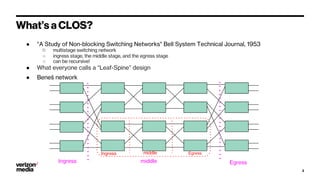
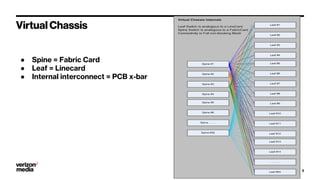
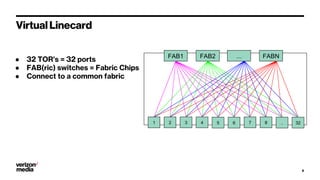
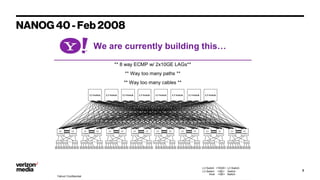
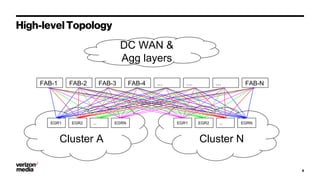
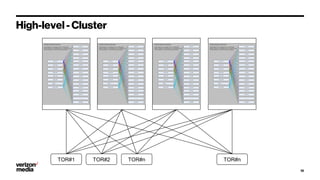
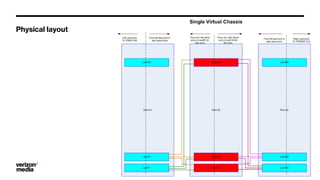
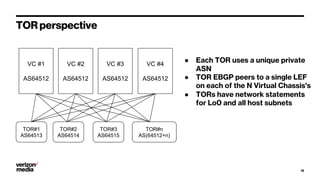
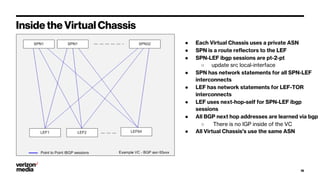
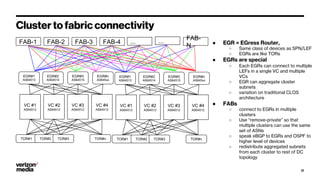
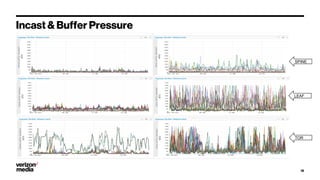
Demystifying Data Center CLOS networks provides an overview of Yahoo's data center fabric from 2012 to 2018. It discusses CLOS network topologies including leaf-spine designs and different CLOS variations used. The document details Yahoo's multidimensional folded CLOS fabric with 25G connections to servers, 100G core links, and BGP routing. It also covers scaling the fabric design to support thousands of nodes, automation of provisioning and operations, and lessons learned on stability, failures, and buffer management.