Download to read offline









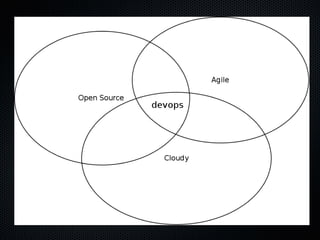
































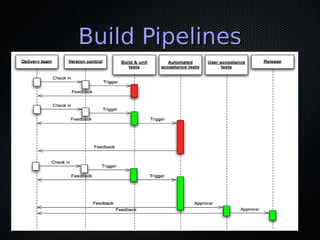
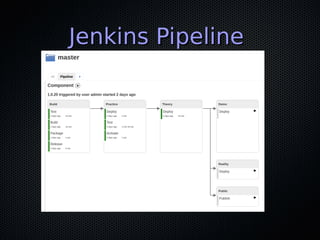




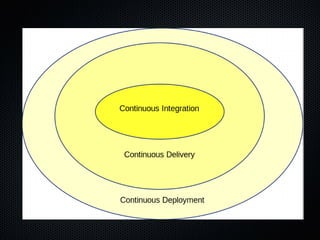











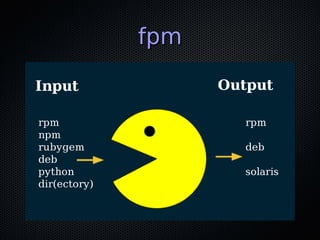



















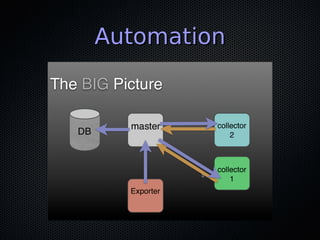





















This document discusses DevOps and continuous delivery. It defines DevOps as a cultural and professional movement to improve software delivery through automation, measurement, and collaboration between development and operations teams. The key aspects of DevOps discussed are adopting infrastructure as code practices, implementing continuous integration and deployment pipelines, and establishing a culture of automation, measurement, and sharing between teams. The overall goal is to enable software to be delivered safely and reliably in a matter of hours through establishing these collaborative practices.


















































































