Downloaded 352 times








![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
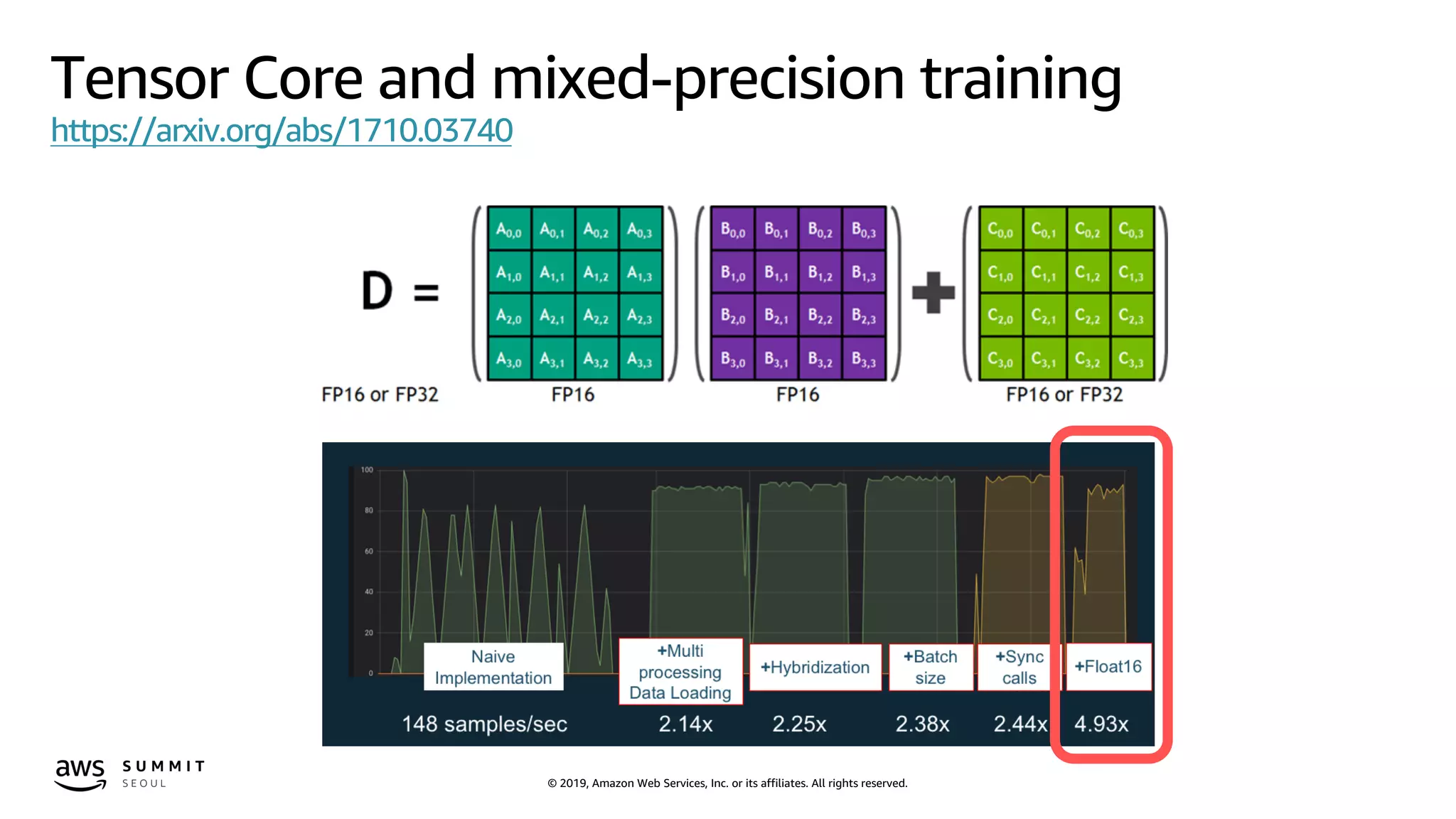
Code snip for mix-precision training in TensorFlow
x = tf.placeholder(tf.float32, [None, 784])
W1 = tf.Variable(tf.truncated_normal([784, FLAGS.num_hunits]))
b1 = tf.Variable(tf.zeros([FLAGS.num_hunits]))
z = tf.nn.relu(tf.matmul(x, W1) + b1)
W2 = tf.Variable(tf.truncated_normal([FLAGS.num_hunits, 10]))
b2 = tf.Variable(tf.zeros([10]))
y = tf.matmul(z, W2) + b2
y_ = tf.placeholder(tf.int64, [None])
cross_entropy = tf.losses.sparse_softmax_cross_entropy(labels=y_,
logits=y)
train_step =
tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
data = tf.placeholder(tf.float16, shape=(None, 784))
W1 = tf.get_variable('w1', (784, FLAGS.num_hunits), tf.float16)
b1 = tf.get_variable('b1', (FLAGS.num_hunits), tf.float16,
initializer=tf.zeros_initializer())
z = tf.nn.relu(tf.matmul(data, W1) + b1)
W2 = tf.get_variable('w2', (FLAGS.num_hunits, 10), tf.float16)
b2 = tf.get_variable('b2', (10), tf.float16,
initializer=tf.zeros_initializer())
y = tf.matmul(z, W2) + b2
y_ = tf.placeholder(tf.int64, shape=(None))
loss = tf.losses.sparse_softmax_cross_entropy(y_,
tf.cast(y, tf.float32))
* Source code from https://github.com/khcs/fp16-demo-tf
MLP normal implementation MLP mixed-precision implementation](https://image.slidesharecdn.com/day2track2session2-190419034559/75/Deep-Learning-AWS-AWS-Summit-Seoul-2019-13-2048.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Code snip for mix-precision training in TensorFlow
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
# Train
for _ in range(3000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
def gradients_with_loss_scaling(loss, variables, loss_scale):
return [grad / loss_scale
for grad in tf.gradients(loss * loss_scale, variables)]
with tf.device('/gpu:0'),
tf.variable_scope(
'fp32_storage', custom_getter=float32_variable_storage_getter):
data, target, logits, loss = create_model(nbatch, nin, nout, dtype)
variables = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
grads = gradients_with_loss_scaling(loss, variables, loss_scale)
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum)
training_step_op = optimizer.apply_gradients(zip(grads, variables))
init_op = tf.global_variables_initializer()
sess.run(init_op)
for step in range(6000):
batch_xs, batch_ys = mnist.train.next_batch(100)
np_loss, _ = sess.run([loss, training_step_op],
feed_dict={data: batch_xs, target: batch_ys})* Source code from https://github.com/khcs/fp16-demo-tf
MLP normal implementation MLP mixed-precision implementation](https://image.slidesharecdn.com/day2track2session2-190419034559/75/Deep-Learning-AWS-AWS-Summit-Seoul-2019-14-2048.jpg)






![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Using Horovod with TensorFlow
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per
process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other
processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# Save checkpoints only on worker 0 to prevent other workers
from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# The MonitoredTrainingSession takes care of session
initialization,
# restoring from a checkpoint, saving to a checkpoint, and
closing when done
# or an error occurs.
with
tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/day2track2session2-190419034559/75/Deep-Learning-AWS-AWS-Summit-Seoul-2019-23-2048.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Using Horovod with Apache MXNet
import mxnet as mx
import horovod.mxnet as hvd
from mxnet import autograd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank
context = mx.gpu(hvd.local_rank())
num_workers = hvd.size()
# Build model
model = ...
model.hybridize()
# Create optimizer
optimizer_params = ...
opt = mx.optimizer.create('sgd', **optimizer_params)
# Initialize parameters
model.initialize(initializer, ctx=context)
# Fetch and broadcast parameters
params = model.collect_params()
if params is not None:
hvd.broadcast_parameters(params, root_rank=0)
# Create DistributedTrainer, a subclass of gluon.Trainer
trainer = hvd.DistributedTrainer(params, opt)
# Create loss function
loss_fn = ...
# Train model
for epoch in range(num_epoch):
train_data.reset()
for nbatch, batch in enumerate(train_data, start=1):
data = batch.data[0].as_in_context(context)
label = batch.label[0].as_in_context(context)
with autograd.record():
output = model(data.astype(dtype, copy=False))
loss = loss_fn(output, label)
loss.backward()
trainer.step(batch_size)
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/day2track2session2-190419034559/75/Deep-Learning-AWS-AWS-Summit-Seoul-2019-24-2048.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Using Horovod with Keras
import keras
import horovod.keras as hvd
# Horovod: initialize Horovod.
hvd.init()
# Horovod: pin GPU to be used to process local rank (one GPU
per process)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Horovod: adjust number of epochs based on number of GPUs.
epochs = int(math.ceil(12.0 / hvd.size()))
model = ...
# Horovod: adjust learning rate based on number of GPUs.
opt = keras.optimizers.Adadelta(1.0 * hvd.size())
# Horovod: add Horovod Distributed Optimizer.
opt = hvd.DistributedOptimizer(opt)
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=opt, metrics=['accuracy'])))
callbacks = [
# Horovod: broadcast initial variable states from rank 0 to
all other processes.
# This is necessary to ensure consistent initialization of
all workers when
# training is started with random weights or restored from a
checkpoint.
hvd.callbacks.BroadcastGlobalVariablesCallback(0),
]
# Horovod: save checkpoints only on worker 0 to prevent other
workers from corrupting them.
if hvd.rank() == 0:
callbacks.append(keras.callbacks.ModelCheckpoint(
'./checkpoint-{epoch}.h5'))
model.fit(x_train, y_train,
batch_size=batch_size,
callbacks=callbacks,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/day2track2session2-190419034559/75/Deep-Learning-AWS-AWS-Summit-Seoul-2019-25-2048.jpg)


![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Using Horovod in Amazon SageMaker
from sagemaker.tensorflow import TensorFlow
distributions = {'mpi': {'enabled': True, "processes_per_host": 2}}
# METHOD 1 - Using Amazon SageMaker provided VPC
estimator = TensorFlow(entry_point=train_script,
role=sagemaker_iam_role,
train_instance_count=2,
train_instance_type='ml.p3.8xlarge',
script_mode=True,
framework_version='1.12',
distributions=distributions)
# METHOD 2 - Using your own VPC for training performance improvement
estimator = TensorFlow(entry_point=train_script,
role=sagemaker_iam_role,
train_instance_count=2,
train_instance_type='ml.p3.8xlarge',
script_mode=True,
framework_version='1.12',
distributions=distributions,
security_group_ids=['sg-0919a36a89a15222f'],
subnets=['subnet-0c07198f3eb022ede', 'subnet-055b2819caae2fd1f’])
estimator.fit({"train":s3_train_path, "test":s3_test_path})](https://image.slidesharecdn.com/day2track2session2-190419034559/75/Deep-Learning-AWS-AWS-Summit-Seoul-2019-28-2048.jpg)







![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
How to compile a model
https://docs.aws.amazon.com/sagemaker/latest/dg/neo-job-compilation-cli.html
Configure the compilation job
{
"RoleArn":$ROLE_ARN,
"InputConfig": {
"S3Uri":"s3://jsimon-neo/model.tar.gz",
"DataInputConfig": "{"data": [1, 3, 224, 224]}",
"Framework": "MXNET"
},
"OutputConfig": {
"S3OutputLocation": "s3://jsimon-neo/",
"TargetDevice": "rasp3b"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 300
}
}
Compile the model
$ aws sagemaker create-compilation-job
--cli-input-json file://config.json
--compilation-job-name resnet50-mxnet-pi
$ aws s3 cp s3://jsimon-neo/model-
rasp3b.tar.gz .
$ gtar tfz model-rasp3b.tar.gz
compiled.params
compiled_model.json
compiled.so
Predict with the compiled model
from dlr import DLRModel
model = DLRModel('resnet50', input_shape,
output_shape, device)
out = model.run(input_data)](https://image.slidesharecdn.com/day2track2session2-190419034559/75/Deep-Learning-AWS-AWS-Summit-Seoul-2019-38-2048.jpg)






![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Using Elastic Inference with Apache MXNet
OPTION 1 - Use EI with the MXNet Symbol API
import mxnet as mx
data = mx.sym.var('data', shape=(1,))
sym = mx.sym.exp(data)
# Pass mx.eia() as context during simple bind operation
executor = sym.simple_bind(ctx=mx.eia(), grad_req='null')
# Forward call is performed on remote accelerator
executor.forward(data=mx.nd.ones((1,)))
print('Inference %d, output = %s' % (i, executor.outputs[0]))
OPTION 2 - Use EI with the Module API
ctx = mx.eia()
sym, arg_params, aux_params = mx.model.load_checkpoint('resnet-152', 0)
mod = mx.mod.Module(symbol=sym, context=ctx, label_names=None)](https://image.slidesharecdn.com/day2track2session2-190419034559/75/Deep-Learning-AWS-AWS-Summit-Seoul-2019-50-2048.jpg)




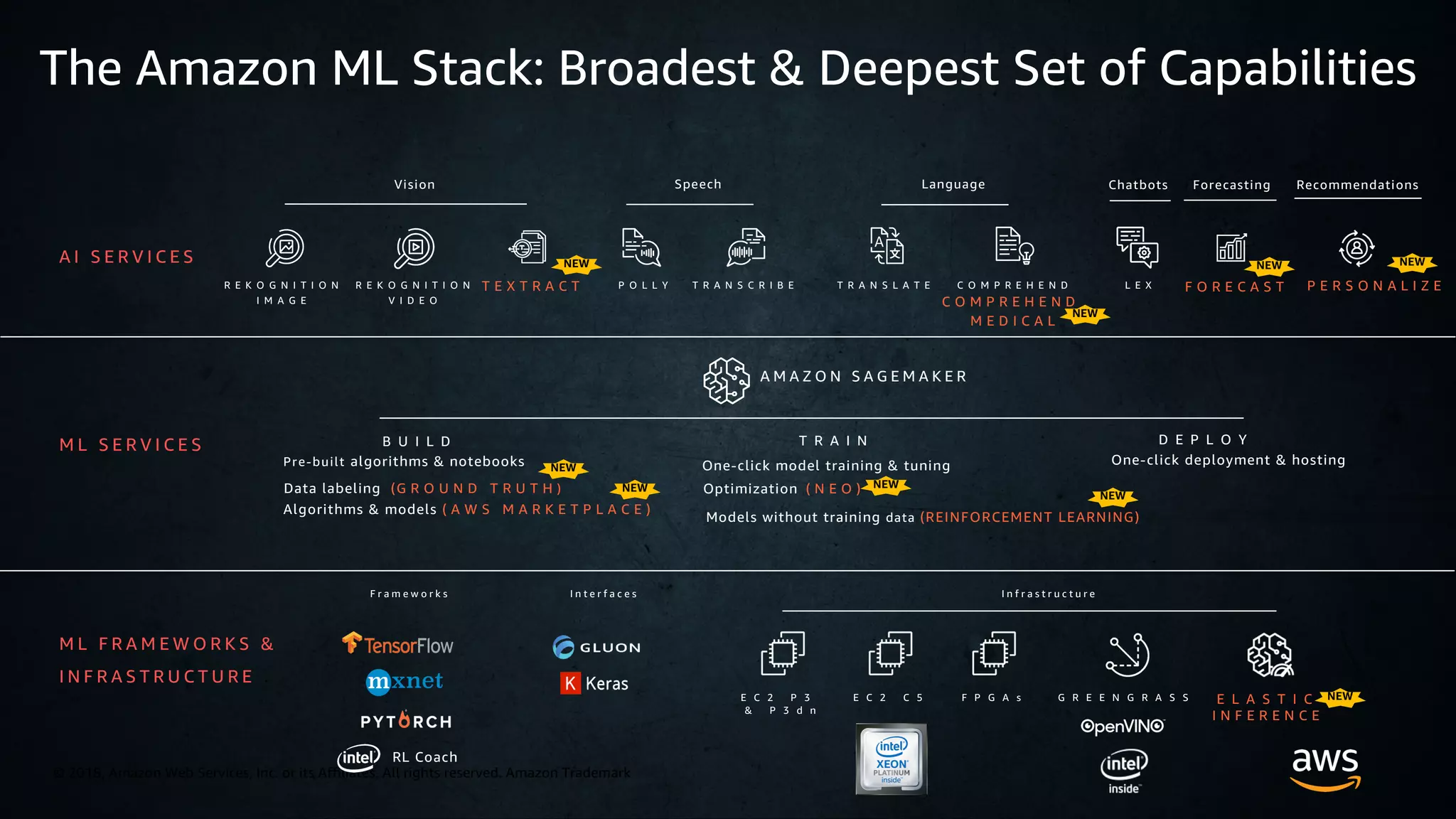
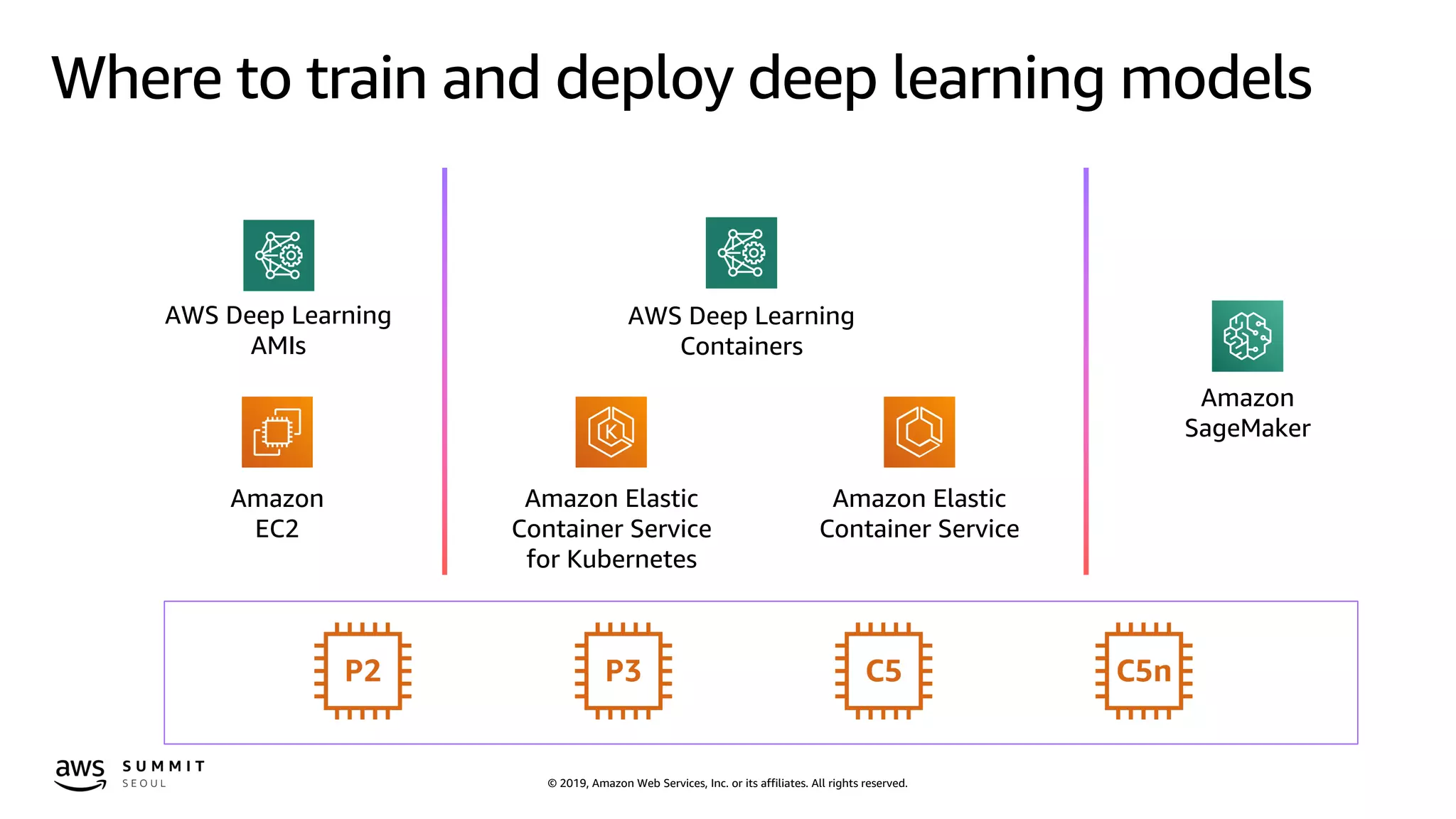
The document discusses effective distributed training and optimization methods for deep learning models, focusing on frameworks like TensorFlow, MXNet, Keras, and PyTorch. It highlights the Amazon ML Solutions Lab, which provides resources and expertise for developers, and details the use of AWS services such as SageMaker and EC2 for accelerated training. Key features include mixed-precision training, the use of Horovod for distributed training, and strategies for scaling with multiple GPUs and instances.














![[AWS Start-up ゼミ / DevDay 編] よくある課題を一気に解説! 御社の技術レベルがアップする 2018 秋期講習](https://cdn.slidesharecdn.com/ss_thumbnails/awsdevdaytokyo2018startupzemi-181127063525-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWS Dev Day] 인공지능 / 기계 학습 | Intel on AWS, AI/ML Service 성능 향상을 위한 협력 모델 - 서...](https://cdn.slidesharecdn.com/ss_thumbnails/awsdevdayseoul2019intelonawsaimlservice-190930015001-thumbnail.jpg?width=640&height=640&fit=bounds)








![[AWS Container Service] Getting Started with Kubernetes on AWS](https://cdn.slidesharecdn.com/ss_thumbnails/200gettingstartedwithkubernetesonaws-190326085832-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWS Dev Day] 인공지능 / 기계 학습 | AWS 기반 기계 학습 자동화 및 최적화를 위한 실전 기법 - 남궁영환 AWS 솔루션...](https://cdn.slidesharecdn.com/ss_thumbnails/20190926-devday-aiml3-younghwan-final-190930020120-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)











![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











