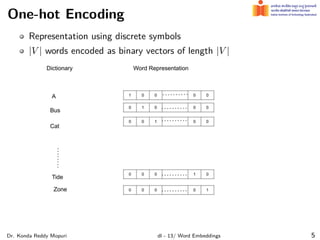
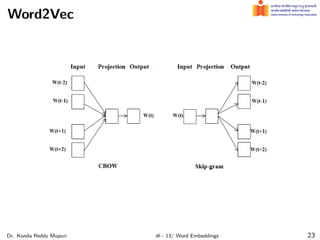
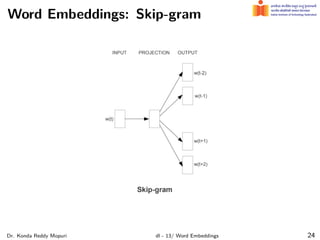
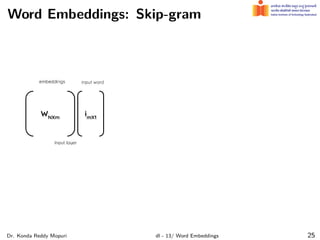
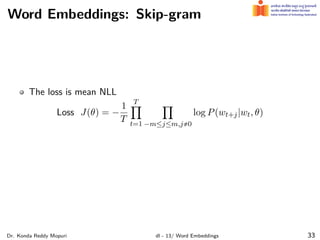
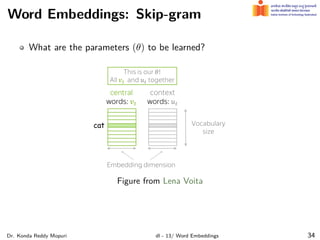
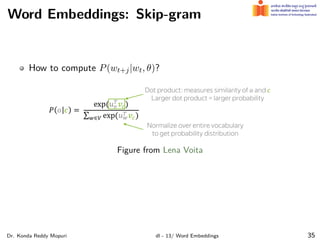
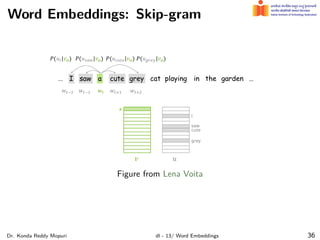
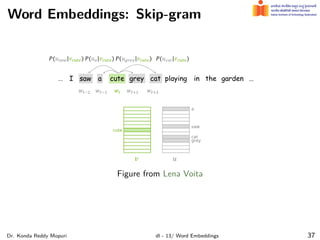
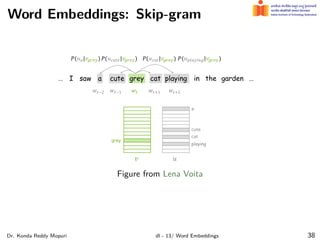
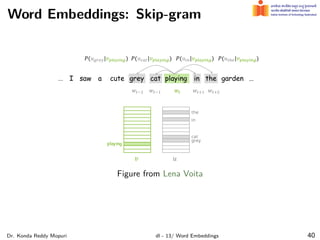
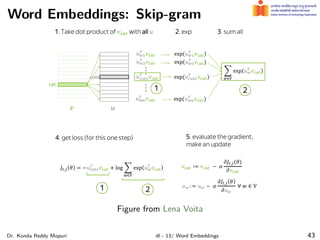
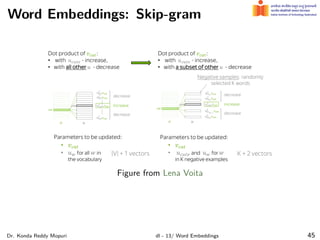
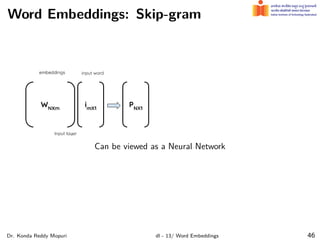
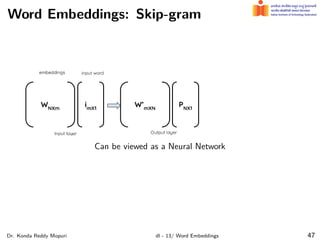
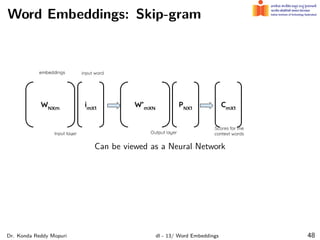
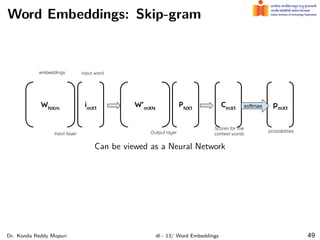
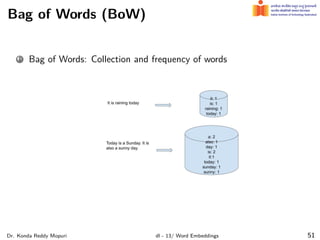
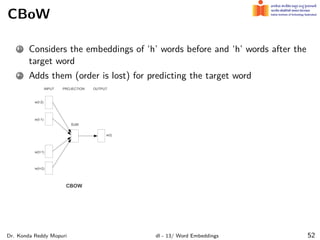
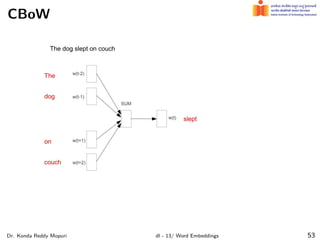
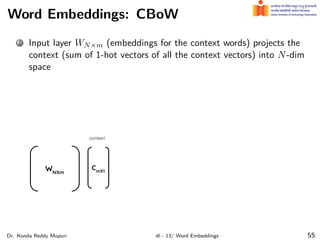
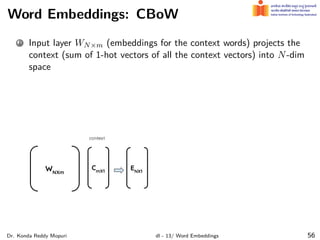
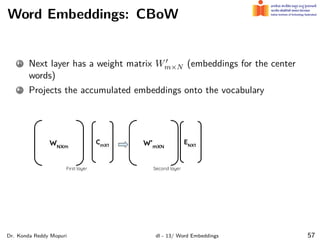
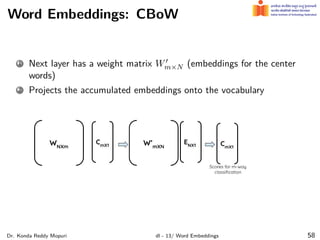
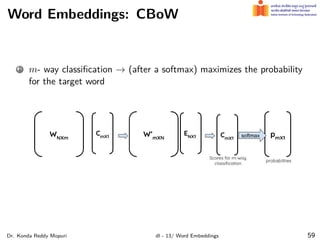
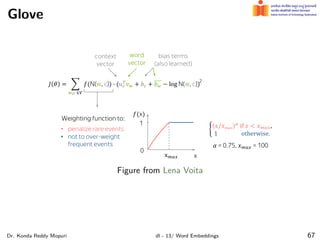
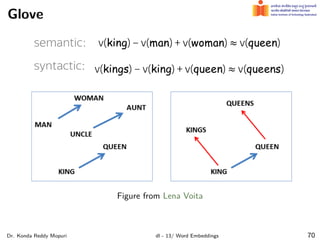
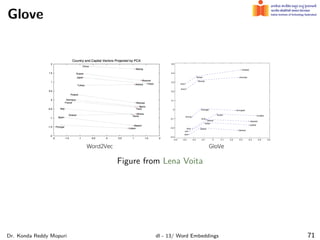
The document discusses word embeddings and their significance in deep learning, highlighting the limitations of one-hot encoding in representing word semantics. It describes the distributional hypothesis and introduces techniques such as co-occurrence matrices and dimensionality reduction using SVD. Furthermore, it covers prediction-based models like Word2Vec, including CBOW and skip-gram models, and their training processes to capture word meanings based on context.












































































































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)
