法 ● 最適化制御:Adam optimizer ● 学習安定化:Batch Normalization 使用 ● 画像のサイズ調整: ○ 総画素数範囲:6x105 〜106 の範囲 ○ さらに300x300サイズにクロップ ○ 『境界効果』を避けるため、マージンを追加 ● データ拡張(Augmentation) ○ on-the-fly での実行 ■ 画像回転:角度範囲: [-0.2, 0.2] (rad.) ■ スケーリング:拡縮比率範囲: [08, 1.2] ■ ミーラリング 11
12.
実験結果 12
13.
実験結果(タスク別) ● タスク: ○ ページ抽出 ○
ベースライン検出 ○ 文書レイアウト解析 ○ オーナメント(装飾) ○ 写真集の抽出 13
14.
ページ抽出 14
15.
ページ抽出 ● 目的:文書画像の背景を除去して、ページ部分だけにする ○ ページ部分に該当する
2値マスク画像を得ること ● 訓練:1635枚の画像、バッチサイズ=1、30エポック ○ 画像は、アスペクト比維持下で、 6x105 画素にリサイズしている。 ● 後処理: ○ (1)ステップ1のネットワーク出力に対し、大津の方法で2値化を実施 →(A) ○ (2)opening-closing を使って、(A)の2値画像の点状のゴミを消去 →(B) ○ (3)2値画像(B)の画素領域を包絡する四辺形を見つける。 ■ =4つのもっとも極端な角を探索する。 15
16.
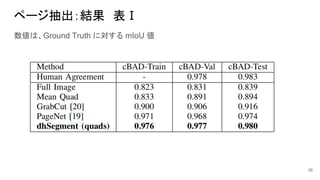
ページ抽出:結果 表Ⅰ 数値は、Ground Truth に対する
mIoU 値 16
17.
ページ抽出:結果 図3 画像例 17 緑色:Ground Truth、青色:dhSegment
の検出結果 (データ: cBADテストセット) 不正確 わずかに不正確 正確
18.
ベースライン検出 18
19.
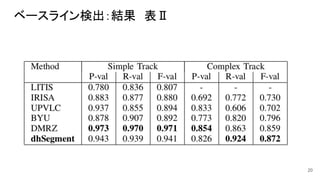
ベースライン検出 ● 目的:ベースラインの検出 ○ ベースラインとは? ■
画像上の仮想的な線分で、その上にほとんどの文字が乗っており、またディセンダ分がその 下に拡張されるもの。 ■ ※ディセンダ=アルファベットの小文字表記において「 g」のように下に伸びた部分 ● 検出方法 ○ ネットワークは、ベースラインから半径5ピクセル以内にある画素を予測するように訓練する(訓練 データをそのように与える) ● 訓練:画像は106 サイズにリサイズ、30エポック、約50分 19
20.
ベースライン検出:結果 表Ⅱ 20
21.
文書レイアウト解析 21
22.
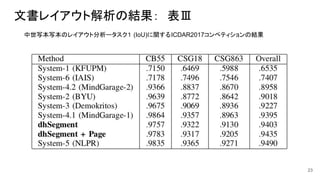
文書レイアウト解析 ● 目的:文書画像を意味のある領域に分割(画素ラベリング)すること ○ 分割クラス:テキスト、装飾、コメントと背景、およびそれらの複合(例:テキスト領域かつ装飾) ●
訓練:3つの文書群(文書内訳:30の訓練画像、10の評価画像、10のテスト画像) ○ 各文書群ごとに独立にモデルを訓練、30エポック ○ 画像リサイズなし、バッチ学習のためのクロッピングは実施 ○ バッチサイズ=8、画像サイズ 400x400(一部はバッチサイズ=4、 600x600) ○ 学習時間:2〜4時間 ● 後処理: ○ ラベリング結果の各クラスごとに 2値マスクを作成、面積 50ピクセル未満の小ブロブを除去 ○ 前述のページ抽出の結果を利用して、画像の境界上のテキスト検出の FPを減らす 22
23.
文書レイアウト解析の結果: 表Ⅲ 23 中世写本写本のレイアウト分析ータスク1 (IoU)に関するICDAR2017コンペティションの結果
24.
文書レイアウト解析の結果: 図5 24 左側はオリジナルの原稿画像、中央は、 dhSegmentでピクセル単位でラベル付けされたクラス、そして 右側は、Ground Truth
との比較(色の意味の評価ツールによる)
25.
オーナメント(装飾)検出 25
26.
オーナメント検出 ● 目的:文書画像から、オーナメント(装飾部分)を検出する ● 訓練: ○
データ: ■ オーナメントを矩形でアノーテーションした訓練データ。計 912ページ分の アノテーションつき画像、うち 612ページに1個以上のオーナメントが含まれる。 ● 訓練用610ページ(オーナメントつき 427ページ) ● 評価用92ページ(同上 92ページ) ● テスト用183ページ(同上 123ページ) ● 画像サイズ:8x105 にリサイズ ○ 学習:バッチサイズ= 16、30エポック、2時間未満 ● 後処理: ○ 2値化により、バイナリマスク画像を生成 ○ モルフォロジー開閉 (Opening/Closing)処理 ○ バウンディングボックスのあてはめ ○ 極小のボックスは除去(画像サイズ比 0.5%未満のもの) 26
27.
オーナメント検出の結果: 表Ⅳ 27 オーナメント検出タスクの結果。参考文献 [23]の方法によるもの。 それぞれのテストセットについて、異なる IoU閾値により評価した。
28.
オーナメント検出の結果: 図6 28 左の画像は部分的に検出された装飾の場合を示し、中央のものはイラストの検出を示していますがバナーの誤検出も示して います。右の画像は複数の装飾の抽出の正しい例です。
29.
写真集(フォトコレクション)抽出 29
30.
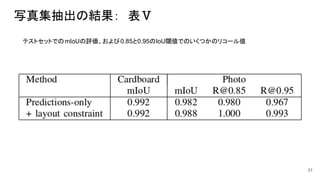
写真集抽出 ● 目的: ○ カードボード(厚紙)台紙に貼り付けられた写真の画像について、写真部分と、厚紙部分、背景部分 の3クラスに分離(領域分割)する ●
訓練: ○ 上記の3クラスに応じて画像を3色に色分け注釈したものを教師データとして訓練。 ○ モデルは、各ピクセルの所属クラスを予測する。 ○ 訓練用データ:100個 ○ 評価用データ:20個 ○ テスト用データ:150個 ○ 40エポックの訓練、所要時間: 20分 ● 後処理: ○ 予測クラス画素のモルフォロジーオープニング。 ○ 連結領域の最小の包絡矩形を抽出。 Prior制約:厚紙は写真の外側でなければならない。 ○ 得られた矩形をGround Truthと比較 30
31.
写真集抽出の結果: 表Ⅴ 31 テストセットでのmIoUの評価、および0.85と0.95のIoU閾値でのいくつかのリコール値
32.
写真群抽出の結果: 図7 32 オーナメントの場合とは反対に、抽出されるゾーンはより明確に定義されているため、 より正確な抽出が可能となっている。
33.
ディスカッション 33
34.
ディスカッション ● 同一ネットワーク、ほぼ同じトレーニング構成を使用しながら、5つのタスクの結果 は、SOTA(最先端性能)と競争力があるか又は凌駕している ● 一般的で柔軟性のあるアプローチにもかかわらず、トレーニングのスピードは速く (場合によっては1時間未満)、必要なトレーニングデータ量も少ない ○
→ネットワークの事前トレーニング済みの部分のおかげ ● 一般化されたディープラーニング型アプローチが、従来の個別専用システムより優 れていることによる帰結: ○ 非専門家でも訓練できる ○ この機能のプログラミングモジュール化が可能 →ビジュアルプログラミング等に対応 ● 本論文では、タスクごとに別々に学習したが、複数のタスクを一つのネットワークで 同時に学習させたほうが、性能が向上する可能性があり、今後の研究課題であ る。 34
35.
以上 35
Download







![訓練方法
● ロス関数:L2正則化(weight decay 10-6
)を適用
● 学習率:指数関数的減衰(0.95)、初期値範囲[10-5
, 10-4
]
● 重み初期化:Xavier の初期化法
● 最適化制御:Adam optimizer
● 学習安定化:Batch Normalization 使用
● 画像のサイズ調整:
○ 総画素数範囲:6x105
〜106
の範囲
○ さらに300x300サイズにクロップ
○ 『境界効果』を避けるため、マージンを追加
● データ拡張(Augmentation)
○ on-the-fly での実行
■ 画像回転:角度範囲: [-0.2, 0.2] (rad.)
■ スケーリング:拡縮比率範囲: [08, 1.2]
■ ミーラリング
11](https://image.slidesharecdn.com/slidedhsegment-190218064341/85/dhSegment-11-320.jpg)












![オーナメント検出の結果: 表Ⅳ
27
オーナメント検出タスクの結果。参考文献 [23]の方法によるもの。
それぞれのテストセットについて、異なる IoU閾値により評価した。](https://image.slidesharecdn.com/slidedhsegment-190218064341/85/dhSegment-27-320.jpg)








![[DL輪読会]Learning by Association - A versatile semi-supervised training method ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl-170613062403-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第2版]Python機械学習プログラミング 第12章](https://cdn.slidesharecdn.com/ss_thumbnails/12-181212011918-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第2版]Python機械学習プログラミング 第15章](https://cdn.slidesharecdn.com/ss_thumbnails/15-190318023254-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL Hacks] Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/centernetpub-190627053219-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第2版]Python機械学習プログラミング 第12章](https://cdn.slidesharecdn.com/ss_thumbnails/12-190318023252-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Face Recognition: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/20181221-181221023935-thumbnail.jpg?width=640&height=640&fit=bounds)



























