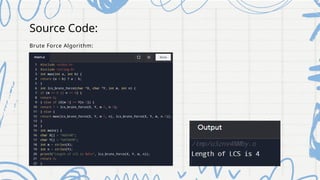
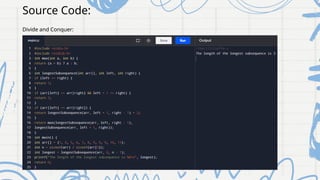
The document presents an analysis of the Longest Common Subsequence (LCS) problem, which aims to identify the longest subsequence common to two sequences. It discusses various algorithmic approaches including brute force, divide and conquer, and dynamic programming, detailing their time and space complexities along with their applications in fields like bioinformatics and text comparison. The goal is to develop an efficient, user-friendly algorithm that is scalable and applicable in multiple domains.







![Pseudocode
Dynamic Programming:
def Ics(string1, string2):
if len (string1) == 0 or len(string2) == 0:
return ""
elif string1[-1] == string2[-1]:
return Ics(string1[:-1], string2[:-1]) + string1[-1]
else:
Ics1 = Ics(string1[:-1], string2)
Ics2 = Ics(string1, string2[:-1])
if len (Ics1) > len(Ics2):
return Ics1
else: return Ics2
Divide and Conquer:
def Ics(string1, string2):
m = len(string1)
n = len(string2)
# initialize table with zeros
table = [[0]*(n+1) for i in range(m+1)]
for i in range(1, m+1):
for j in range(1, n+1):
if string1[i-1] == string2[j-1]:
table[i][j] = table[i-1][j-1]+1
else:
table[i][j] = max(table[i-1][j], table[i][j-1])
#backtrack to find LCS
Ics = ""
while i > 0 and j > 0:
i = m
j = n
if string1 [i-1] == string2[j-1]:
Ics = string1 [i-1] + Ics i-=1
elif table[i-1][j] > table[i][j-1]: i-1
else: j-=1
j-=1
return Ics
Brute Force:
def Ics(string1, string2):
if len(string1) == 0 or len(string2) == 0:
return ""
elif string1[-1] == string2[-1]:
return Ics(string1[:-1], string2[:-1]) +
string1[-1]
else:](https://image.slidesharecdn.com/daappt-240906175138-7930127b/85/design-and-analysis-of-algorithm-Longest-common-subsequence-8-320.jpg)