登壇者紹介
田中 孝佳 (@tanaka_733)
NewRelic K.K. Lead Technical Support Engineer
好きな言語はC#。C# Tokyoコミュニティの運営メンバー
OpenTelemetry .NETハンズオンなどを開催
Microsoft MVP for Azure, Development Technologies
Microsoft Certified Cloud Solution Architect Expert
Certified Kubernetes Administrator/Application Developer(CKA/CKAD)
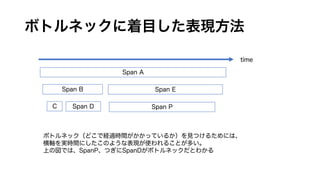
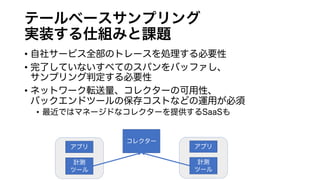
ボトルネックに着目した表現方法
time
Span A
Span B
CSpan D
Span E
Span P
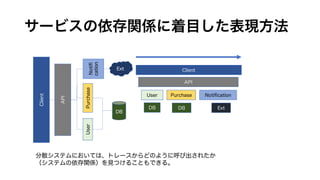
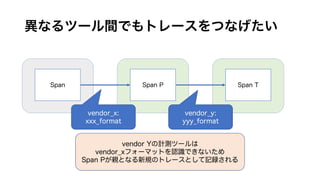
ボトルネック(どこで経過時間がかかっているか)を見つけるためには、
横軸を実時間にしたこのような表現が使われることが多い。
上の図では、SpanP、つぎにSpanDがボトルネックだとわかる