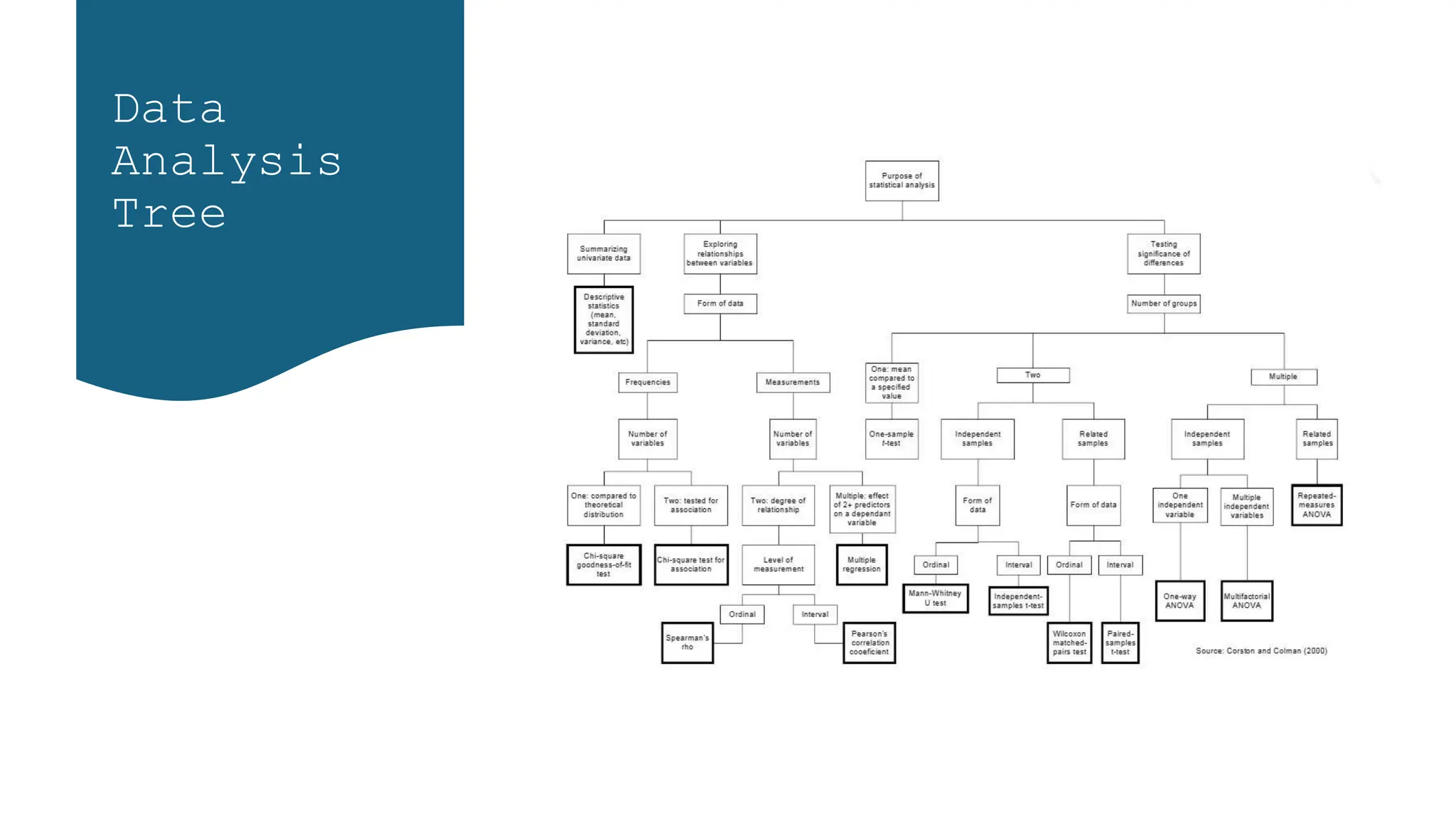
The document provides an overview of statistics and its significance in data analytics, touching upon the fundamentals of statistical analysis, different types of data, and their applications in various fields. It discusses categorical and numerical data, including their characteristics, measurement levels, and appropriate statistical methods for analysis. Additionally, it includes practical examples and Python code snippets for data analysis techniques such as correlation, linear regression, and hypothesis testing.






![Some examples
• Frequency Counts and Mode (typical starting stats for
categ)
import pandas as pd
# Sample nominal data
data = {'Color': ['Red', 'Blue', 'Green',
'Blue', 'Red', 'Green', 'Red']}
df = pd.DataFrame(data)
# Frequency counts
frequency_counts = df['Color'].value_counts()
print(frequency_counts)
# Mode
mode = df['Color'].mode()
print(f'Mode: {mode[0]}')](https://image.slidesharecdn.com/lecture1statistics-240720000123-cd2e0a68/75/Descriptive-Statistics-Basic-Ideas-PPTX-8-2048.jpg)
![Chi-Square
Test
The chi-square test is used to determine if there is a significant association between two nominal variables.
import pandas as pd
from scipy.stats import chi2_contingency
# Sample nominal data
data = {'Gender': ['Male', 'Female', 'Female', 'Male', 'Female', 'Male', 'Male'],
'Preference': ['Yes', 'No', 'Yes', 'Yes', 'No', 'No', 'Yes']}
df = pd.DataFrame(data)
# Contingency table
contingency_table = pd.crosstab(df['Gender'], df['Preference'])
print(contingency_table)
# Chi-square test
chi2, p, dof, ex = chi2_contingency(contingency_table)
print(f'Chi-square: {chi2}, p-value: {p}')](https://image.slidesharecdn.com/lecture1statistics-240720000123-cd2e0a68/75/Descriptive-Statistics-Basic-Ideas-PPTX-9-2048.jpg)
![Median
and
Interqua
rtile
Range
(IQR)
import pandas as pd
# Sample ordinal data
data = {'Satisfaction': [3, 1,
4, 2, 5, 3, 4, 2, 1, 5]}
df = pd.DataFrame(data)
# Median
median =
df['Satisfaction'].median()
print(f'Median: {median}')
# Interquartile Range (IQR)
iqr =
df['Satisfaction'].quantile(0.
75) -
df['Satisfaction'].quantile(0.
25)
print(f'IQR: {iqr}')](https://image.slidesharecdn.com/lecture1statistics-240720000123-cd2e0a68/75/Descriptive-Statistics-Basic-Ideas-PPTX-10-2048.jpg)


![Some examples
• Mean and Standard Deviation
import numpy as np
# Sample interval data (e.g.,
temperatures in Celsius)
temperatures = [23, 25, 22, 20, 26,
21, 24, 27, 23, 22]
# Mean
mean_temp = np.mean(temperatures)
print(f'Mean Temperature:
{mean_temp}')
# Standard Deviation
std_dev_temp = np.std(temperatures)
print(f'Standard Deviation of
Temperature: {std_dev_temp}')](https://image.slidesharecdn.com/lecture1statistics-240720000123-cd2e0a68/75/Descriptive-Statistics-Basic-Ideas-PPTX-13-2048.jpg)
![Correlation and
Linear
Regression
• import numpy as np
• import matplotlib.pyplot
as plt
• from scipy.stats import
linregress
• # Sample interval data
(e.g., temperatures and
ice cream sales)
• temperatures = [23, 25,
22, 20, 26, 21, 24, 27,
23, 22]
• ice_cream_sales = [150,
160, 140, 130, 170, 135,
155, 180, 150, 140]
• # Correlation
• correlation =
np.corrcoef(temperatures,
ice_cream_sales)[0, 1]
• print(f'Correlation:
{correlation}')](https://image.slidesharecdn.com/lecture1statistics-240720000123-cd2e0a68/75/Descriptive-Statistics-Basic-Ideas-PPTX-14-2048.jpg)

![Independent T-
Test (Typical
A/B Testing)
• import numpy as np
• from scipy.stats import ttest_ind
• # Sample ratio data (e.g., weights in kg
for two groups)
• group_a_weights = [70, 75, 80, 85, 90,
95, 100]
• group_b_weights = [60, 65, 70, 75, 80,
85, 90]
• # Independent T-Test
• t_stat, p_value =
ttest_ind(group_a_weights,
group_b_weights)
• print(f'T-statistic: {t_stat}, p-value:
{p_value}')](https://image.slidesharecdn.com/lecture1statistics-240720000123-cd2e0a68/75/Descriptive-Statistics-Basic-Ideas-PPTX-16-2048.jpg)
![Geometric Mean
and Coefficient
of Variation
• import numpy as np
• from scipy.stats import gmean
• # Sample ratio data (e.g., heights in
centimeters)
• heights = [150, 160, 170, 180, 190, 200,
210]
• # Geometric Mean
• geom_mean_height = gmean(heights)
• print(f'Geometric Mean of Heights:
{geom_mean_height}')
• # Coefficient of Variation
• mean_height = np.mean(heights)
• std_dev_height = np.std(heights)
• coef_var_height = (std_dev_height /
mean_height) * 100
• print(f'Coefficient of Variation:
{coef_var_height}%')](https://image.slidesharecdn.com/lecture1statistics-240720000123-cd2e0a68/75/Descriptive-Statistics-Basic-Ideas-PPTX-17-2048.jpg)